 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing Multimodal Understanding and Generation with Dual Self-rewards
Jun 09, 2025Building upon large language models (LLMs), recent large multimodal models (LMMs) unify cross-model understanding and generation into a single framework. However, LMMs still struggle to achieve accurate image-text alignment, prone to generating text responses contradicting the visual input or failing to follow the text-to-image prompts. Current solutions require external supervision (e.g., human feedback or reward models) and only address unidirectional tasks-either understanding or generation. In this work, based on the observation that understanding and generation are inverse dual tasks, we introduce a self-supervised dual reward mechanism to reinforce the understanding and generation capabilities of LMMs. Specifically, we sample multiple outputs for a given input in one task domain, then reverse the input-output pairs to compute the dual likelihood of the model as self-rewards for optimization. Extensive experimental results on visual understanding and generation benchmarks demonstrate that our method can effectively enhance the performance of the model without any external supervision, especially achieving remarkable improvements in text-to-image tasks.
LiveIdeaBench: Evaluating LLMs' Scientific Creativity and Idea Generation with Minimal Context
Dec 23, 2024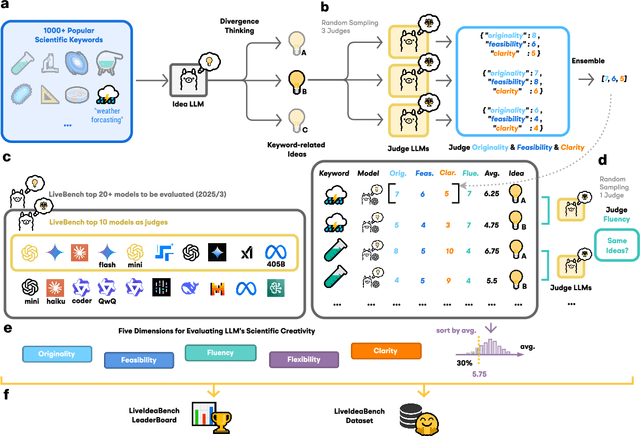
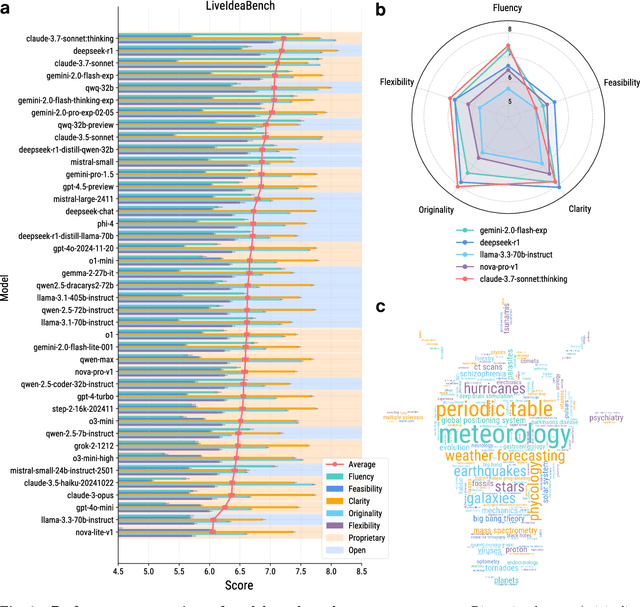
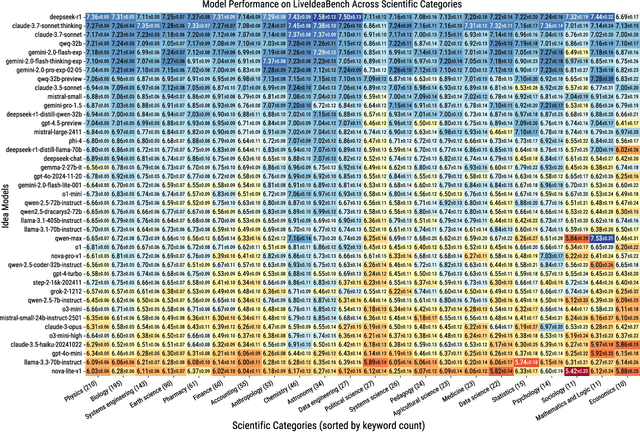
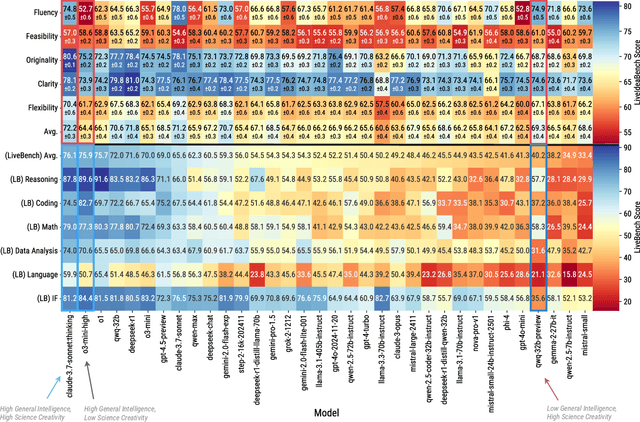
While Large Language Models (LLMs) have demonstrated remarkable capabilities in scientific tasks, existing evaluation frameworks primarily assess their performance using rich contextual inputs, overlooking their ability to generate novel ideas from minimal information. We introduce LiveIdeaBench, a comprehensive benchmark that evaluates LLMs' scientific creativity and divergent thinking capabilities using single-keyword prompts. Drawing from Guilford's creativity theory, our framework employs a dynamic panel of state-of-the-art LLMs to assess generated ideas across four key dimensions: originality, feasibility, fluency, and flexibility. Through extensive experimentation with 20 leading models across 1,180 keywords spanning 18 scientific domains, we reveal that scientific creative ability shows distinct patterns from general intelligence metrics. Notably, our results demonstrate that