 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Multi-Role Capabilities of Large Language Models for Open-Domain Question Answering
Mar 08, 2024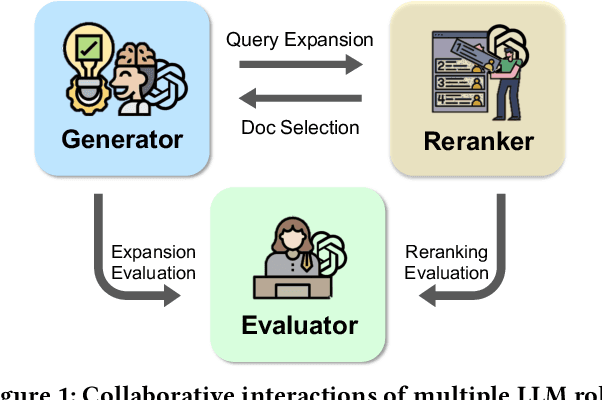
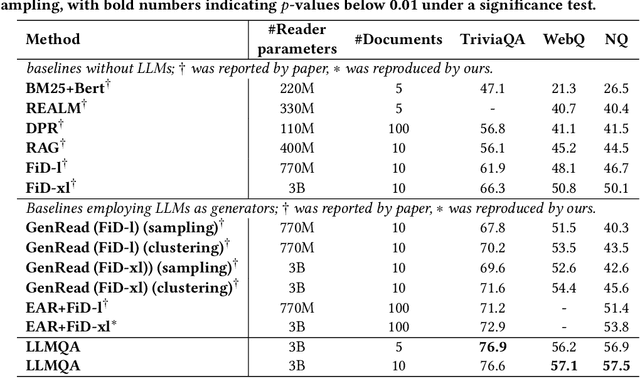
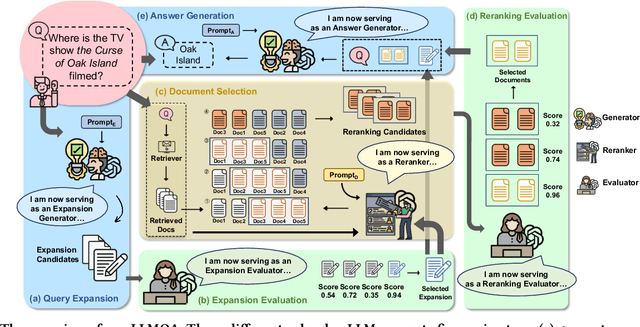
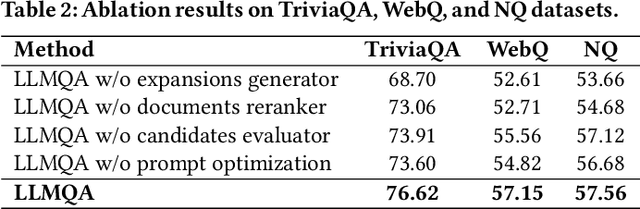
Open-domain question answering (ODQA) has emerged as a pivotal research spotlight in information systems. Existing methods follow two main paradigms to collect evidence: (1) The \textit{retrieve-then-read} paradigm retrieves pertinent documents from an external corpus; and (2) the \textit{generate-then-read} paradigm employs large language models (LLMs) to generate relevant documents. However, neither can fully address multifaceted requirements for evidence. To this end, we propose LLMQA, a generalized framework that formulates the ODQA process into three basic steps: query expansion, document selection, and answer generation, combining the superiority of both retrieval-based and generation-based evidence. Since LLMs exhibit their excellent capabilities to accomplish various tasks, we instruct LLMs to play multiple roles as generators, rerankers, and evaluators within our framework, integrating them to collaborate in the ODQA process. Furthermore, we introduce a novel prompt optimization algorithm to refine role-playing prompts and steer LLMs to produce higher-quality evidence and answers. Extensive experimental results on widely used benchmarks (NQ, WebQ, and TriviaQA) demonstrate that LLMQA achieves the best performance in terms of both answer accuracy and evidence quality, showcasing its potential for advancing ODQA research and applications.
