 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOCS: Quantifying Weight Similarity for Deeper Insights into Large Language Models
Jan 28, 2025
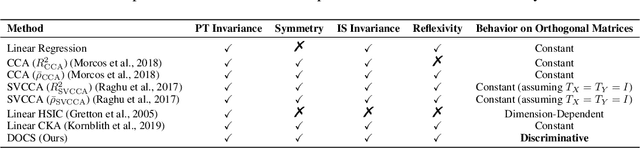

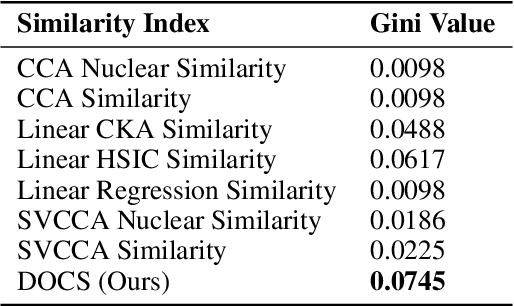
We introduce a novel index, the Distribution of Cosine Similarity (DOCS), for quantitatively assessing the similarity between weight matrices in Large Language Models (LLMs), aiming to facilitate the analysis of their complex architectures. Leveraging DOCS, our analysis uncovers intriguing patterns in the latest open-source LLMs: adjacent layers frequently exhibit high weight similarity and tend to form clusters, suggesting depth-wise functional specialization. Additionally, we prove that DOCS is theoretically effective in quantifying similarity for orthogonal matrices, a crucial aspect given the prevalence of orthogonal initializations in LLMs. This research contributes to a deeper understanding of LLM architecture and behavior, offering tools with potential implications for developing more efficient and interpretable models.
Achieving Margin Maximization Exponentially Fast via Progressive Norm Rescaling
Dec 08, 2023



In this work, we investigate the margin-maximization bias exhibited by gradient-based algorithms in classifying linearly separable data. We present an in-depth analysis of the specific properties of the velocity field associated with (normalized) gradients, focusing on their role in margin maximization. Inspired by this analysis, we propose a novel algorithm called Progressive Rescaling Gradient Descent (PRGD) and show that PRGD can maximize the margin at an {\em exponential rate}. This stands in stark contrast to all existing algorithms, which maximize the margin at a slow {\em polynomial rate}. Specifically, we identify mild conditions on data distribution under which existing algorithms such as gradient descent (GD) and normalized gradient descent (NGD) {\em provably fail} in maximizing the margin efficiently. To validate our theoretical findings, we present both synthetic and real-world experiments. Notably, PRGD also shows promise in enhancing the generalization performance when applied to linearly non-separable datasets and deep neural networks.
Exploring the Integration of Large Language Models into Automatic Speech Recognition Systems: An Empirical Study
Jul 13, 2023



