 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePP-YOLOE: An evolved version of YOLO
Apr 02, 2022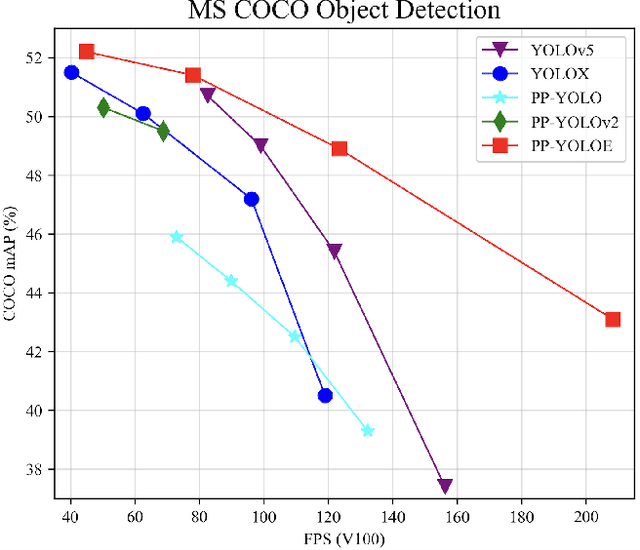

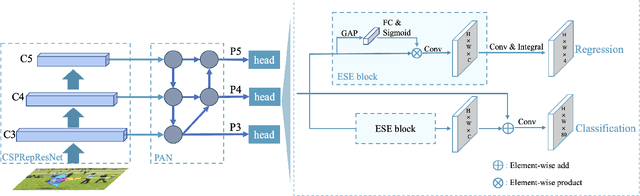

In this report, we present PP-YOLOE, an industrial state-of-the-art object detector with high performance and friendly deployment. We optimize on the basis of the previous PP-YOLOv2, using anchor-free paradigm, more powerful backbone and neck equipped with CSPRepResStage, ET-head and dynamic label assignment algorithm TAL. We provide s/m/l/x models for different practice scenarios. As a result, PP-YOLOE-l achieves 51.4 mAP on COCO test-dev and 78.1 FPS on Tesla V100, yielding a remarkable improvement of (+1.9 AP, +13.35% speed up) and (+1.3 AP, +24.96% speed up), compared to the previous state-of-the-art industrial models PP-YOLOv2 and YOLOX respectively. Further, PP-YOLOE inference speed achieves 149.2 FPS with TensorRT and FP16-precision. We also conduct extensive experiments to verify the effectiveness of our designs. Source code and pre-trained models are available at https://github.com/PaddlePaddle/PaddleDetection.
PP-ShiTu: A Practical Lightweight Image Recognition System
Nov 01, 2021
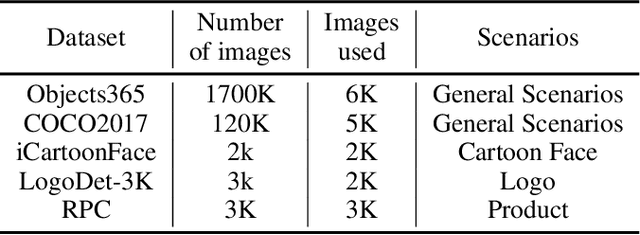
