 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoparsing: Diagram Parsing for Plane and Solid Geometry with a Unified Formal Language
Apr 13, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable progress but continue to struggle with geometric reasoning, primarily due to the perception bottleneck regarding fine-grained visual elements. While formal languages have aided plane geometry understanding, solid geometry which requires spatial understanding remains largely unexplored. In this paper, we address this challenge by designing a unified formal language that integrates plane and solid geometry, comprehensively covering geometric structures and semantic relations. We construct GDP-29K, a large-scale dataset comprising 20k plane and 9k solid geometry samples collected from diverse real-world sources, each paired with its ground-truth formal description. To ensure syntactic correctness and geometric consistency, we propose a training paradigm that combines Supervised Fine-Tuning with Reinforcement Learning via Verifiable Rewards. Experiments show that our approach achieves state-of-the-art parsing performance. Furthermore, we demonstrate that our parsed formal descriptions serve as a critical cognitive scaffold, significantly boosting MLLMs' capabilities for downstream geometry reasoning tasks. Our data and code are available at Geoparsing.
Hackers or Hallucinators? A Comprehensive Analysis of LLM-Based Automated Penetration Testing
Apr 07, 2026The rapid advancement of Large Language Models (LLMs) has created new opportunities for Automated Penetration Testing (AutoPT), spawning numerous frameworks aimed at achieving end-to-end autonomous attacks. However, despite the proliferation of related studies, existing research generally lacks systematic architectural analysis and large-scale empirical comparisons under a unified benchmark. Therefore, this paper presents the first Systematization of Knowledge (SoK) focusing on the architectural design and comprehensive empirical evaluation of current LLM-based AutoPT frameworks. At systematization level, we comprehensively review existing framework designs across six dimensions: agent architecture, agent plan, agent memory, agent execution, external knowledge, and benchmarks. At empirical level, we conduct large-scale experiments on 13 representative open-source AutoPT frameworks and 2 baseline frameworks utilizing a unified benchmark. The experiments consumed over 10 billion tokens in total and generated more than 1,500 execution logs, which were manually reviewed and analyzed over four months by a panel of more than 15 researchers with expertise in cybersecurity. By investigating the latest progress in this rapidly developing field, we provide researchers with a structured taxonomy to understand existing LLM-based AutoPT frameworks and a large-scale empirical benchmark, along with promising directions for future research.
Text Before Vision: Staged Knowledge Injection Matters for Agentic RLVR in Ultra-High-Resolution Remote Sensing Understanding
Feb 15, 2026Multimodal reasoning for ultra-high-resolution (UHR) remote sensing (RS) is usually bottlenecked by visual evidence acquisition: the model necessitates localizing tiny task-relevant regions in massive pixel spaces. While Agentic Reinforcement Learning with Verifiable Rewards (RLVR) using zoom-in tools offers a path forward, we find that standard reinforcement learning struggles to navigate these vast visual spaces without structured domain priors. In this paper, we investigate the interplay between post-training paradigms: comparing Cold-start Supervised Fine-Tuning (SFT), RLVR, and Agentic RLVR on the UHR RS benchmark.Our controlled studies yield a counter-intuitive finding: high-quality Earth-science text-only QA is a primary driver of UHR visual reasoning gains. Despite lacking images, domain-specific text injects the concepts, mechanistic explanations, and decision rules necessary to guide visual evidence retrieval.Based on this, we propose a staged knowledge injection recipe: (1) cold-starting with scalable, knowledge-graph-verified Earth-science text QA to instill reasoning structures;and (2) "pre-warming" on the same hard UHR image-text examples during SFT to stabilize and amplify subsequent tool-based RL. This approach achieves a 60.40% Pass@1 on XLRS-Bench, significantly outperforming larger general purpose models (e.g., GPT-5.2, Gemini 3.0 Pro, Intern-S1) and establishing a new state-of-the-art.
