 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Reinforcing Multimodal Understanding and Generation with Dual Self-rewards
Jun 09, 2025Building upon large language models (LLMs), recent large multimodal models (LMMs) unify cross-model understanding and generation into a single framework. However, LMMs still struggle to achieve accurate image-text alignment, prone to generating text responses contradicting the visual input or failing to follow the text-to-image prompts. Current solutions require external supervision (e.g., human feedback or reward models) and only address unidirectional tasks-either understanding or generation. In this work, based on the observation that understanding and generation are inverse dual tasks, we introduce a self-supervised dual reward mechanism to reinforce the understanding and generation capabilities of LMMs. Specifically, we sample multiple outputs for a given input in one task domain, then reverse the input-output pairs to compute the dual likelihood of the model as self-rewards for optimization. Extensive experimental results on visual understanding and generation benchmarks demonstrate that our method can effectively enhance the performance of the model without any external supervision, especially achieving remarkable improvements in text-to-image tasks.
PP-DocBee: Improving Multimodal Document Understanding Through a Bag of Tricks
Mar 06, 2025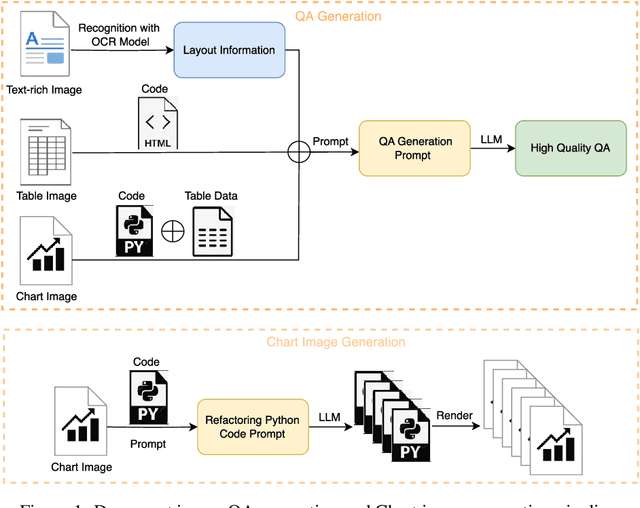

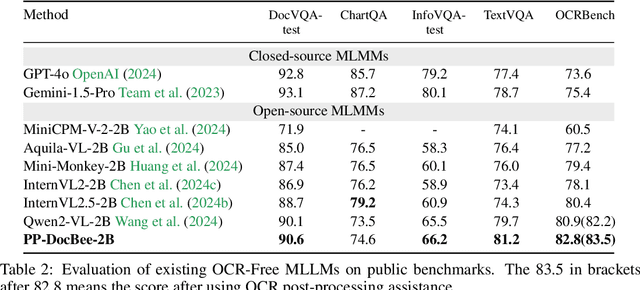
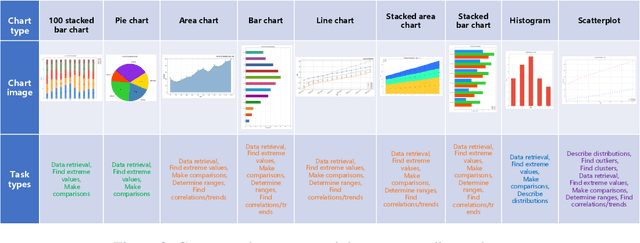
With the rapid advancement of digitalization, various document images are being applied more extensively in production and daily life, and there is an increasingly urgent need for fast and accurate parsing of the content in document images. Therefore, this report presents PP-DocBee, a novel multimodal large language model designed for end-to-end document image understanding. First, we develop a data synthesis strategy tailored to document scenarios in which we build a diverse dataset to improve the model generalization. Then, we apply a few training techniques, including dynamic proportional sampling, data preprocessing, and OCR postprocessing strategies. Extensive evaluations demonstrate the superior performance of PP-DocBee, achieving state-of-the-art results on English document understanding benchmarks and even outperforming existing open source and commercial models in Chinese document understanding. The source code and pre-trained models are publicly available at \href{https://github.com/PaddlePaddle/PaddleMIX}{https://github.com/PaddlePaddle/PaddleMIX}.
RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer
Jul 24, 2024In this report, we present RT-DETRv2, an improved Real-Time DEtection TRansformer (RT-DETR). RT-DETRv2 builds upon the previous state-of-the-art real-time detector, RT-DETR, and opens up a set of bag-of-freebies for flexibility and practicality, as well as optimizing the training strategy to achieve enhanced performance. To improve the flexibility, we suggest setting a distinct number of sampling points for features at different scales in the deformable attention to achieve selective multi-scale feature extraction by the decoder. To enhance practicality, we propose an optional discrete sampling operator to replace the grid_sample operator that is specific to RT-DETR compared to YOLOs. This removes the deployment constraints typically associated with DETRs. For the training strategy, we propose dynamic data augmentation and scale-adaptive hyperparameters customization to improve performance without loss of speed. Source code and pre-trained models will be available at https://github.com/lyuwenyu/RT-DETR.
DETRs Beat YOLOs on Real-time Object Detection
Apr 17, 2023



Recently, end-to-end transformer-based detectors (DETRs) have achieved remarkable performance. However, the issue of the high computational cost of DETRs has not been effectively addressed, limiting their practical application and preventing them from fully exploiting the benefits of no post-processing, such as non-maximum suppression (NMS). In this paper, we first analyze the influence of NMS in modern real-time object detectors on inference speed, and establish an end-to-end speed benchmark. To avoid the inference delay caused by NMS, we propose a Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge. Specifically, we design an efficient hybrid encoder to efficiently process multi-scale features by decoupling the intra-scale interaction and cross-scale fusion, and propose IoU-aware query selection to improve the initialization of object queries. In addition, our proposed detector supports flexibly adjustment of the inference speed by using different decoder layers without the need for retraining, which facilitates the practical application of real-time object detectors. Our RT-DETR-L achieves 53.0% AP on COCO val2017 and 114 FPS on T4 GPU, while RT-DETR-X achieves 54.8% AP and 74 FPS, outperforming all YOLO detectors of the same scale in both speed and accuracy. Furthermore, our RT-DETR-R50 achieves 53.1% AP and 108 FPS, outperforming DINO-Deformable-DETR-R50 by 2.2% AP in accuracy and by about 21 times in FPS. Source code and pretrained models will be available at PaddleDetection.
PP-YOLOE-R: An Efficient Anchor-Free Rotated Object Detector
Nov 04, 2022



Arbitrary-oriented object detection is a fundamental task in visual scenes involving aerial images and scene text. In this report, we present PP-YOLOE-R, an efficient anchor-free rotated object detector based on PP-YOLOE. We introduce a bag of useful tricks in PP-YOLOE-R to improve detection precision with marginal extra parameters and computational cost. As a result, PP-YOLOE-R-l and PP-YOLOE-R-x achieve 78.14 and 78.28 mAP respectively on DOTA 1.0 dataset with single-scale training and testing, which outperform almost all other rotated object detectors. With multi-scale training and testing, PP-YOLOE-R-l and PP-YOLOE-R-x further improve the detection precision to 80.02 and 80.73 mAP. In this case, PP-YOLOE-R-x surpasses all anchor-free methods and demonstrates competitive performance to state-of-the-art anchor-based two-stage models. Further, PP-YOLOE-R is deployment friendly and PP-YOLOE-R-s/m/l/x can reach 69.8/55.1/48.3/37.1 FPS respectively on RTX 2080 Ti with TensorRT and FP16-precision. Source code and pre-trained models are available at https://github.com/PaddlePaddle/PaddleDetection, which is powered by https://github.com/PaddlePaddle/Paddle.
