 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleAlign: Iterative Distillation from Black-box LLM to White-box Models for Better Human Alignment
Paper and Code

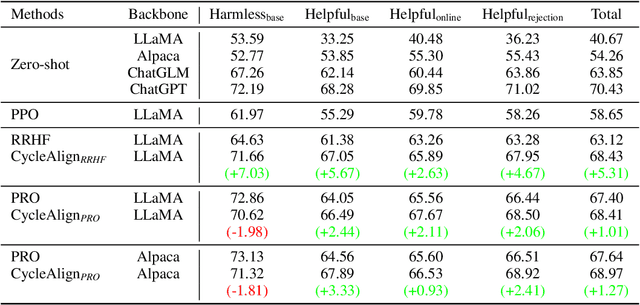


Language models trained on large-scale corpus often generate content that is harmful, toxic, or contrary to human preferences, making their alignment with human values a critical concern. Reinforcement learning from human feedback (RLHF) with algorithms like PPO is a prevalent approach for alignment but is often complex, unstable, and resource-intensive. Recently, ranking-based alignment methods have emerged, offering stability and effectiveness by replacing the RL framework with supervised fine-tuning, but they are costly due to the need for annotated data. Considering that existing large language models (LLMs) like ChatGPT are already relatively well-aligned and cost-friendly, researchers have begun to align the language model with human preference from AI feedback. The common practices, which unidirectionally distill the instruction-following responses from LLMs, are constrained by their bottleneck. Thus we introduce CycleAlign to distill alignment capabilities from parameter-invisible LLMs (black-box) to a parameter-visible model (white-box) in an iterative manner. With in-context learning (ICL) as the core of the cycle, the black-box models are able to rank the model-generated responses guided by human-craft instruction and demonstrations about their preferences. During iterative interaction, the white-box models also have a judgment about responses generated by them. Consequently, the agreement ranking could be viewed as a pseudo label to dynamically update the in-context demonstrations and improve the preference ranking ability of black-box models. Through multiple interactions, the CycleAlign framework could align the white-box model with the black-box model effectively in a low-resource way. Empirical results illustrate that the model fine-tuned by CycleAlign remarkably exceeds existing methods, and achieves the state-of-the-art performance in alignment with human value.