GeoEyes: On-Demand Visual Focusing for Evidence-Grounded Understanding of Ultra-High-Resolution Remote Sensing Imagery
Feb 15, 2026The "thinking-with-images" paradigm enables multimodal large language models (MLLMs) to actively explore visual scenes via zoom-in tools. This is essential for ultra-high-resolution (UHR) remote sensing VQA, where task-relevant cues are sparse and tiny. However, we observe a consistent failure mode in existing zoom-enabled MLLMs: Tool Usage Homogenization, where tool calls collapse into task-agnostic patterns, limiting effective evidence acquisition. To address this, we propose GeoEyes, a staged training framework consisting of (1) a cold-start SFT dataset, UHR Chain-of-Zoom (UHR-CoZ), which covers diverse zooming regimes, and (2) an agentic reinforcement learning method, AdaZoom-GRPO, that explicitly rewards evidence gain and answer improvement during zoom interactions. The resulting model learns on-demand zooming with proper stopping behavior and achieves substantial improvements on UHR remote sensing benchmarks, with 54.23% accuracy on XLRS-Bench.
From Retrieval to Reasoning: A Framework for Cyber Threat Intelligence NER with Explicit and Adaptive Instructions
Dec 22, 2025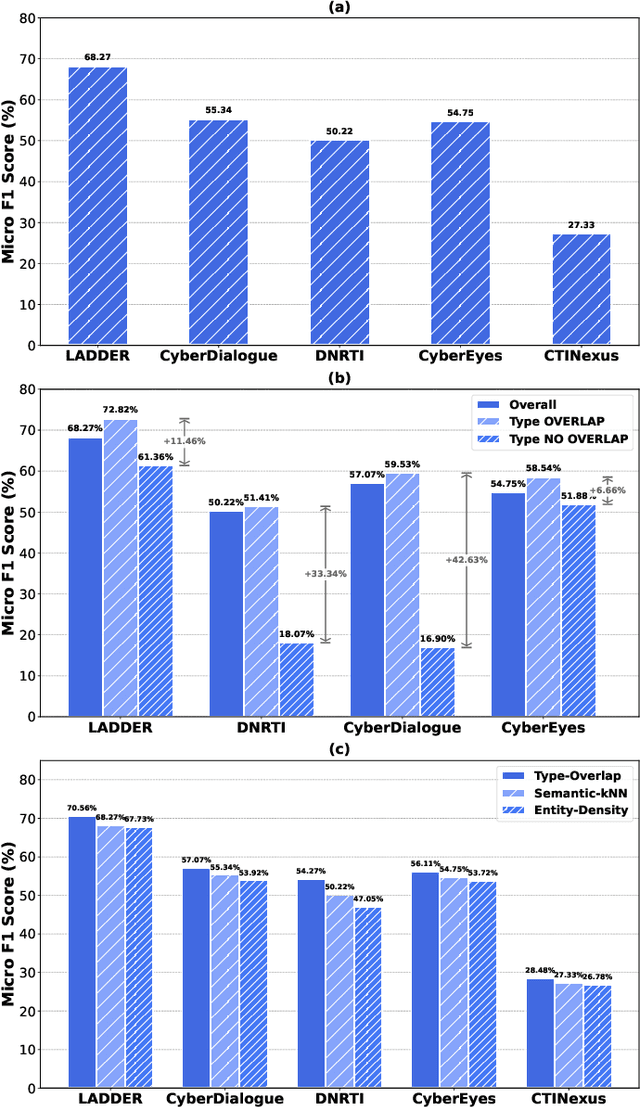
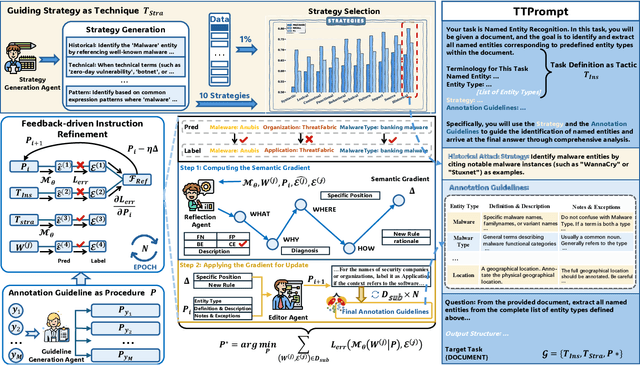
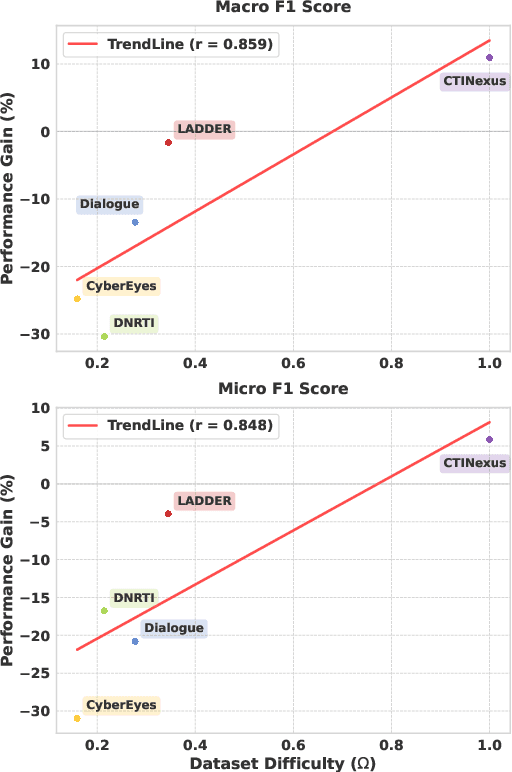
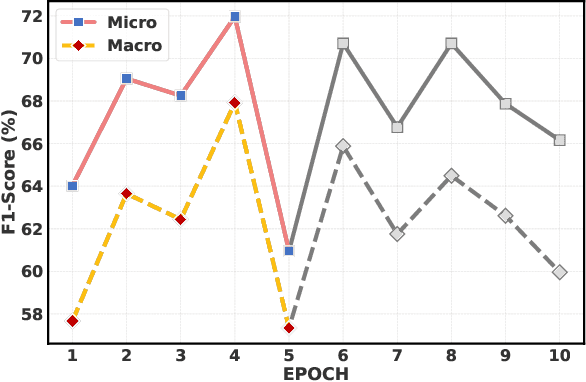
The automation of Cyber Threat Intelligence (CTI) relies heavily on Named Entity Recognition (NER) to extract critical entities from unstructured text. Currently, Large Language Models (LLMs) primarily address this task through retrieval-based In-Context Learning (ICL). This paper analyzes this mainstream paradigm, revealing a fundamental flaw: its success stems not from global semantic similarity but largely from the incidental overlap of entity types within retrieved examples. This exposes the limitations of relying on unreliable implicit induction. To address this, we propose TTPrompt, a framework shifting from implicit induction to explicit instruction. TTPrompt maps the core concepts of CTI's