 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Estimation of Tea Flowering Based on an Improved YOLOv5 and ANN Model
Jan 25, 2025



Tea flowers play a crucial role in taxonomic research and hybrid breeding for the tea plant. Tea flowering consumes the plant's nutrients, and flower thinning can regulate carbon-nitrogen metabolism, enhancing the yield and quality of young shoots. As traditional methods of observing tea flower traits are labor-intensive and inaccurate, we propose an effective framework for tea flowering quantifying. In this study, a highly representative and diverse dataset was constructed by collecting flower images from 29 tea accessions. Based on this dataset, the TflosYOLO model was built on the YOLOv5 architecture and enhanced with the Squeeze-and-Excitation (SE) network, which is the first model to offer a viable solution for detecting tea flowers and predicting flower quantities. The TflosYOLO model achieved an mAP50 of 0.874, outperforming YOLOv5, YOLOv7 and YOLOv8. Furthermore, this model was tested on 34 datasets encompassing 26 tea accessions, five flowering stages, various lighting conditions, and pruned/unpruned plants, demonstrating high generalization and robustness. The correlation coefficient ($ R^2 $) between the predicted and actual flower counts was 0.974. Additionally, the TFSC (Tea Flowering Stage Classification) model - a novel Artificial Neural Network (ANN) was designed for automatic classification of the flowering stages. TFSC achieved an accuracy of 0.899. Dynamic analysis of flowering across 29 tea accessions in 2023 and 2024 was conducted, revealed significant variability in flower quantity and dynamics, with genetically similar accessions showing more consistent flowering patterns. This framework provides a solution for quantifying tea flowering, and can serve as a reference for precision horticulture.
RSBuilding: Towards General Remote Sensing Image Building Extraction and Change Detection with Foundation Model
Mar 12, 2024



The intelligent interpretation of buildings plays a significant role in urban planning and management, macroeconomic analysis, population dynamics, etc. Remote sensing image building interpretation primarily encompasses building extraction and change detection. However, current methodologies often treat these two tasks as separate entities, thereby failing to leverage shared knowledge. Moreover, the complexity and diversity of remote sensing image scenes pose additional challenges, as most algorithms are designed to model individual small datasets, thus lacking cross-scene generalization. In this paper, we propose a comprehensive remote sensing image building understanding model, termed RSBuilding, developed from the perspective of the foundation model. RSBuilding is designed to enhance cross-scene generalization and task universality. Specifically, we extract image features based on the prior knowledge of the foundation model and devise a multi-level feature sampler to augment scale information. To unify task representation and integrate image spatiotemporal clues, we introduce a cross-attention decoder with task prompts. Addressing the current shortage of datasets that incorporate annotations for both tasks, we have developed a federated training strategy to facilitate smooth model convergence even when supervision for some tasks is missing, thereby bolstering the complementarity of different tasks. Our model was trained on a dataset comprising up to 245,000 images and validated on multiple building extraction and change detection datasets. The experimental results substantiate that RSBuilding can concurrently handle two structurally distinct tasks and exhibits robust zero-shot generalization capabilities.
HS-ResNet: Hierarchical-Split Block on Convolutional Neural Network
Oct 15, 2020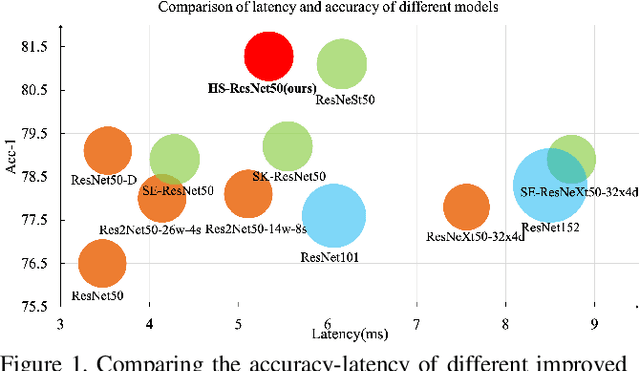
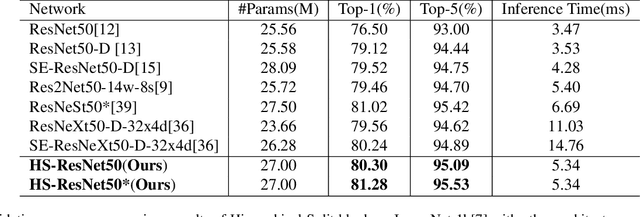
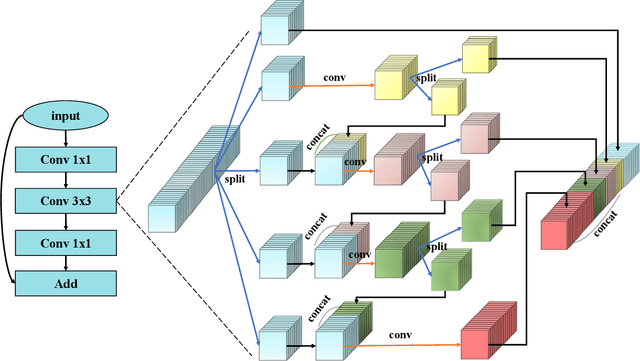