Why pseudo label based algorithm is effective? --from the perspective of pseudo labeled data
Nov 18, 2022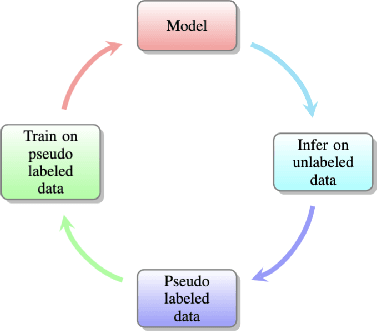

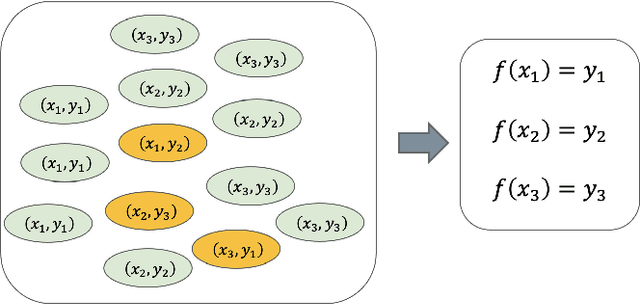

Recently, pseudo label based semi-supervised learning has achieved great success in many fields. The core idea of the pseudo label based semi-supervised learning algorithm is to use the model trained on the labeled data to generate pseudo labels on the unlabeled data, and then train a model to fit the previously generated pseudo labels. We give a theory analysis for why pseudo label based semi-supervised learning is effective in this paper. We mainly compare the generalization error of the model trained under two settings: (1) There are N labeled data. (2) There are N unlabeled data and a suitable initial model. Our analysis shows that, firstly, when the amount of unlabeled data tends to infinity, the pseudo label based semi-supervised learning algorithm can obtain model which have the same generalization error upper bound as model obtained by normally training in the condition of the amount of labeled data tends to infinity. More importantly, we prove that when the amount of unlabeled data is large enough, the generalization error upper bound of the model obtained by pseudo label based semi-supervised learning algorithm can converge to the optimal upper bound with linear convergence rate. We also give the lower bound on sampling complexity to achieve linear convergence rate. Our analysis contributes to understanding the empirical successes of pseudo label-based semi-supervised learning.
Stochastic Modified Equations and Dynamics of Stochastic Gradient Algorithms I: Mathematical Foundations
Nov 05, 2018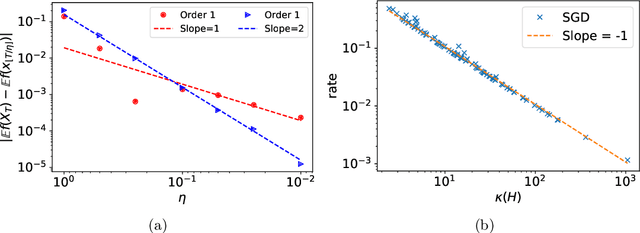
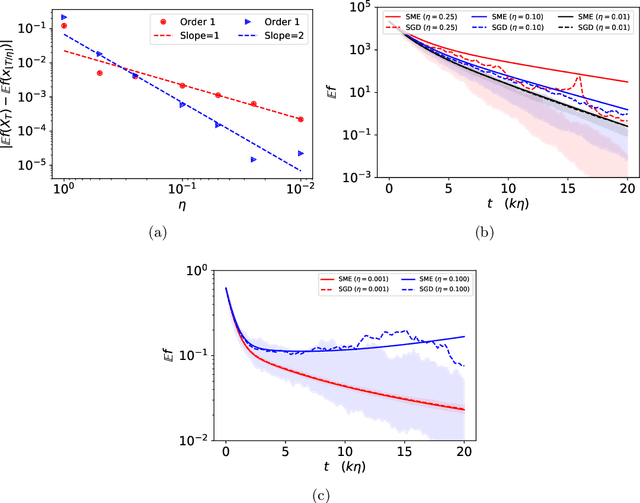
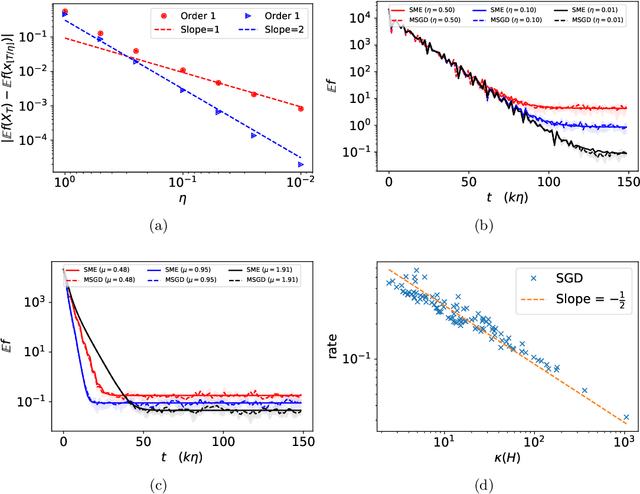