Tactics, Techniques, and Procedures (TTPs) into an instruction hierarchy: formulating task definitions as Tactics, guiding strategies as Techniques, and annotation guidelines as Procedures. Furthermore, to handle the adaptability challenge of static guidelines, we introduce Feedback-driven Instruction Refinement (FIR). FIR enables LLMs to self-refine guidelines by learning from errors on minimal labeled data, adapting to distinct annotation dialects. Experiments on five CTI NER benchmarks demonstrate that TTPrompt consistently surpasses retrieval-based baselines. Notably, with refinement on just 1% of training data, it rivals models fine-tuned on the full dataset. For instance, on LADDER, its Micro F1 of 71.96% approaches the fine-tuned baseline, and on the complex CTINexus, its Macro F1 exceeds the fine-tuned ACLM model by 10.91%.
Enhancing Medical Dialogue Generation through Knowledge Refinement and Dynamic Prompt Adjustment
Jun 12, 2025Medical dialogue systems (MDS) have emerged as crucial online platforms for enabling multi-turn, context-aware conversations with patients. However, existing MDS often struggle to (1) identify relevant medical knowledge and (2) generate personalized, medically accurate responses. To address these challenges, we propose MedRef, a novel MDS that incorporates knowledge refining and dynamic prompt adjustment. First, we employ a knowledge refining mechanism to filter out irrelevant medical data, improving predictions of critical medical entities in responses. Additionally, we design a comprehensive prompt structure that incorporates historical details and evident details. To enable real-time adaptability to diverse patient conditions, we implement two key modules, Triplet Filter and Demo Selector, providing appropriate knowledge and demonstrations equipped in the system prompt. Extensive experiments on MedDG and KaMed benchmarks show that MedRef outperforms state-of-the-art baselines in both generation quality and medical entity accuracy, underscoring its effectiveness and reliability for real-world healthcare applications.