This paper addresses representational block named Hierarchical-Split Block, which can be taken as a plug-and-play block to upgrade existing convolutional neural networks, improves model performance significantly in a network. Hierarchical-Split Block contains many hierarchical split and concatenate connections within one single residual block. We find multi-scale features is of great importance for numerous vision tasks. Moreover, Hierarchical-Split block is very flexible and efficient, which provides a large space of potential network architectures for different applications. In this work, we present a common backbone based on Hierarchical-Split block for tasks: image classification, object detection, instance segmentation and semantic image segmentation/parsing. Our approach shows significant improvements over all these core tasks in comparison with the baseline. As shown in Figure1, for image classification, our 50-layers network(HS-ResNet50) achieves 81.28% top-1 accuracy with competitive latency on ImageNet-1k dataset. It also outperforms most state-of-the-art models. The source code and models will be available on: https://github.com/PaddlePaddle/PaddleClas
Hierarchical Deep Co-segmentation of Primary Objects in Aerial Videos
Nov 05, 2018


Primary object segmentation plays an important role in understanding videos generated by unmanned aerial vehicles. In this paper, we propose a large-scale dataset with 500 aerial videos and manually annotated primary objects. To the best of our knowledge, it is the largest dataset to date for primary object segmentation in aerial videos. From this dataset, we find most aerial videos contain large-scale scenes, small primary objects as well as consistently varying scales and viewpoints. Inspired by that, we propose a hierarchical deep co-segmentation approach that repeatedly divides a video into two sub-videos formed by the odd and even frames, respectively. In this manner, the primary objects shared by sub-videos can be co-segmented by training two-stream CNNs and finally refined within the neighborhood reversible flows. Experimental results show that our approach remarkably outperforms 17 state-of-the-art methods in segmenting primary objects in various types of aerial videos.
Learning from Large-scale Noisy Web Data with Ubiquitous Reweighting for Image Classification
Nov 02, 2018
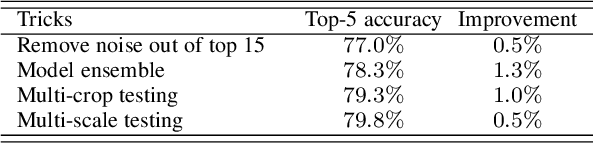


Many advances of deep learning techniques originate from the efforts of addressing the image classification task on large-scale datasets. However, the construction of such clean datasets is costly and time-consuming since the Internet is overwhelmed by noisy images with inadequate and inaccurate tags. In this paper, we propose a Ubiquitous Reweighting Network (URNet) that learns an image classification model from large-scale noisy data. By observing the web data, we find that there are five key challenges, \ie, imbalanced class sizes, high intra-classes diversity and inter-class similarity, imprecise instances, insufficient representative instances, and ambiguous class labels. To alleviate these challenges, we assume that every training instance has the potential to contribute positively by alleviating the data bias and noise via reweighting the influence of each instance according to different class sizes, large instance clusters, its confidence, small instance bags and the labels. In this manner, the influence of bias and noise in the web data can be gradually alleviated, leading to the steadily improving performance of URNet. Experimental results in the WebVision 2018 challenge with 16 million noisy training images from 5000 classes show that our approach outperforms state-of-the-art models and ranks the first place in the image classification task.