PP-YOLOE: An evolved version of YOLO
Apr 02, 2022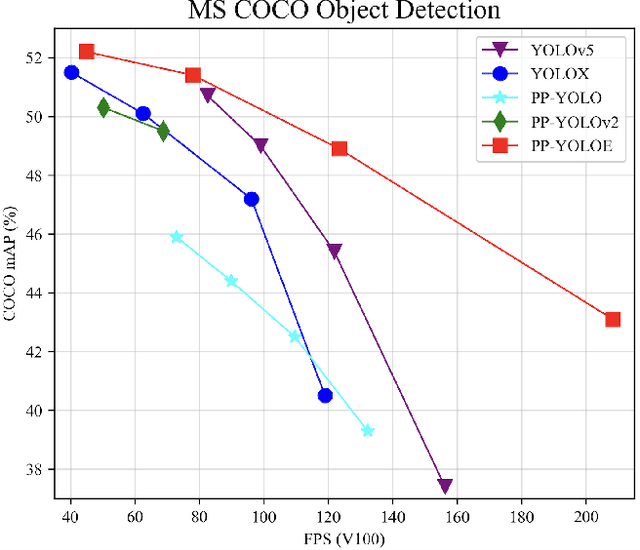

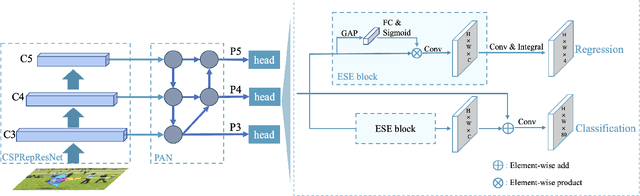

In this report, we present PP-YOLOE, an industrial state-of-the-art object detector with high performance and friendly deployment. We optimize on the basis of the previous PP-YOLOv2, using anchor-free paradigm, more powerful backbone and neck equipped with CSPRepResStage, ET-head and dynamic label assignment algorithm TAL. We provide s/m/l/x models for different practice scenarios. As a result, PP-YOLOE-l achieves 51.4 mAP on COCO test-dev and 78.1 FPS on Tesla V100, yielding a remarkable improvement of (+1.9 AP, +13.35% speed up) and (+1.3 AP, +24.96% speed up), compared to the previous state-of-the-art industrial models PP-YOLOv2 and YOLOX respectively. Further, PP-YOLOE inference speed achieves 149.2 FPS with TensorRT and FP16-precision. We also conduct extensive experiments to verify the effectiveness of our designs. Source code and pre-trained models are available at https://github.com/PaddlePaddle/PaddleDetection.
PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices
Nov 01, 2021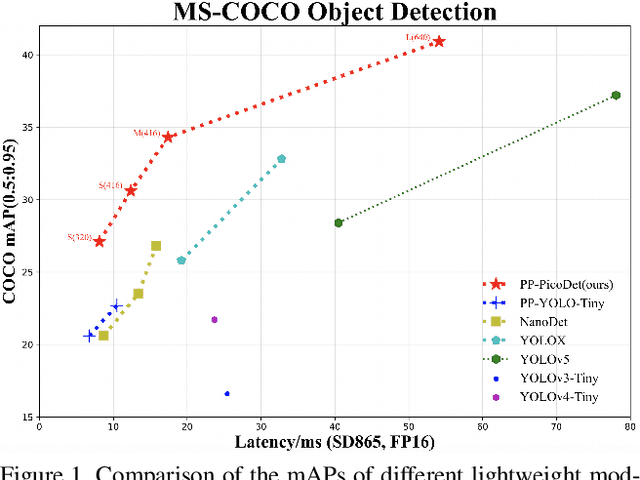
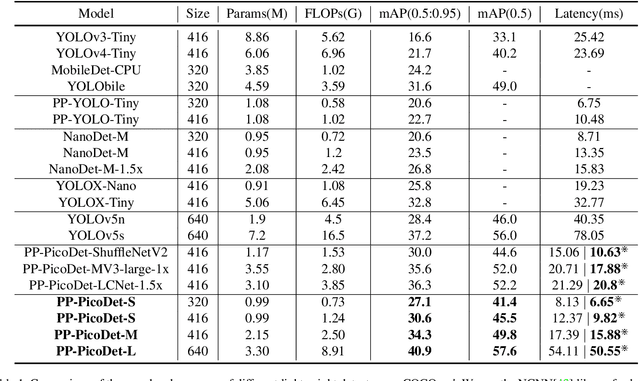
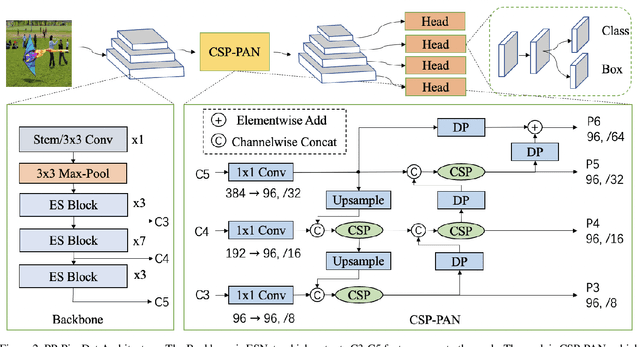
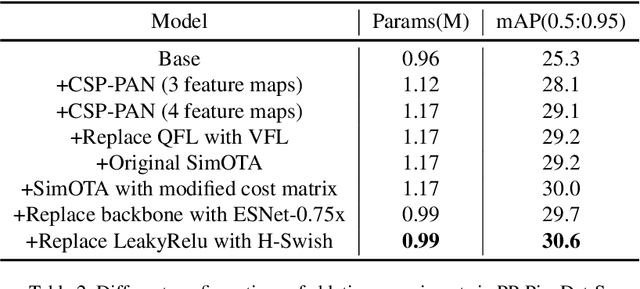
The better accuracy and efficiency trade-off has been a challenging problem in object detection. In this work, we are dedicated to studying key optimizations and neural network architecture choices for object detection to improve accuracy and efficiency. We investigate the applicability of the anchor-free strategy on lightweight object detection models. We enhance the backbone structure and design the lightweight structure of the neck, which improves the feature extraction ability of the network. We improve label assignment strategy and loss function to make training more stable and efficient. Through these optimizations, we create a new family of real-time object detectors, named PP-PicoDet, which achieves superior performance on object detection for mobile devices. Our models achieve better trade-offs between accuracy and latency compared to