 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen a Reinforcement Learning Agent Encounters Unknown Unknowns
May 19, 2025An AI agent might surprisingly find she has reached an unknown state which she has never been aware of -- an unknown unknown. We mathematically ground this scenario in reinforcement learning: an agent, after taking an action calculated from value functions $Q$ and $V$ defined on the {\it {aware domain}}, reaches a state out of the domain. To enable the agent to handle this scenario, we propose an {\it episodic Markov decision {process} with growing awareness} (EMDP-GA) model, taking a new {\it noninformative value expansion} (NIVE) approach to expand value functions to newly aware areas: when an agent arrives at an unknown unknown, value functions $Q$ and $V$ whereon are initialised by noninformative beliefs -- the averaged values on the aware domain. This design is out of respect for the complete absence of knowledge in the newly discovered state. The upper confidence bound momentum Q-learning is then adapted to the growing awareness for training the EMDP-GA model. We prove that (1) the regret of our approach is asymptotically consistent with the state of the art (SOTA) without exposure to unknown unknowns in an extremely uncertain environment, and (2) our computational complexity and space complexity are comparable with the SOTA -- these collectively suggest that though an unknown unknown is surprising, it will be asymptotically properly discovered with decent speed and an affordable cost.
Cross-Hierarchical Bidirectional Consistency Learning for Fine-Grained Visual Classification
Apr 18, 2025Fine-Grained Visual Classification (FGVC) aims to categorize closely related subclasses, a task complicated by minimal inter-class differences and significant intra-class variance. Existing methods often rely on additional annotations for image classification, overlooking the valuable information embedded in Tree Hierarchies that depict hierarchical label relationships. To leverage this knowledge to improve classification accuracy and consistency, we propose a novel Cross-Hierarchical Bidirectional Consistency Learning (CHBC) framework. The CHBC framework extracts discriminative features across various hierarchies using a specially designed module to decompose and enhance attention masks and features. We employ bidirectional consistency loss to regulate the classification outcomes across different hierarchies, ensuring label prediction consistency and reducing misclassification. Experiments on three widely used FGVC datasets validate the effectiveness of the CHBC framework. Ablation studies further investigate the application strategies of feature enhancement and consistency constraints, underscoring the significant contributions of the proposed modules.
Are AI-Generated Text Detectors Robust to Adversarial Perturbations?
Jun 03, 2024



The widespread use of large language models (LLMs) has sparked concerns about the potential misuse of AI-generated text, as these models can produce content that closely resembles human-generated text. Current detectors for AI-generated text (AIGT) lack robustness against adversarial perturbations, with even minor changes in characters or words causing a reversal in distinguishing between human-created and AI-generated text. This paper investigates the robustness of existing AIGT detection methods and introduces a novel detector, the Siamese Calibrated Reconstruction Network (SCRN). The SCRN employs a reconstruction network to add and remove noise from text, extracting a semantic representation that is robust to local perturbations. We also propose a siamese calibration technique to train the model to make equally confidence predictions under different noise, which improves the model's robustness against adversarial perturbations. Experiments on four publicly available datasets show that the SCRN outperforms all baseline methods, achieving 6.5\%-18.25\% absolute accuracy improvement over the best baseline method under adversarial attacks. Moreover, it exhibits superior generalizability in cross-domain, cross-genre, and mixed-source scenarios. The code is available at \url{https://github.com/CarlanLark/Robust-AIGC-Detector}.
Use square root affinity to regress labels in semantic segmentation
Mar 07, 2021


Semantic segmentation is a basic but non-trivial task in computer vision. Many previous work focus on utilizing affinity patterns to enhance segmentation networks. Most of these studies use the affinity matrix as a kind of feature fusion weights, which is part of modules embedded in the network, such as attention models and non-local models. In this paper, we associate affinity matrix with labels, exploiting the affinity in a supervised way. Specifically, we utilize the label to generate a multi-scale label affinity matrix as a structural supervision, and we use a square root kernel to compute a non-local affinity matrix on output layers. With such two affinities, we define a novel loss called Affinity Regression loss (AR loss), which can be an auxiliary loss providing pair-wise similarity penalty. Our model is easy to train and adds little computational burden without run-time inference. Extensive experiments on NYUv2 dataset and Cityscapes dataset demonstrate that our proposed method is sufficient in promoting semantic segmentation networks.
Multi-Instance Learning by Utilizing Structural Relationship among Instances
Feb 03, 2021



