 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Single Merging Suffices: Recovering Server-based Learning Performance in Decentralized Learning
Jul 09, 2025Decentralized learning provides a scalable alternative to traditional parameter-server-based training, yet its performance is often hindered by limited peer-to-peer communication. In this paper, we study how communication should be scheduled over time, including determining when and how frequently devices synchronize. Our empirical results show that concentrating communication budgets in the later stages of decentralized training markedly improves global generalization. Surprisingly, we uncover that fully connected communication at the final step, implemented by a single global merging, is sufficient to match the performance of server-based training. We further show that low communication in decentralized learning preserves the \textit{mergeability} of local models throughout training. Our theoretical contributions, which explains these phenomena, are first to establish that the globally merged model of decentralized SGD can converge faster than centralized mini-batch SGD. Technically, we novelly reinterpret part of the discrepancy among local models, which were previously considered as detrimental noise, as constructive components that accelerate convergence. This work challenges the common belief that decentralized learning generalizes poorly under data heterogeneity and limited communication, while offering new insights into model merging and neural network loss landscapes.
GradPower: Powering Gradients for Faster Language Model Pre-Training
May 30, 2025



We propose GradPower, a lightweight gradient-transformation technique for accelerating language model pre-training. Given a gradient vector $g=(g_i)_i$, GradPower first applies the elementwise sign-power transformation: $\varphi_p(g)=({\rm sign}(g_i)|g_i|^p)_{i}$ for a fixed $p>0$, and then feeds the transformed gradient into a base optimizer. Notably, GradPower requires only a single-line code change and no modifications to the base optimizer's internal logic, including the hyperparameters. When applied to Adam (termed AdamPower), GradPower consistently achieves lower terminal loss across diverse architectures (LLaMA, Qwen2MoE), parameter scales (66M to 2B), datasets (C4, OpenWebText), and learning-rate schedules (cosine, warmup-stable-decay). The most pronounced gains are observed when training modern mixture-of-experts models with warmup-stable-decay schedules. GradPower also integrates seamlessly with other state-of-the-art optimizers, such as Muon, yielding further improvements. Finally, we provide theoretical analyses that reveal the underlying mechanism of GradPower and highlights the influence of gradient noise.
On the Expressive Power of Mixture-of-Experts for Structured Complex Tasks
May 30, 2025Mixture-of-experts networks (MoEs) have demonstrated remarkable efficiency in modern deep learning. Despite their empirical success, the theoretical foundations underlying their ability to model complex tasks remain poorly understood. In this work, we conduct a systematic study of the expressive power of MoEs in modeling complex tasks with two common structural priors: low-dimensionality and sparsity. For shallow MoEs, we prove that they can efficiently approximate functions supported on low-dimensional manifolds, overcoming the curse of dimensionality. For deep MoEs, we show that $\cO(L)$-layer MoEs with $E$ experts per layer can approximate piecewise functions comprising $E^L$ pieces with compositional sparsity, i.e., they can exhibit an exponential number of structured tasks. Our analysis reveals the roles of critical architectural components and hyperparameters in MoEs, including the gating mechanism, expert networks, the number of experts, and the number of layers, and offers natural suggestions for MoE variants.
The Sharpness Disparity Principle in Transformers for Accelerating Language Model Pre-Training
Feb 26, 2025Transformers consist of diverse building blocks, such as embedding layers, normalization layers, self-attention mechanisms, and point-wise feedforward networks. Thus, understanding the differences and interactions among these blocks is important. In this paper, we uncover a clear Sharpness Disparity across these blocks, which emerges early in training and intriguingly persists throughout the training process. Motivated by this finding, we propose Blockwise Learning Rate (LR), a strategy that tailors the LR to each block's sharpness, accelerating large language model (LLM) pre-training. By integrating Blockwise LR into AdamW, we consistently achieve lower terminal loss and nearly $2\times$ speedup compared to vanilla AdamW. We demonstrate this acceleration across GPT-2 and LLaMA, with model sizes ranging from 0.12B to 1.1B and datasets of OpenWebText and MiniPile. Finally, we incorporate Blockwise LR into Adam-mini (Zhang et al., 2024), a recently proposed memory-efficient variant of Adam, achieving a combined $2\times$ speedup and $2\times$ memory saving. These results underscore the potential of exploiting the sharpness disparity to improve LLM training.