other popular models. PicoDet-S with only 0.99M parameters achieves 30.6% mAP, which is an absolute 4.8% improvement in mAP while reducing mobile CPU inference latency by 55% compared to YOLOX-Nano, and is an absolute 7.1% improvement in mAP compared to NanoDet. It reaches 123 FPS (150 FPS using Paddle Lite) on mobile ARM CPU when the input size is 320. PicoDet-L with only 3.3M parameters achieves 40.9% mAP, which is an absolute 3.7% improvement in mAP and 44% faster than YOLOv5s. As shown in Figure 1, our models far outperform the state-of-the-art results for lightweight object detection. Code and pre-trained models are available at https://github.com/PaddlePaddle/PaddleDetection.
PAFNet: An Efficient Anchor-Free Object Detector Guidance
Apr 28, 2021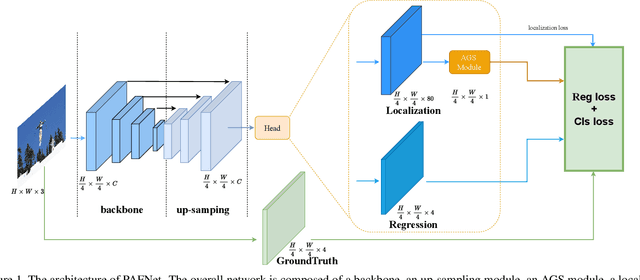
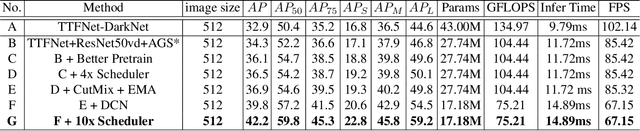
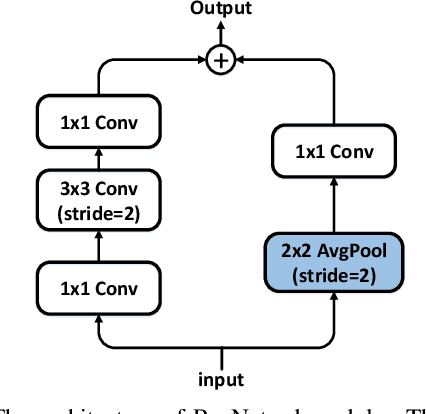

Object detection is a basic but challenging task in computer vision, which plays a key role in a variety of industrial applications. However, object detectors based on deep learning usually require greater storage requirements and longer inference time, which hinders its practicality seriously. Therefore, a trade-off between effectiveness and efficiency is necessary in practical scenarios. Considering that without constraint of pre-defined anchors, anchor-free detectors can achieve acceptable accuracy and inference speed simultaneously. In this paper, we start from an anchor-free detector called TTFNet, modify the structure of TTFNet and introduce multiple existing tricks to realize effective server and mobile solutions respectively. Since all experiments in this paper are conducted based on PaddlePaddle, we call the model as PAFNet(Paddle Anchor Free Network). For server side, PAFNet can achieve a better balance between effectiveness (42.2% mAP) and efficiency (67.15 FPS) on a single V100 GPU. For moblie side, PAFNet-lite can achieve a better accuracy of (23.9% mAP) and 26.00 ms on Kirin 990 ARM CPU, outperforming the existing state-of-the-art anchor-free detectors by significant margins. Source code is at https://github.com/PaddlePaddle/PaddleDetection.