MobileSteward: Integrating Multiple App-Oriented Agents with Self-Evolution to Automate Cross-App Instructions
Feb 24, 2025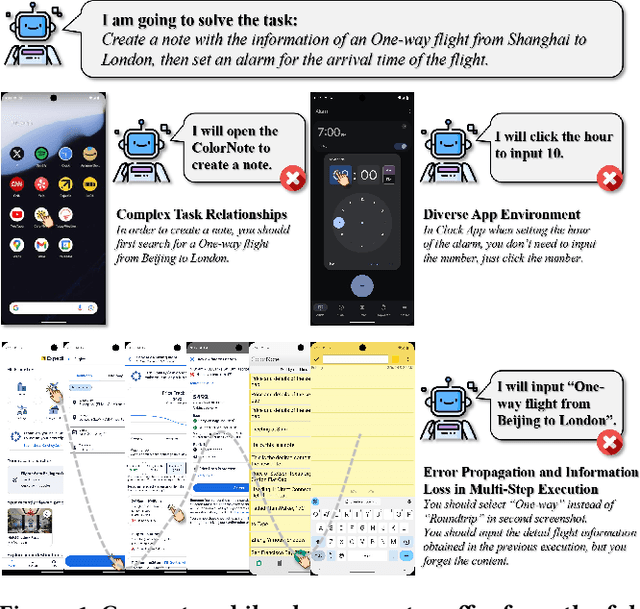

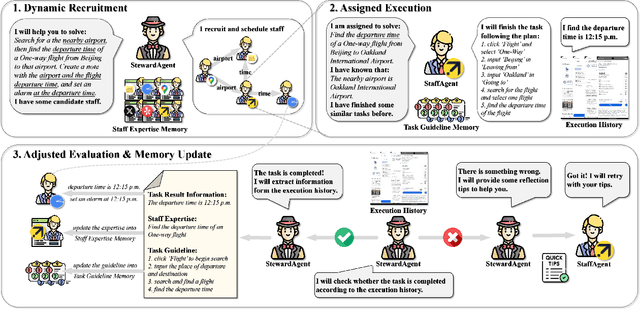
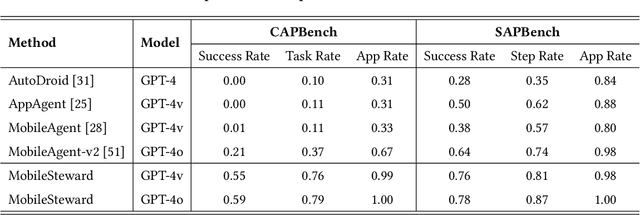
Mobile phone agents can assist people in automating daily tasks on their phones, which have emerged as a pivotal research spotlight. However, existing procedure-oriented agents struggle with cross-app instructions, due to the following challenges: (1) complex task relationships, (2) diverse app environment, and (3) error propagation and information loss in multi-step execution. Drawing inspiration from object-oriented programming principles, we recognize that object-oriented solutions is more suitable for cross-app instruction. To address these challenges, we propose a self-evolving multi-agent framework named MobileSteward, which integrates multiple app-oriented StaffAgents coordinated by a centralized StewardAgent. We design three specialized modules in MobileSteward: (1) Dynamic Recruitment generates a scheduling graph guided by information flow to explicitly associate tasks among apps. (2) Assigned Execution assigns the task to app-oriented StaffAgents, each equipped with app-specialized expertise to address the diversity between apps. (3) Adjusted Evaluation conducts evaluation to provide reflection tips or deliver key information, which alleviates error propagation and information loss during multi-step execution. To continuously improve the performance of MobileSteward, we develop a Memory-based Self-evolution mechanism, which summarizes the experience from successful execution, to improve the performance of MobileSteward. We establish the first English Cross-APP Benchmark (CAPBench) in the real-world environment to evaluate the agents' capabilities of solving complex cross-app instructions. Experimental results demonstrate that MobileSteward achieves the best performance compared to both single-agent and multi-agent frameworks, highlighting the superiority of MobileSteward in better handling user instructions with diverse complexity.
