 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Generalization and Convergence by Enhancing Implicit Regularization
Paper and Code
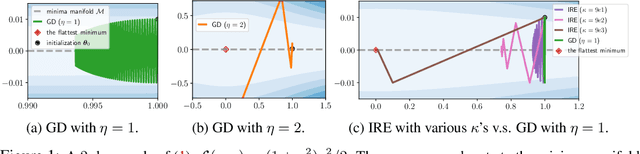
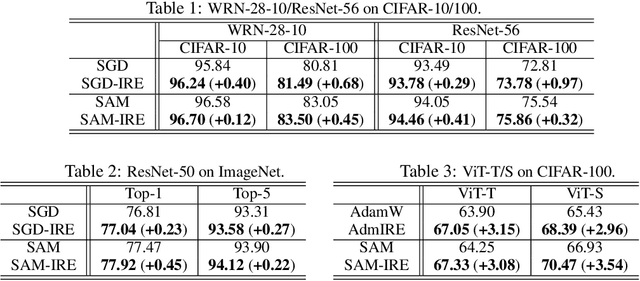
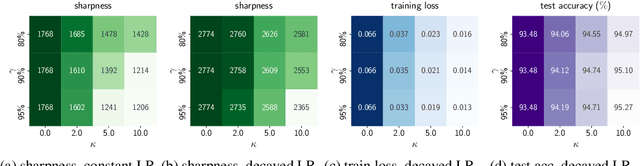
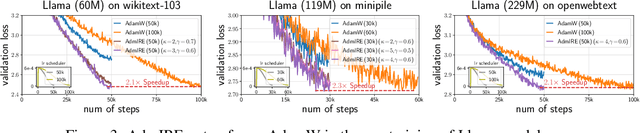
In this work, we propose an Implicit Regularization Enhancement (IRE) framework to accelerate the discovery of flat solutions in deep learning, thereby improving generalization and convergence. Specifically, IRE decouples the dynamics of flat and sharp directions, which boosts the sharpness reduction along flat directions while maintaining the training stability in sharp directions. We show that IRE can be practically incorporated with {\em generic base optimizers} without introducing significant computational overload. Experiments show that IRE consistently improves the generalization performance for image classification tasks across a variety of benchmark datasets (CIFAR-10/100, ImageNet) and models (ResNets and ViTs). Surprisingly, IRE also achieves a $2\times$ {\em speed-up} compared to AdamW in the pre-training of Llama models (of sizes ranging from 60M to 229M) on datasets including Wikitext-103, Minipile, and Openwebtext. Moreover, we provide theoretical guarantees, showing that IRE can substantially accelerate the convergence towards flat minima in Sharpness-aware Minimization (SAM).