PP-YOLO: An Effective and Efficient Implementation of Object Detector
Aug 03, 2020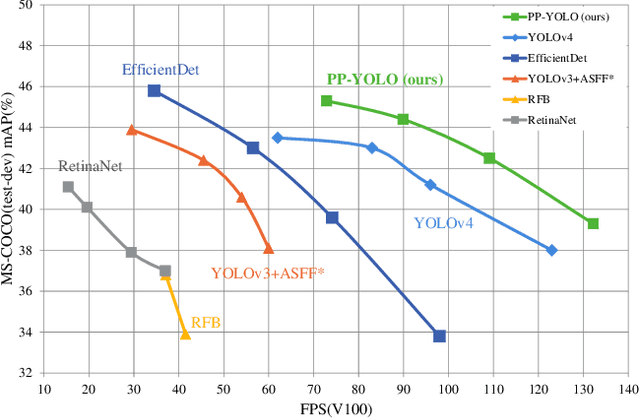
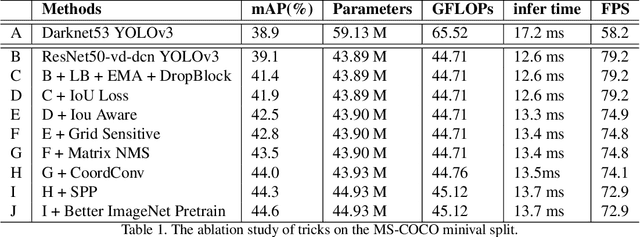
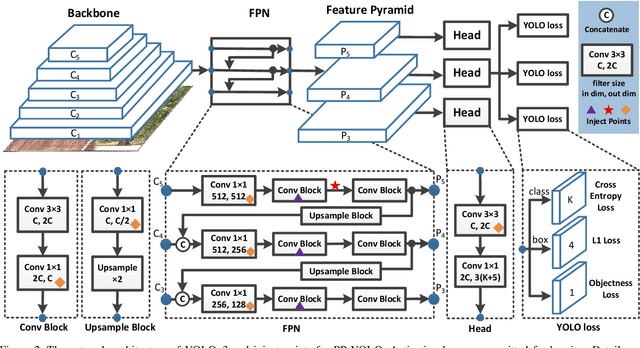
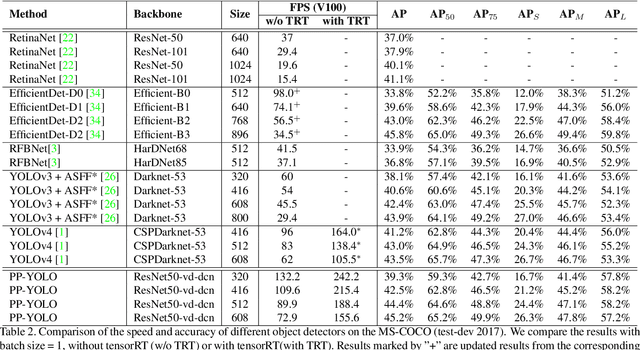
Object detection is one of the most important areas in computer vision, which plays a key role in various practical scenarios. Due to limitation of hardware, it is often necessary to sacrifice accuracy to ensure the infer speed of the detector in practice. Therefore, the balance between effectiveness and efficiency of object detector must be considered. The goal of this paper is to implement an object detector with relatively balanced effectiveness and efficiency that can be directly applied in actual application scenarios, rather than propose a novel detection model. Considering that YOLOv3 has been widely used in practice, we develop a new object detector based on YOLOv3. We mainly try to combine various existing tricks that almost not increase the number of model parameters and FLOPs, to achieve the goal of improving the accuracy of detector as much as possible while ensuring that the speed is almost unchanged. Since all experiments in this paper are conducted based on PaddlePaddle, we call it PP-YOLO. By combining multiple tricks, PP-YOLO can achieve a better balance between effectiveness (45.2% mAP) and efficiency (72.9 FPS), surpassing the existing state-of-the-art detectors such as EfficientDet and YOLOv4.Source code is at https://github.com/PaddlePaddle/PaddleDetection.