BiDeV: Bilateral Defusing Verification for Complex Claim Fact-Checking
Feb 22, 2025

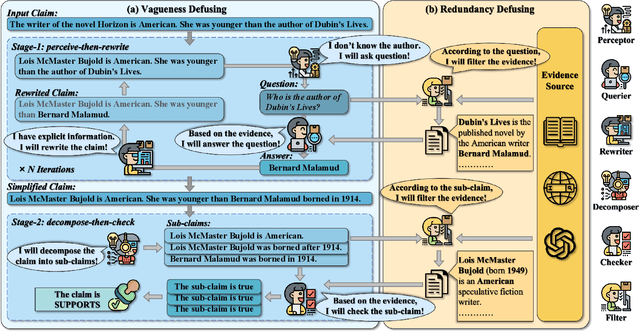
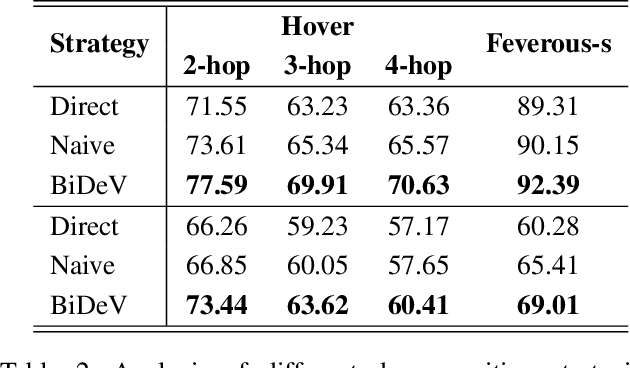
Complex claim fact-checking performs a crucial role in disinformation detection. However, existing fact-checking methods struggle with claim vagueness, specifically in effectively handling latent information and complex relations within claims. Moreover, evidence redundancy, where nonessential information complicates the verification process, remains a significant issue. To tackle these limitations, we propose Bilateral Defusing Verification (BiDeV), a novel fact-checking working-flow framework integrating multiple role-played LLMs to mimic the human-expert fact-checking process. BiDeV consists of two main modules: Vagueness Defusing identifies latent information and resolves complex relations to simplify the claim, and Redundancy Defusing eliminates redundant content to enhance the evidence quality. Extensive experimental results on two widely used challenging fact-checking benchmarks (Hover and Feverous-s) demonstrate that our BiDeV can achieve the best performance under both gold and open settings. This highlights the effectiveness of BiDeV in handling complex claims and ensuring precise fact-checking
One Small and One Large for Document-level Event Argument Extraction
Nov 08, 2024
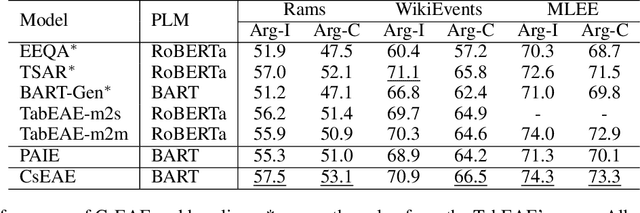
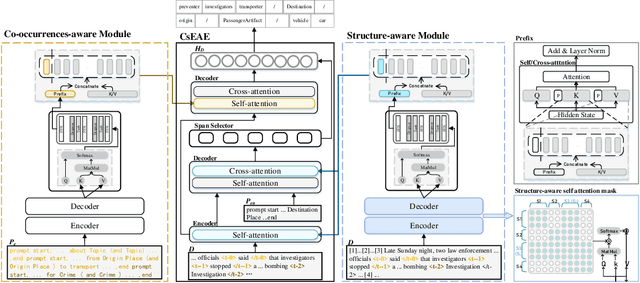
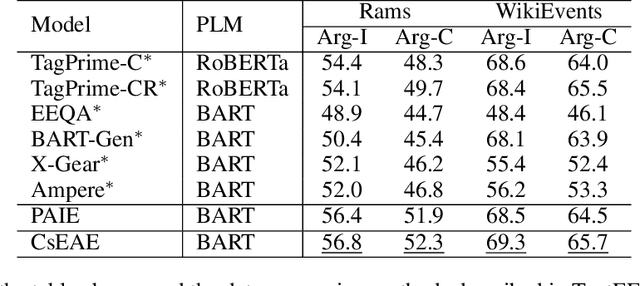
Document-level Event Argument Extraction (EAE) faces two challenges due to increased input length: 1) difficulty in distinguishing semantic boundaries between events, and 2) interference from redundant information. To address these issues, we propose two methods. The first method introduces the Co and Structure Event Argument Extraction model (CsEAE) based on Small Language Models (SLMs). CsEAE includes a co-occurrences-aware module, which integrates information about all events present in the current input through context labeling and co-occurrences event prompts extraction. Additionally, CsEAE includes a structure-aware module that reduces interference from redundant information by establishing structural relationships between the sentence containing the trigger and other sentences in the document. The second method introduces new prompts to transform the extraction task into a generative task suitable for Large Language