We develop the mathematical foundations of the stochastic modified equations (SME) framework for analyzing the dynamics of stochastic gradient algorithms, where the latter is approximated by a class of stochastic differential equations with small noise parameters. We prove that this approximation can be understood mathematically as an weak approximation, which leads to a number of precise and useful results on the approximations of stochastic gradient descent (SGD), momentum SGD and stochastic Nesterov's accelerated gradient method in the general setting of stochastic objectives. We also demonstrate through explicit calculations that this continuous-time approach can uncover important analytical insights into the stochastic gradient algorithms under consideration that may not be easy to obtain in a purely discrete-time setting.
Maximum Principle Based Algorithms for Deep Learning
Jun 02, 2018
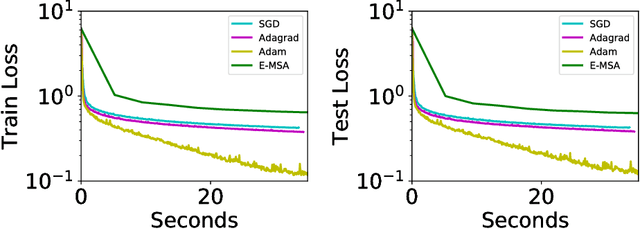
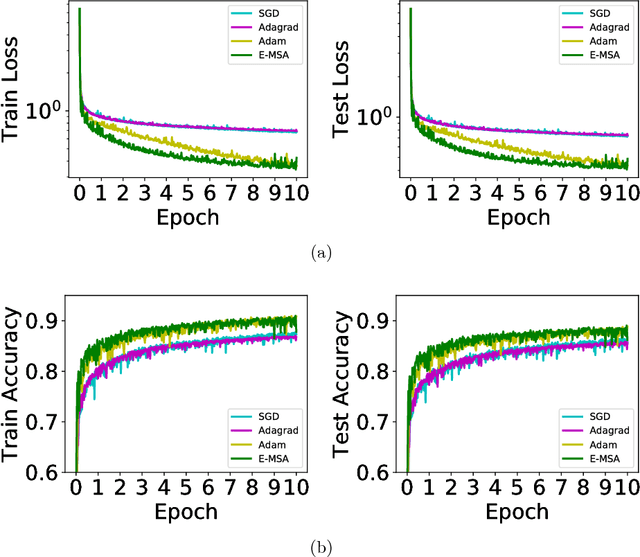
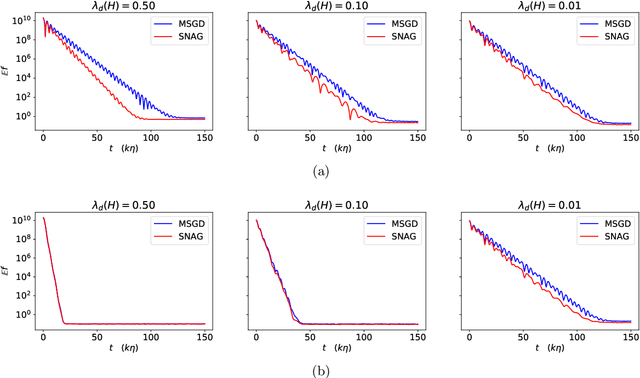
The continuous dynamical system approach to deep learning is explored in order to devise alternative frameworks for training algorithms. Training is recast as a control problem and this allows us to formulate necessary optimality conditions in continuous time using the Pontryagin's maximum principle (PMP). A modification of the method of successive approximations is then used to solve the PMP, giving rise to an alternative training algorithm for deep learning. This approach has the advantage that rigorous error estimates and convergence results can be established. We also show that it may avoid some pitfalls of gradient-based methods, such as slow convergence on flat landscapes near saddle points. Furthermore, we demonstrate that it obtains favorable initial convergence rate per-iteration, provided Hamiltonian maximization can be efficiently carried out - a step which is still in need of improvement. Overall, the approach opens up new avenues to attack problems associated with deep learning, such as trapping in slow manifolds and inapplicability of gradient-based methods for discrete trainable variables.
