 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWiFT: Soft-Mask Weight Fine-tuning for Bias Mitigation
Aug 26, 2025Recent studies have shown that Machine Learning (ML) models can exhibit bias in real-world scenarios, posing significant challenges in ethically sensitive domains such as healthcare. Such bias can negatively affect model fairness, model generalization abilities and further risks amplifying social discrimination. There is a need to remove biases from trained models. Existing debiasing approaches often necessitate access to original training data and need extensive model retraining; they also typically exhibit trade-offs between model fairness and discriminative performance. To address these challenges, we propose Soft-Mask Weight Fine-Tuning (SWiFT), a debiasing framework that efficiently improves fairness while preserving discriminative performance with much less debiasing costs. Notably, SWiFT requires only a small external dataset and only a few epochs of model fine-tuning. The idea behind SWiFT is to first find the relative, and yet distinct, contributions of model parameters to both bias and predictive performance. Then, a two-step fine-tuning process updates each parameter with different gradient flows defined by its contribution. Extensive experiments with three bias sensitive attributes (gender, skin tone, and age) across four dermatological and two chest X-ray datasets demonstrate that SWiFT can consistently reduce model bias while achieving competitive or even superior diagnostic accuracy under common fairness and accuracy metrics, compared to the state-of-the-art. Specifically, we demonstrate improved model generalization ability as evidenced by superior performance on several out-of-distribution (OOD) datasets.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2025:015
Active Sampling for MRI-based Sequential Decision Making
May 07, 2025Despite the superior diagnostic capability of Magnetic Resonance Imaging (MRI), its use as a Point-of-Care (PoC) device remains limited by high cost and complexity. To enable such a future by reducing the magnetic field strength, one key approach will be to improve sampling strategies. Previous work has shown that it is possible to make diagnostic decisions directly from k-space with fewer samples. Such work shows that single diagnostic decisions can be made, but if we aspire to see MRI as a true PoC, multiple and sequential decisions are necessary while minimizing the number of samples acquired. We present a novel multi-objective reinforcement learning framework enabling comprehensive, sequential, diagnostic evaluation from undersampled k-space data. Our approach during inference actively adapts to sequential decisions to optimally sample. To achieve this, we introduce a training methodology that identifies the samples that contribute the best to each diagnostic objective using a step-wise weighting reward function. We evaluate our approach in two sequential knee pathology assessment tasks: ACL sprain detection and cartilage thickness loss assessment. Our framework achieves diagnostic performance competitive with various policy-based benchmarks on disease detection, severity quantification, and overall sequential diagnosis, while substantially saving k-space samples. Our approach paves the way for the future of MRI as a comprehensive and affordable PoC device. Our code is publicly available at https://github.com/vios-s/MRI_Sequential_Active_Sampling
PP-DocLayout: A Unified Document Layout Detection Model to Accelerate Large-Scale Data Construction
Mar 21, 2025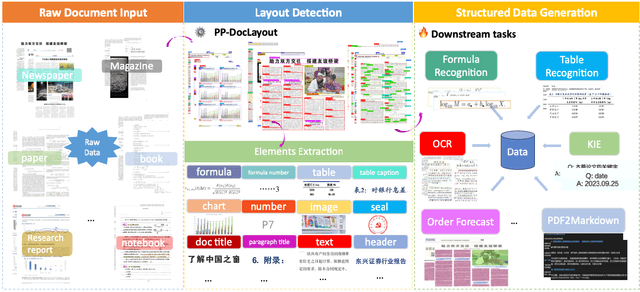

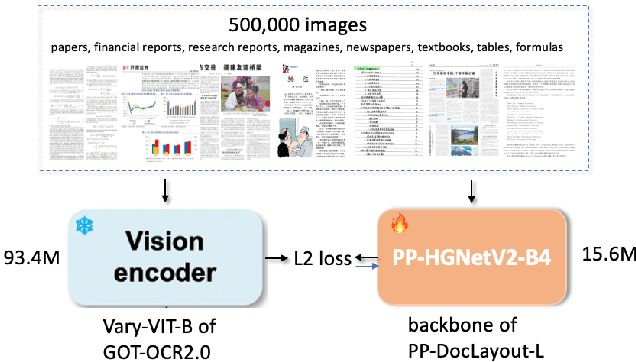

Document layout analysis is a critical preprocessing step in document intelligence, enabling the detection and localization of structural elements such as titles, text blocks, tables, and formulas. Despite its importance, existing layout detection models face significant challenges in generalizing across diverse document types, handling complex layouts, and achieving real-time performance for large-scale data processing. To address these limitations, we present PP-DocLayout, which achieves high precision and efficiency in recognizing 23 types of layout regions across diverse document formats. To meet different needs, we offer three models of varying scales. PP-DocLayout-L is a high-precision model based on the RT-DETR-L detector, achieving 90.4% mAP@0.5 and an end-to-end inference time of 13.4 ms per page on a T4 GPU. PP-DocLayout-M is a balanced model, offering 75.2% mAP@0.5 with an inference time of 12.7 ms per page on a T4 GPU. PP-DocLayout-S is a high-efficiency model designed for resource-constrained environments and real-time applications, with an inference time of 8.1 ms per page on a T4 GPU and 14.5 ms on a CPU. This work not only advances the state of the art in document layout analysis but also provides a robust solution for constructing high-quality training data, enabling advancements in document intelligence and multimodal AI systems. Code and models are available at https://github.com/PaddlePaddle/PaddleX .