Models (LLMs), addressing gaps in EAE performance using LLMs under Supervised Fine-Tuning (SFT) conditions. We also fine-tuned multiple datasets to develop an LLM that performs better across most datasets. Finally, we applied insights from CsEAE to LLMs, achieving further performance improvements. This suggests that reliable insights validated on SLMs are also applicable to LLMs. We tested our models on the Rams, WikiEvents, and MLEE datasets. The CsEAE model achieved improvements of 2.1\%, 2.3\%, and 3.2\% in the Arg-C F1 metric compared to the baseline, PAIE~\cite{PAIE}. For LLMs, we demonstrated that their performance on document-level datasets is comparable to that of SLMs~\footnote{All code is available at https://github.com/simon-p-j-r/CsEAE}.
Mobile-Bench: An Evaluation Benchmark for LLM-based Mobile Agents
Jul 01, 2024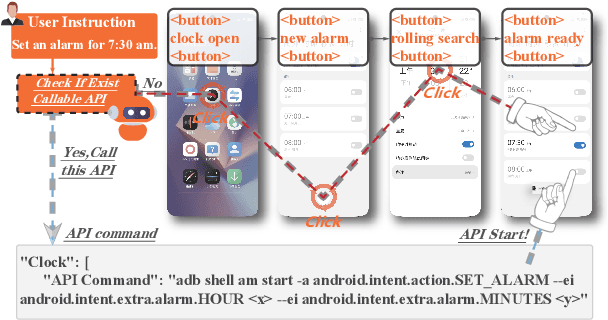


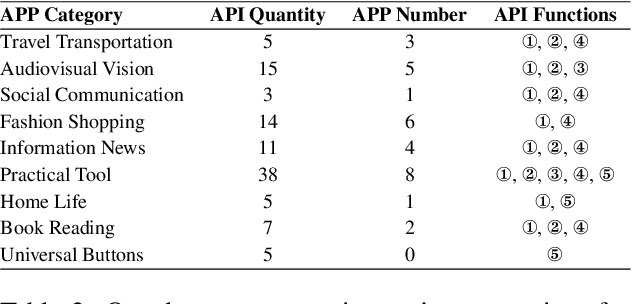
With the remarkable advancements of large language models (LLMs), LLM-based agents have become a research hotspot in human-computer interaction. However, there is a scarcity of benchmarks available for LLM-based mobile agents. Benchmarking these agents generally faces three main challenges: (1) The inefficiency of UI-only operations imposes limitations to task evaluation. (2) Specific instructions within a singular application lack adequacy for assessing the multi-dimensional reasoning and decision-making capacities of LLM mobile agents. (3) Current evaluation metrics are insufficient to accurately assess the process of sequential actions. To this end, we propose Mobile-Bench, a novel benchmark for evaluating the capabilities of LLM-based mobile agents. First, we expand conventional UI operations by incorporating 103 collected APIs to accelerate the efficiency of task completion. Subsequently, we collect evaluation data by combining real user queries with augmentation from LLMs. To better evaluate different levels of planning capabilities for mobile agents, our data is categorized into three distinct groups: SAST, SAMT, and MAMT, reflecting varying levels of task complexity. Mobile-Bench comprises 832 data entries, with more than 200 tasks specifically designed to evaluate multi-APP collaboration scenarios. Furthermore, we introduce a more accurate evaluation metric, named CheckPoint, to assess whether LLM-based mobile agents reach essential points during their planning and reasoning steps.