CCExpert: Advancing MLLM Capability in Remote Sensing Change Captioning with Difference-Aware Integration and a Foundational Dataset
Nov 18, 2024



Remote Sensing Image Change Captioning (RSICC) aims to generate natural language descriptions of surface changes between multi-temporal remote sensing images, detailing the categories, locations, and dynamics of changed objects (e.g., additions or disappearances). Many current methods attempt to leverage the long-sequence understanding and reasoning capabilities of multimodal large language models (MLLMs) for this task. However, without comprehensive data support, these approaches often alter the essential feature transmission pathways of MLLMs, disrupting the intrinsic knowledge within the models and limiting their potential in RSICC. In this paper, we propose a novel model, CCExpert, based on a new, advanced multimodal large model framework. Firstly, we design a difference-aware integration module to capture multi-scale differences between bi-temporal images and incorporate them into the original image context, thereby enhancing the signal-to-noise ratio of differential features. Secondly, we constructed a high-quality, diversified dataset called CC-Foundation, containing 200,000 image pairs and 1.2 million captions, to provide substantial data support for continue pretraining in this domain. Lastly, we employed a three-stage progressive training process to ensure the deep integration of the difference-aware integration module with the pretrained MLLM. CCExpert achieved a notable performance of $S^*_m=81.80$ on the LEVIR-CC benchmark, significantly surpassing previous state-of-the-art methods. The code and part of the dataset will soon be open-sourced at https://github.com/Meize0729/CCExpert.
How Transformers Implement Induction Heads: Approximation and Optimization Analysis
Oct 15, 2024
Transformers have demonstrated exceptional in-context learning capabilities, yet the theoretical understanding of the underlying mechanisms remain limited. A recent work (Elhage et al., 2021) identified a "rich" in-context mechanism known as induction head, contrasting with "lazy" $n$-gram models that overlook long-range dependencies. In this work, we provide both approximation and optimization analyses of how transformers implement induction heads. In the approximation analysis, we formalize both standard and generalized induction head mechanisms, and examine how transformers can efficiently implement them, with an emphasis on the distinct role of each transformer submodule. For the optimization analysis, we study the training dynamics on a synthetic mixed target, composed of a 4-gram and an in-context 2-gram component. This setting enables us to precisely characterize the entire training process and uncover an {\em abrupt transition} from lazy (4-gram) to rich (induction head) mechanisms as training progresses.
Sharpness-Aware Minimization Efficiently Selects Flatter Minima Late in Training
Oct 14, 2024



Sharpness-Aware Minimization (SAM) has substantially improved the generalization of neural networks under various settings. Despite the success, its effectiveness remains poorly understood. In this work, we discover an intriguing phenomenon in the training dynamics of SAM, shedding lights on understanding its implicit bias towards flatter minima over Stochastic Gradient Descent (SGD). Specifically, we find that SAM efficiently selects flatter minima late in training. Remarkably, even a few epochs of SAM applied at the end of training yield nearly the same generalization and solution sharpness as full SAM training. Subsequently, we delve deeper into the underlying mechanism behind this phenomenon. Theoretically, we identify two phases in the learning dynamics after applying SAM late in training: i) SAM first escapes the minimum found by SGD exponentially fast; and ii) then rapidly converges to a flatter minimum within the same valley. Furthermore, we empirically investigate the role of SAM during the early training phase. We conjecture that the optimization method chosen in the late phase is more crucial in shaping the final solution's properties. Based on this viewpoint, we extend our findings from SAM to Adversarial Training.
Incorporate LLMs with Influential Recommender System
Sep 07, 2024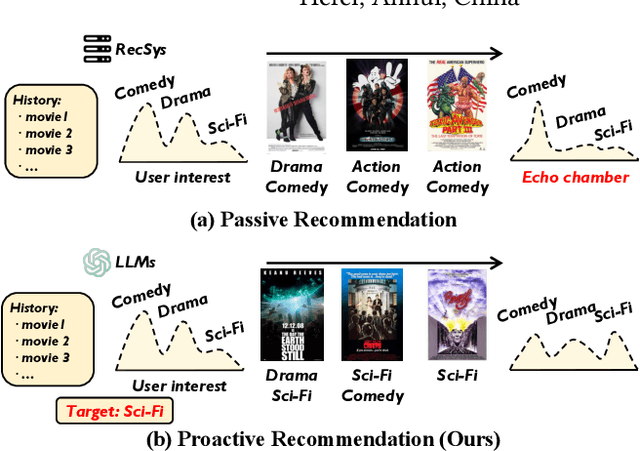
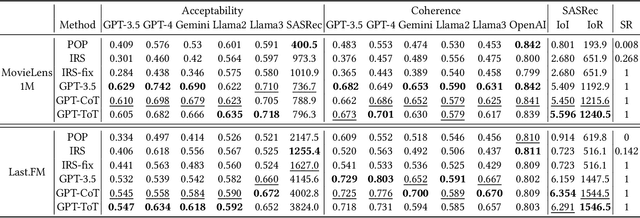
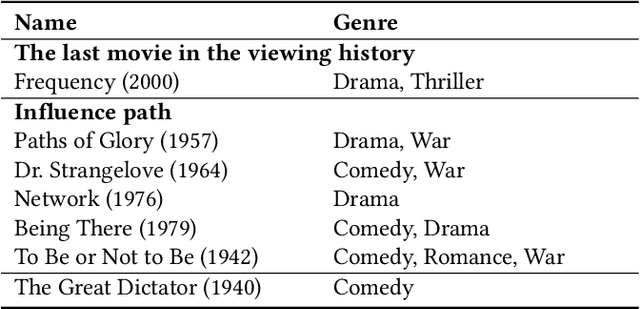
Recommender systems have achieved increasing accuracy over the years. However, this precision often leads users to narrow their interests, resulting in issues such as limited diversity and the creation of echo chambers. Current research addresses these challenges through proactive recommender systems by recommending a sequence of items (called influence path) to guide user interest in the target item. However, existing methods struggle to construct a coherent influence path that builds up with items the user is likely to enjoy. In this paper, we leverage the Large Language Model's (LLMs) exceptional ability for path planning and instruction following, introducing a novel approach named LLM-based Influence Path Planning (LLM-IPP). Our approach maintains coherence between consecutive recommendations and enhances user acceptability of the recommended items. To evaluate LLM-IPP, we implement various user simulators and metrics to measure user acceptability and path coherence. Experimental results demonstrate that LLM-IPP significantly outperforms traditional proactive recommender systems. This study pioneers the integration of LLMs into proactive recommender systems, offering a reliable and user-engaging methodology for future recommendation technologies.