The MRI Scanner as a Diagnostic: Image-less Active Sampling
Jun 24, 2024Despite the high diagnostic accuracy of Magnetic Resonance Imaging (MRI), using MRI as a Point-of-Care (POC) disease identification tool poses significant accessibility challenges due to the use of high magnetic field strength and lengthy acquisition times. We ask a simple question: Can we dynamically optimise acquired samples, at the patient level, according to an (automated) downstream decision task, while discounting image reconstruction? We propose an ML-based framework that learns an active sampling strategy, via reinforcement learning, at a patient-level to directly infer disease from undersampled k-space. We validate our approach by inferring Meniscus Tear in undersampled knee MRI data, where we achieve diagnostic performance comparable with ML-based diagnosis, using fully sampled k-space data. We analyse task-specific sampling policies, showcasing the adaptability of our active sampling approach. The introduced frugal sampling strategies have the potential to reduce high field strength requirements that in turn strengthen the viability of MRI-based POC disease identification and associated preliminary screening tools.
The state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 01, 2024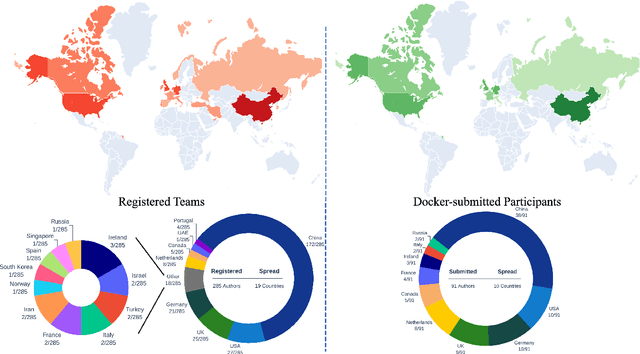
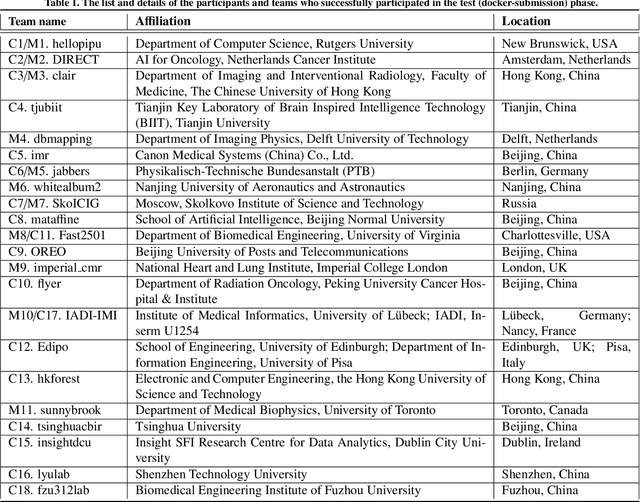
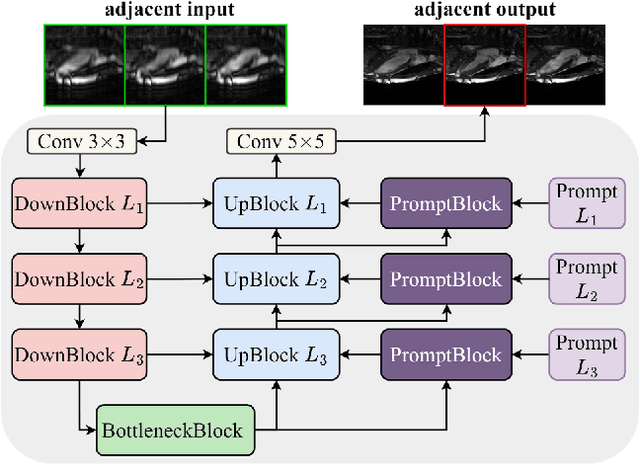
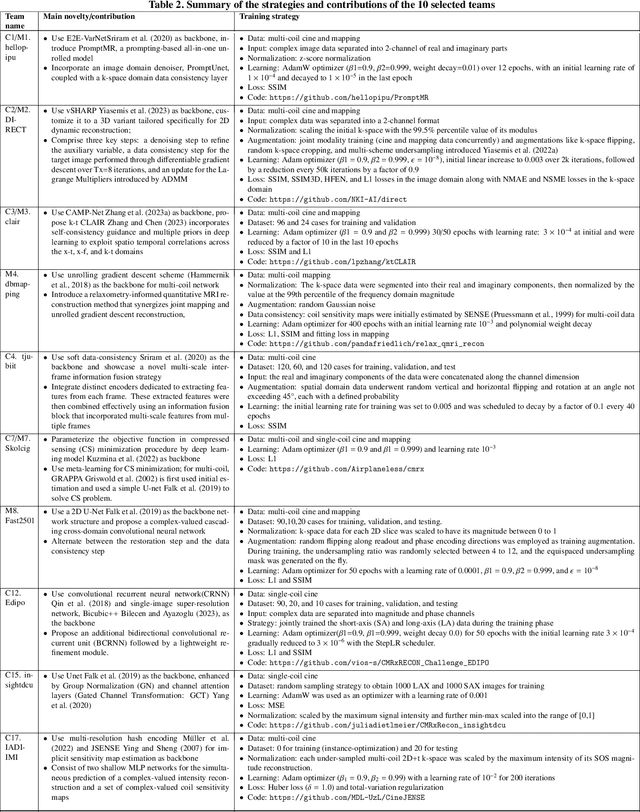
Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
Unveiling Fairness Biases in Deep Learning-Based Brain MRI Reconstruction
Sep 25, 2023Deep learning (DL) reconstruction particularly of MRI has led to improvements in image fidelity and reduction of acquisition time. In neuroimaging, DL methods can reconstruct high-quality images from undersampled data. However, it is essential to consider fairness in DL algorithms, particularly