* Published version
Understanding and Enhancing the Transferability of Adversarial Examples
Feb 27, 2018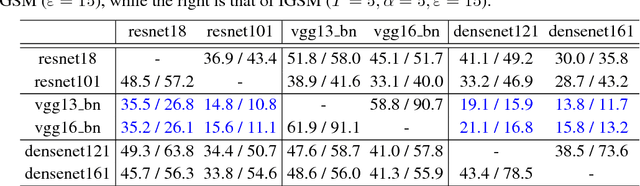
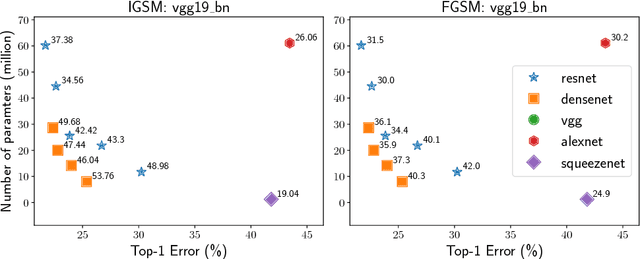
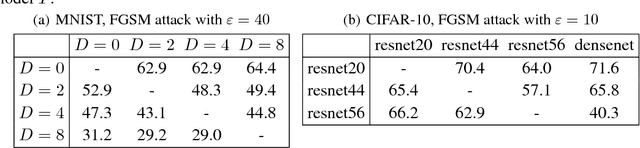
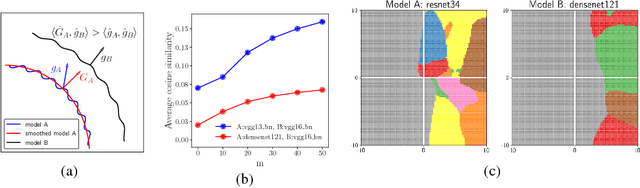
State-of-the-art deep neural networks are known to be vulnerable to adversarial examples, formed by applying small but malicious perturbations to the original inputs. Moreover, the perturbations can \textit{transfer across models}: adversarial examples generated for a specific model will often mislead other unseen models. Consequently the adversary can leverage it to attack deployed systems without any query, which severely hinder the application of deep learning, especially in the areas where security is crucial. In this work, we systematically study how two classes of factors that might influence the transferability of adversarial examples. One is about model-specific factors, including network architecture, model capacity and test accuracy. The other is the local smoothness of loss function for constructing adversarial examples. Based on these understanding, a simple but effective strategy is proposed to enhance transferability. We call it variance-reduced attack, since it utilizes the variance-reduced gradient to generate adversarial example. The effectiveness is confirmed by a variety of experiments on both CIFAR-10 and ImageNet datasets.