This paper explores the integration of Large Language Models (LLMs) into Automatic Speech Recognition (ASR) systems to improve transcription accuracy. The increasing sophistication of LLMs, with their in-context learning capabilities and instruction-following behavior, has drawn significant attention in the field of Natural Language Processing (NLP). Our primary focus is to investigate the potential of using an LLM's in-context learning capabilities to enhance the performance of ASR systems, which currently face challenges such as ambient noise, speaker accents, and complex linguistic contexts. We designed a study using the Aishell-1 and LibriSpeech datasets, with ChatGPT and GPT-4 serving as benchmarks for LLM capabilities. Unfortunately, our initial experiments did not yield promising results, indicating the complexity of leveraging LLM's in-context learning for ASR applications. Despite further exploration with varied settings and models, the corrected sentences from the LLMs frequently resulted in higher Word Error Rates (WER), demonstrating the limitations of LLMs in speech applications. This paper provides a detailed overview of these experiments, their results, and implications, establishing that using LLMs' in-context learning capabilities to correct potential errors in speech recognition transcriptions is still a challenging task at the current stage.
MAC: A unified framework boosting low resource automatic speech recognition
Feb 15, 2023We propose a unified framework for low resource automatic speech recognition tasks named meta audio concatenation (MAC). It is easy to implement and can be carried out in extremely low resource environments. Mathematically, we give a clear description of MAC framework from the perspective of bayesian sampling. In this framework, we leverage a novel concatenative synthesis text-to-speech system to boost the low resource ASR task. By the concatenative synthesis text-to-speech system, we can integrate language pronunciation rules and adjust the TTS process. Furthermore, we propose a broad notion of meta audio set to meet the modeling needs of different languages and different scenes when using the system. Extensive experiments have demonstrated the great effectiveness of MAC on low resource ASR tasks. For CTC greedy search, CTC prefix, attention, and attention rescoring decode mode in Cantonese ASR task, Taiwanese ASR task, and Japanese ASR task the MAC method can reduce the CER by more than 15\%. Furthermore, in the ASR task, MAC beats wav2vec2 (with fine-tuning) on common voice datasets of Cantonese and gets really competitive results on common voice datasets of Taiwanese and Japanese. Among them, it is worth mentioning that we achieve a \textbf{10.9\%} character error rate (CER) on the common voice Cantonese ASR task, bringing about \textbf{30\%} relative improvement compared to the wav2vec2 (with fine-tuning).
Attention Link: An Efficient Attention-Based Low Resource Machine Translation Architecture
Feb 01, 2023Transformers have achieved great success in machine translation, but transformer-based NMT models often require millions of bilingual parallel corpus for training. In this paper, we propose a novel architecture named as attention link (AL) to help improve transformer models' performance, especially in low training resources. We theoretically demonstrate the superiority of our attention link architecture in low training resources. Besides, we have done a large number of experiments, including en-de, de-en, en-fr, en-it, it-en, en-ro translation tasks on the IWSLT14 dataset as well as real low resources scene on bn-gu and gu-ta translation tasks on the CVIT PIB dataset. All the experiment results show our attention link is powerful and can lead to a significant improvement. In addition, we achieve a 37.9 BLEU score, a new sota, on the IWSLT14 de-en task by combining our attention link and other advanced methods.
Why pseudo label based algorithm is effective? --from the perspective of pseudo labeled data
Nov 18, 2022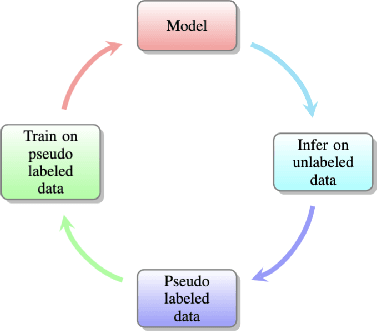

