 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Enhancing the Transferability of Adversarial Examples
Paper and Code
Feb 27, 2018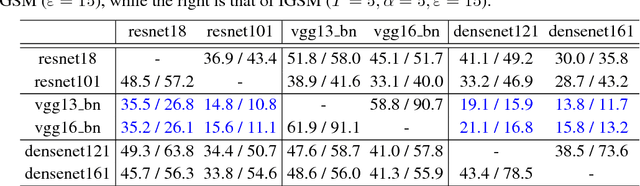
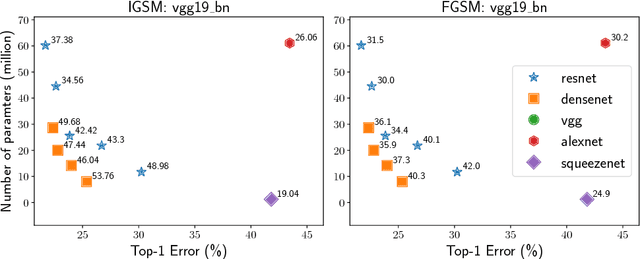
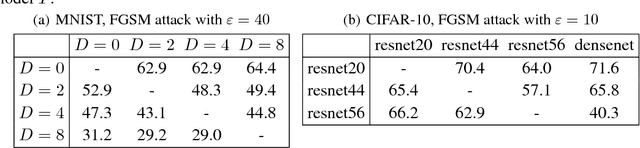
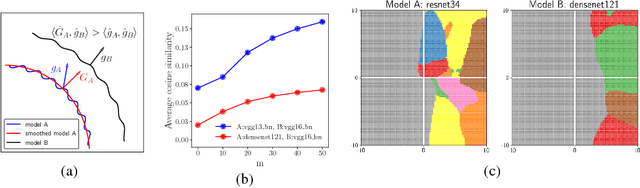
State-of-the-art deep neural networks are known to be vulnerable to adversarial examples, formed by applying small but malicious perturbations to the original inputs. Moreover, the perturbations can \textit{transfer across models}: adversarial examples generated for a specific model will often mislead other unseen models. Consequently the adversary can leverage it to attack deployed systems without any query, which severely hinder the application of deep learning, especially in the areas where security is crucial. In this work, we systematically study how two classes of factors that might influence the transferability of adversarial examples. One is about model-specific factors, including network architecture, model capacity and test accuracy. The other is the local smoothness of loss function for constructing adversarial examples. Based on these understanding, a simple but effective strategy is proposed to enhance transferability. We call it variance-reduced attack, since it utilizes the variance-reduced gradient to generate adversarial example. The effectiveness is confirmed by a variety of experiments on both CIFAR-10 and ImageNet datasets.