in terms of demographic characteristics. This study presents the first fairness analysis in a DL-based brain MRI reconstruction model. The model utilises the U-Net architecture for image reconstruction and explores the presence and sources of unfairness by implementing baseline Empirical Risk Minimisation (ERM) and rebalancing strategies. Model performance is evaluated using image reconstruction metrics. Our findings reveal statistically significant performance biases between the gender and age subgroups. Surprisingly, data imbalance and training discrimination are not the main sources of bias. This analysis provides insights of fairness in DL-based image reconstruction and aims to improve equity in medical AI applications.
Cine cardiac MRI reconstruction using a convolutional recurrent network with refinement
Sep 23, 2023Cine Magnetic Resonance Imaging (MRI) allows for understanding of the heart's function and condition in a non-invasive manner. Undersampling of the $k$-space is employed to reduce the scan duration, thus increasing patient comfort and reducing the risk of motion artefacts, at the cost of reduced image quality. In this challenge paper, we investigate the use of a convolutional recurrent neural network (CRNN) architecture to exploit temporal correlations in supervised cine cardiac MRI reconstruction. This is combined with a single-image super-resolution refinement module to improve single coil reconstruction by 4.4\% in structural similarity and 3.9\% in normalised mean square error compared to a plain CRNN implementation. We deploy a high-pass filter to our $\ell_1$ loss to allow greater emphasis on high-frequency details which are missing in the original data. The proposed model demonstrates considerable enhancements compared to the baseline case and holds promising potential for further improving cardiac MRI reconstruction.