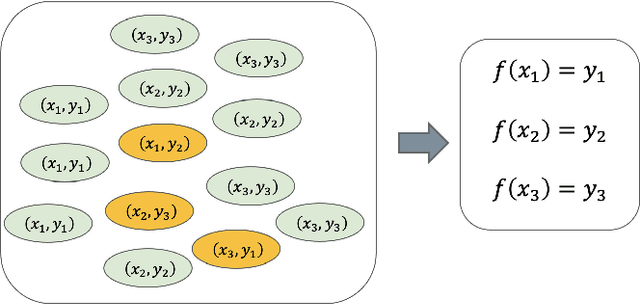

Recently, pseudo label based semi-supervised learning has achieved great success in many fields. The core idea of the pseudo label based semi-supervised learning algorithm is to use the model trained on the labeled data to generate pseudo labels on the unlabeled data, and then train a model to fit the previously generated pseudo labels. We give a theory analysis for why pseudo label based semi-supervised learning is effective in this paper. We mainly compare the generalization error of the model trained under two settings: (1) There are N labeled data. (2) There are N unlabeled data and a suitable initial model. Our analysis shows that, firstly, when the amount of unlabeled data tends to infinity, the pseudo label based semi-supervised learning algorithm can obtain model which have the same generalization error upper bound as model obtained by normally training in the condition of the amount of labeled data tends to infinity. More importantly, we prove that when the amount of unlabeled data is large enough, the generalization error upper bound of the model obtained by pseudo label based semi-supervised learning algorithm can converge to the optimal upper bound with linear convergence rate. We also give the lower bound on sampling complexity to achieve linear convergence rate. Our analysis contributes to understanding the empirical successes of pseudo label-based semi-supervised learning.
SAN: a robust end-to-end ASR model architecture
Oct 27, 2022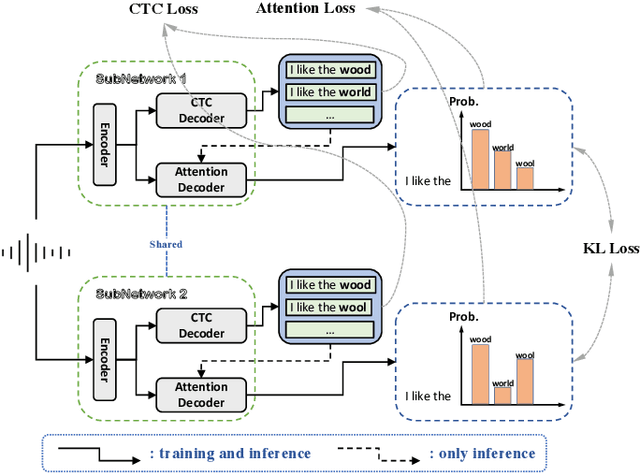
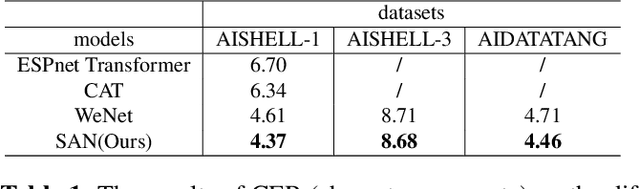
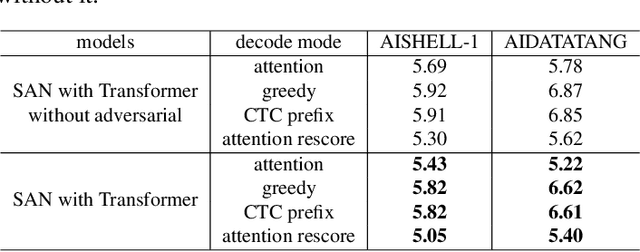

In this paper, we propose a novel Siamese Adversarial Network (SAN) architecture for automatic speech recognition, which aims at solving the difficulty of fuzzy audio recognition. Specifically, SAN constructs two sub-networks to differentiate the audio feature input and then introduces a loss to unify the output distribution of these sub-networks. Adversarial learning enables the network to capture more essential acoustic features and helps the models achieve better performance when encountering fuzzy audio input. We conduct numerical experiments with the SAN model on several datasets for the automatic speech recognition task. All experimental results show that the siamese adversarial nets significantly reduce the character error rate (CER). Specifically, we achieve a new state of art 4.37 CER without language model on the AISHELL-1 dataset, which leads to around 5% relative CER reduction. To reveal the generality of the siamese adversarial net, we also conduct experiments on the phoneme recognition task, which also shows the superiority of the siamese adversarial network.
10 hours data is all you need
Oct 24, 2022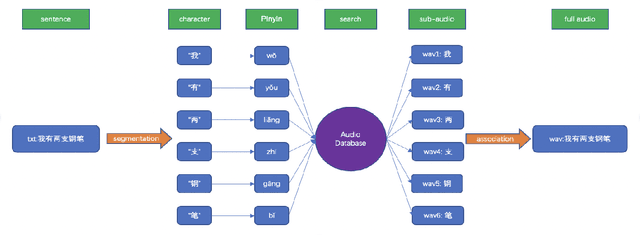

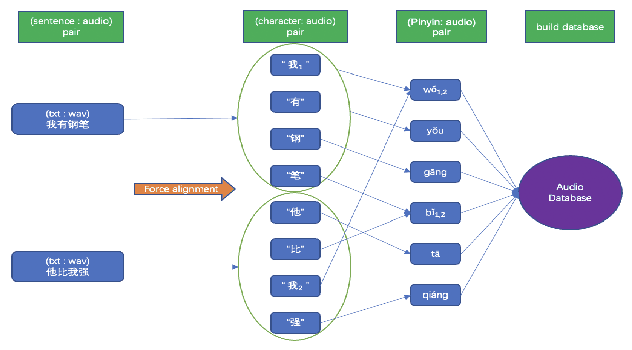

We propose a novel procedure to generate pseudo mandarin speech data named as CAMP (character audio mix up), which aims at generating audio from a character scale. We also raise a method for building a mandarin character scale audio database adaptive to CAMP named as META-AUDIO, which makes full use of audio data and can greatly increase the data diversity of the database. Experiments show that our CAMP method is simple and quite effective. For example, we train models with 10 hours of audio data in AISHELL-1 and pseudo audio data generated by CAMP, and achieve a competitive 11.07 character error rate (CER). Besides, we also perform training with only 10 hours of audio data in AIDATATANG dataset and pseudo audio data generated by CAMP, which again achieves a competitive 8.26 CER.