Multi-Instance Learning(MIL) aims to learn the mapping between a bag of instances and the bag-level label. Therefore, the relationships among instances are very important for learning the mapping. In this paper, we propose an MIL algorithm based on a graph built by structural relationship among instances within a bag. Then, Graph Convolutional Network(GCN) and the graph-attention mechanism are used to learn bag-embedding. In the task of medical image classification, our GCN-based MIL algorithm makes full use of the structural relationships among patches(instances) in an original image space domain, and experimental results verify that our method is more suitable for handling medical high-resolution images. We also verify experimentally that the proposed method achieves better results than previous methods on five bechmark MIL datasets and four medical image datasets.
A Group Norm Regularized LRR Factorization Model for Spectral Clustering
Jan 08, 2020
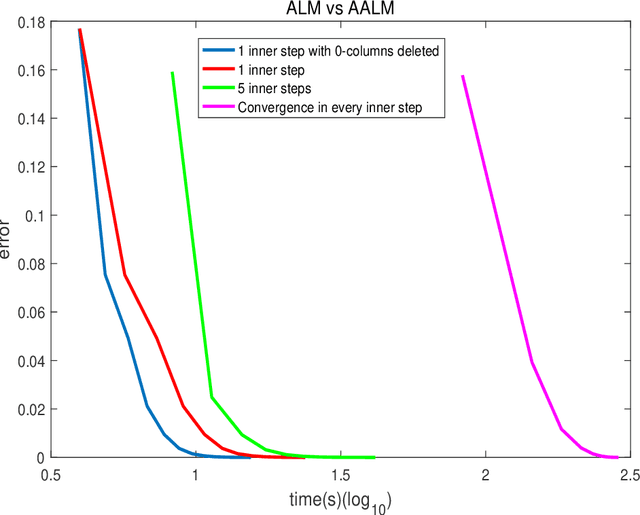


Spectral clustering is a very important and classic graph clustering method. Its clustering results are heavily dependent on affine matrix produced by data. Solving Low-Rank Representation~(LRR) problems is a very effective method to obtain affine matrix. This paper proposes LRR factorization model based on group norm regularization and uses Augmented Lagrangian Method~(ALM) algorithm to solve this model. We adopt group norm regularization to make the columns of the factor matrix sparse, thereby achieving the purpose of low rank. And no Singular Value Decomposition~(SVD) is required, computational complexity of each step is great reduced. We get the affine matrix by different LRR model and then perform cluster testing on synthetic noise data and real data~(Hopkin155 and EYaleB) respectively. Compared to traditional models and algorithms, ours are faster to solve affine matrix and more robust to noise. The final clustering results are better. And surprisingly, the numerical results show that our algorithm converges very fast, and the convergence condition is satisfied in only about ten steps. Group norm regularized LRR factorization model with the algorithm designed for it is effective and fast to obtain a better affine matrix.
Geometric Operator Convolutional Neural Network
Sep 04, 2018
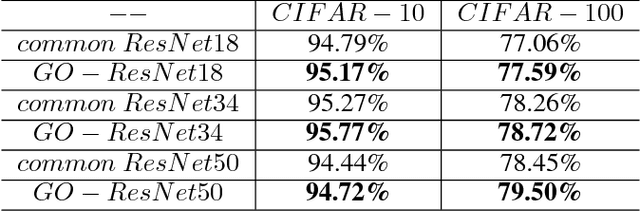
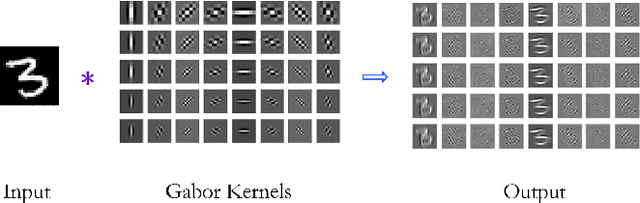
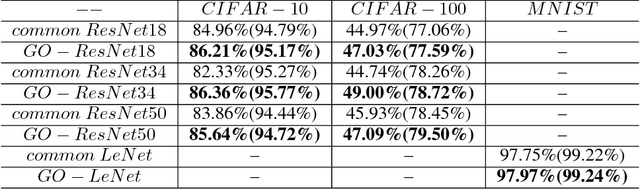
The Convolutional Neural Network (CNN) has been successfully applied in many fields during recent decades; however it lacks the ability to utilize prior domain knowledge when dealing with many realistic problems. We present a framework called Geometric Operator Convolutional Neural Network (GO-CNN) that uses domain knowledge, wherein the kernel of the first convolutional layer is replaced with a kernel generated by a geometric operator function. This framework integrates many conventional geometric operators, which allows it to adapt to a diverse range of problems. Under certain conditions, we theoretically analyze the convergence and the bound of the generalization errors between GO-CNNs and common CNNs. Although the geometric operator convolution kernels have fewer trainable parameters than common convolution kernels, the experimental results indicate that GO-CNN performs more accurately than common CNN on CIFAR-10/100. Furthermore, GO-CNN reduces dependence on the amount of training examples and enhances adversarial stability. In the practical task of medically diagnosing bone fractures, GO-CNN obtains 3% improvement in terms of the recall.
Video-based Person Re-identification via 3D Convolutional Networks and Non-local Attention
Jul 18, 2018



Video-based person re-identification (ReID) is a challenging problem, where some video tracks of people across non-overlapping cameras are available for matching. Feature aggregation from a video track is a key step for video-based person ReID. Many existing methods tackle this problem by average/maximum temporal pooling or RNNs with attention. However, these methods cannot deal with temporal dependency and spatial misalignment problems at the same time. We are inspired by video action recognition that involves the identification of different actions from video tracks. Firstly, we use 3D convolutions on video volume, instead of using 2D convolutions across frames, to extract spatial and temporal features simultaneously. Secondly, we use a non-local block to tackle the misalignment problem and capture spatial-temporal long-range dependencies. As a result, the network can learn useful spatial-temporal information as a weighted sum of the features in all space and temporal positions in the input feature map. Experimental results on three datasets show that our framework outperforms state-of-the-art approaches by a large margin on multiple metrics.