Context Perception Parallel Decoder for Scene Text Recognition
Jul 23, 2023



Scene text recognition (STR) methods have struggled to attain high accuracy and fast inference speed. Autoregressive (AR)-based STR model uses the previously recognized characters to decode the next character iteratively. It shows superiority in terms of accuracy. However, the inference speed is slow also due to this iteration. Alternatively, parallel decoding (PD)-based STR model infers all the characters in a single decoding pass. It has advantages in terms of inference speed but worse accuracy, as it is difficult to build a robust recognition context in such a pass. In this paper, we first present an empirical study of AR decoding in STR. In addition to constructing a new AR model with the top accuracy, we find out that the success of AR decoder lies also in providing guidance on visual context perception rather than language modeling as claimed in existing studies. As a consequence, we propose Context Perception Parallel Decoder (CPPD) to decode the character sequence in a single PD pass. CPPD devises a character counting module and a character ordering module. Given a text instance, the former infers the occurrence count of each character, while the latter deduces the character reading order and placeholders. Together with the character prediction task, they construct a context that robustly tells what the character sequence is and where the characters appear, well mimicking the context conveyed by AR decoding. Experiments on both English and Chinese benchmarks demonstrate that CPPD models achieve highly competitive accuracy. Moreover, they run approximately 7x faster than their AR counterparts, and are also among the fastest recognizers. The code will be released soon.
ICDAR 2023 Competition on Structured Text Extraction from Visually-Rich Document Images
Jun 05, 2023Structured text extraction is one of the most valuable and challenging application directions in the field of Document AI. However, the scenarios of past benchmarks are limited, and the corresponding evaluation protocols usually focus on the submodules of the structured text extraction scheme. In order to eliminate these problems, we organized the ICDAR 2023 competition on Structured text extraction from Visually-Rich Document images (SVRD). We set up two tracks for SVRD including Track 1: HUST-CELL and Track 2: Baidu-FEST, where HUST-CELL aims to evaluate the end-to-end performance of Complex Entity Linking and Labeling, and Baidu-FEST focuses on evaluating the performance and generalization of Zero-shot / Few-shot Structured Text extraction from an end-to-end perspective. Compared to the current document benchmarks, our two tracks of competition benchmark enriches the scenarios greatly and contains more than 50 types of visually-rich document images (mainly from the actual enterprise applications). The competition opened on 30th December, 2022 and closed on 24th March, 2023. There are 35 participants and 91 valid submissions received for Track 1, and 15 participants and 26 valid submissions received for Track 2. In this report we will presents the motivation, competition datasets, task definition, evaluation protocol, and submission summaries. According to the performance of the submissions, we believe there is still a large gap on the expected information extraction performance for complex and zero-shot scenarios. It is hoped that this competition will attract many researchers in the field of CV and NLP, and bring some new thoughts to the field of Document AI.
DETRs Beat YOLOs on Real-time Object Detection
Apr 17, 2023



Recently, end-to-end transformer-based detectors (DETRs) have achieved remarkable performance. However, the issue of the high computational cost of DETRs has not been effectively addressed, limiting their practical application and preventing them from fully exploiting the benefits of no post-processing, such as non-maximum suppression (NMS). In this paper, we first analyze the influence of NMS in modern real-time object detectors on inference speed, and establish an end-to-end speed benchmark. To avoid the inference delay caused by NMS, we propose a Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge. Specifically, we design an efficient hybrid encoder to efficiently process multi-scale features by decoupling the intra-scale interaction and cross-scale fusion, and propose IoU-aware query selection to improve the initialization of object queries. In addition, our proposed detector supports flexibly adjustment of the inference speed by using different decoder layers without the need for retraining, which facilitates the practical application of real-time object detectors. Our RT-DETR-L achieves 53.0% AP on COCO val2017 and 114 FPS on T4 GPU, while RT-DETR-X achieves 54.8% AP and 74 FPS, outperforming all YOLO detectors of the same scale in both speed and accuracy. Furthermore, our RT-DETR-R50 achieves 53.1% AP and 108 FPS, outperforming DINO-Deformable-DETR-R50 by 2.2% AP in accuracy and by about 21 times in FPS. Source code and pretrained models will be available at PaddleDetection.