Are AI-Generated Text Detectors Robust to Adversarial Perturbations?
Jun 03, 2024



The widespread use of large language models (LLMs) has sparked concerns about the potential misuse of AI-generated text, as these models can produce content that closely resembles human-generated text. Current detectors for AI-generated text (AIGT) lack robustness against adversarial perturbations, with even minor changes in characters or words causing a reversal in distinguishing between human-created and AI-generated text. This paper investigates the robustness of existing AIGT detection methods and introduces a novel detector, the Siamese Calibrated Reconstruction Network (SCRN). The SCRN employs a reconstruction network to add and remove noise from text, extracting a semantic representation that is robust to local perturbations. We also propose a siamese calibration technique to train the model to make equally confidence predictions under different noise, which improves the model's robustness against adversarial perturbations. Experiments on four publicly available datasets show that the SCRN outperforms all baseline methods, achieving 6.5\%-18.25\% absolute accuracy improvement over the best baseline method under adversarial attacks. Moreover, it exhibits superior generalizability in cross-domain, cross-genre, and mixed-source scenarios. The code is available at \url{https://github.com/CarlanLark/Robust-AIGC-Detector}.
Improving Generalization and Convergence by Enhancing Implicit Regularization
May 31, 2024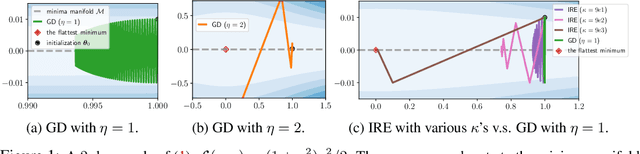
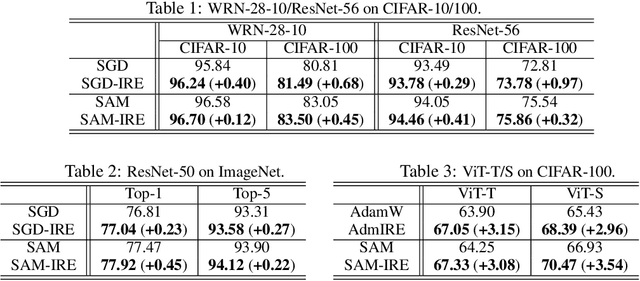
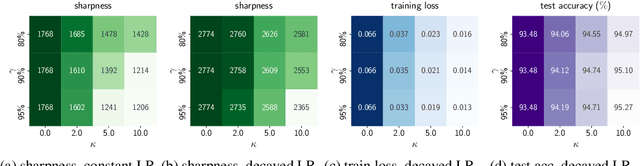
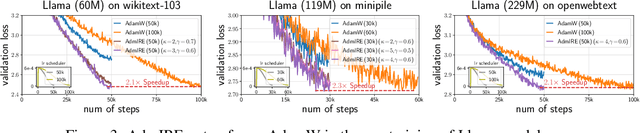
In this work, we propose an Implicit Regularization Enhancement (IRE) framework to accelerate the discovery of flat solutions in deep learning, thereby improving generalization and convergence. Specifically, IRE decouples the dynamics of flat and sharp directions, which boosts the sharpness reduction along flat directions while maintaining the training stability in sharp directions. We show that IRE can be practically incorporated with {\em generic base optimizers} without introducing significant computational overload. Experiments show that IRE consistently improves the generalization performance for image classification tasks across a variety of benchmark datasets (CIFAR-10/100, ImageNet) and models (ResNets and ViTs). Surprisingly, IRE also achieves a $2\times$ {\em speed-up} compared to AdamW in the pre-training of Llama models (of sizes ranging from 60M to 229M) on datasets including Wikitext-103, Minipile, and Openwebtext. Moreover, we provide theoretical guarantees, showing that IRE can substantially accelerate the convergence towards flat minima in Sharpness-aware Minimization (SAM).