Stochastic modified equations and adaptive stochastic gradient algorithms
Jun 20, 2017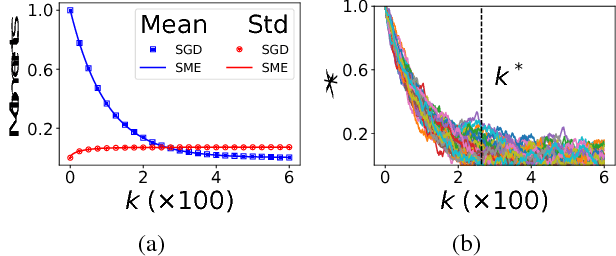
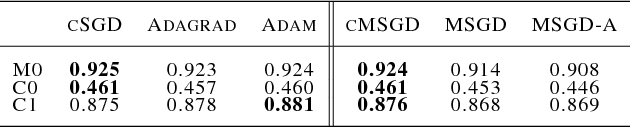
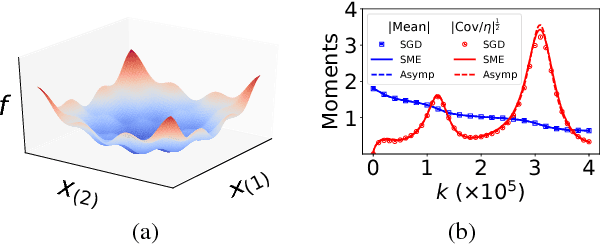
We develop the method of stochastic modified equations (SME), in which stochastic gradient algorithms are approximated in the weak sense by continuous-time stochastic differential equations. We exploit the continuous formulation together with optimal control theory to derive novel adaptive hyper-parameter adjustment policies. Our algorithms have competitive performance with the added benefit of being robust to varying models and datasets. This provides a general methodology for the analysis and design of stochastic gradient algorithms.
Convolutional neural networks with low-rank regularization
Feb 14, 2016

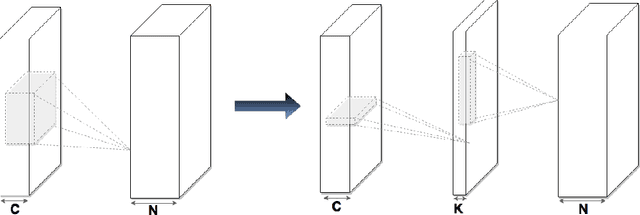
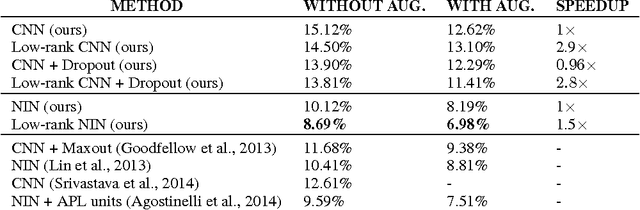
Large CNNs have delivered impressive performance in various computer vision applications. But the storage and computation requirements make it problematic for deploying these models on mobile devices. Recently, tensor decompositions have been used for speeding up CNNs. In this paper, we further develop the tensor decomposition technique. We propose a new algorithm for computing the low-rank tensor decomposition for removing the redundancy in the convolution kernels. The algorithm finds the exact global optimizer of the decomposition and is more effective than iterative methods. Based on the decomposition, we further propose a new method for training low-rank constrained CNNs from scratch. Interestingly, while achieving a significant speedup, sometimes the low-rank constrained CNNs delivers significantly better performance than their non-constrained counterparts. On the CIFAR-10 dataset, the proposed low-rank NIN model achieves $91.31\%$ accuracy (without data augmentation), which also improves upon state-of-the-art result. We evaluated the proposed method on CIFAR-10 and ILSVRC12 datasets for a variety of modern CNNs, including AlexNet, NIN, VGG and GoogleNet with success. For example, the forward time of VGG-16 is reduced by half while the performance is still comparable. Empirical success suggests that low-rank tensor decompositions can be a very useful tool for speeding up large CNNs.
Multiscale Adaptive Representation of Signals: I. The Basic Framework
Jul 17, 2015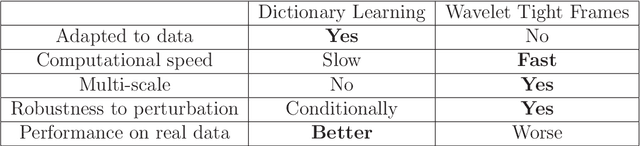

We introduce a framework for designing multi-scale, adaptive, shift-invariant frames and bi-frames for representing signals. The new framework, called AdaFrame, improves over dictionary learning-based techniques in terms of computational efficiency at inference time. It improves classical multi-scale basis such as wavelet frames in terms of coding efficiency. It provides an attractive alternative to dictionary learning-based techniques for low level signal processing tasks, such as compression and denoising, as well as high level tasks, such as feature extraction for object recognition. Connections with deep convolutional networks are also discussed. In particular, the proposed framework reveals a drawback in the commonly used approach for visualizing the activations of the intermediate layers in convolutional networks, and suggests a natural alternative.