models like QwQ-32B-preview achieve comparable creative performance to top-tier models like o1-preview, despite significant gaps in their general intelligence scores. These findings highlight the importance of specialized evaluation frameworks for scientific creativity and suggest that the development of creative capabilities in LLMs may follow different trajectories than traditional problem-solving abilities.
CycleAlign: Iterative Distillation from Black-box LLM to White-box Models for Better Human Alignment
Oct 25, 2023
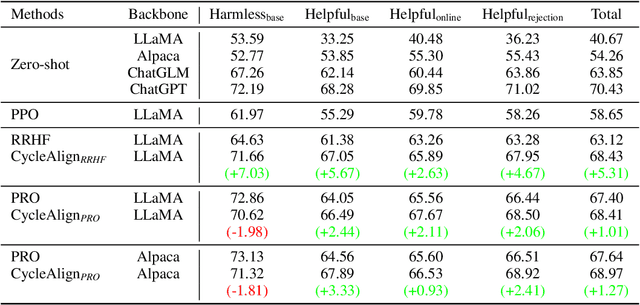


Language models trained on large-scale corpus often generate content that is harmful, toxic, or contrary to human preferences, making their alignment with human values a critical concern. Reinforcement learning from human feedback (RLHF) with algorithms like PPO is a prevalent approach for alignment but is often complex, unstable, and resource-intensive. Recently, ranking-based alignment methods have emerged, offering stability and effectiveness by replacing the RL framework with supervised fine-tuning, but they are costly due to the need for annotated data. Considering that existing large language models (LLMs) like ChatGPT are already relatively well-aligned and cost-friendly, researchers have begun to align the language model with human preference from AI feedback. The common practices, which unidirectionally distill the instruction-following responses from LLMs, are constrained by their bottleneck. Thus we introduce CycleAlign to distill alignment capabilities from parameter-invisible LLMs (black-box) to a parameter-visible model (white-box) in an iterative manner. With in-context learning (ICL) as the core of the cycle, the black-box models are able to rank the model-generated responses guided by human-craft instruction and demonstrations about their preferences. During iterative interaction, the white-box models also have a judgment about responses generated by them. Consequently, the agreement ranking could be viewed as a pseudo label to dynamically update the in-context demonstrations and improve the preference ranking ability of black-box models. Through multiple interactions, the CycleAlign framework could align the white-box model with the black-box model effectively in a low-resource way. Empirical results illustrate that the model fine-tuned by CycleAlign remarkably exceeds existing methods, and achieves the state-of-the-art performance in alignment with human value.