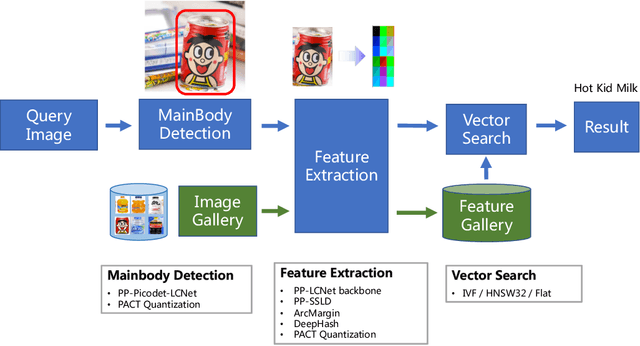
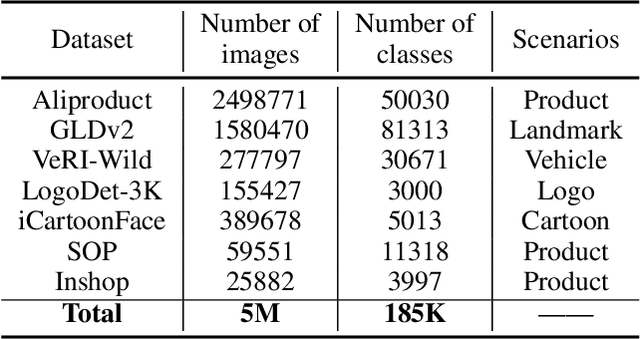
In recent years, image recognition applications have developed rapidly. A large number of studies and techniques have emerged in different fields, such as face recognition, pedestrian and vehicle re-identification, landmark retrieval, and product recognition. In this paper, we propose a practical lightweight image recognition system, named PP-ShiTu, consisting of the following 3 modules, mainbody detection, feature extraction and vector search. We introduce popular strategies including metric learning, deep hash, knowledge distillation and model quantization to improve accuracy and inference speed. With strategies above, PP-ShiTu works well in different scenarios with a set of models trained on a mixed dataset. Experiments on different datasets and benchmarks show that the system is widely effective in different domains of image recognition. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleClas on PaddlePaddle.
PP-LCNet: A Lightweight CPU Convolutional Neural Network
Sep 17, 2021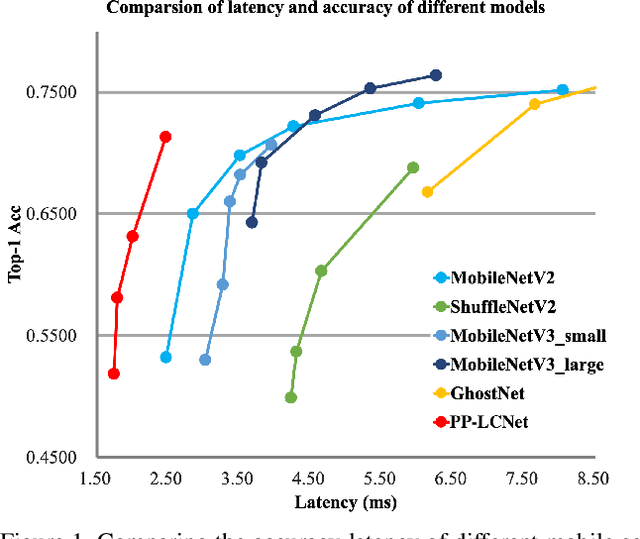
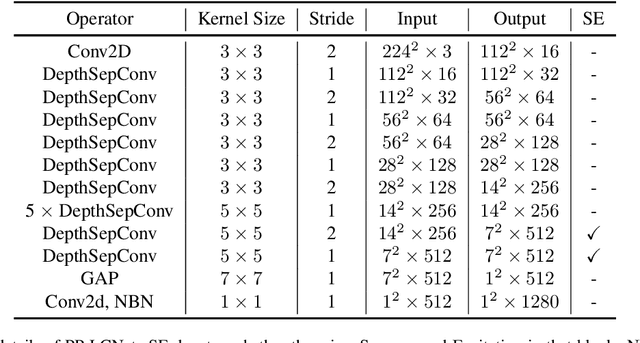
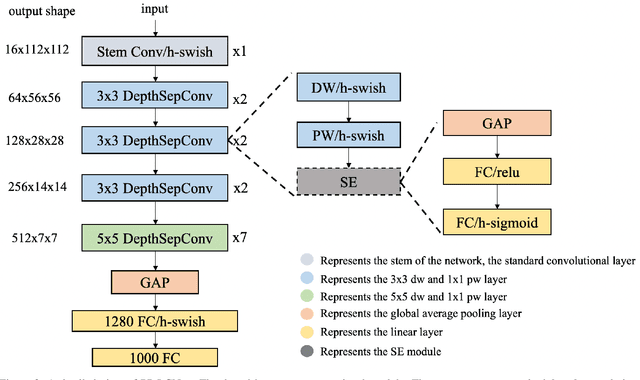
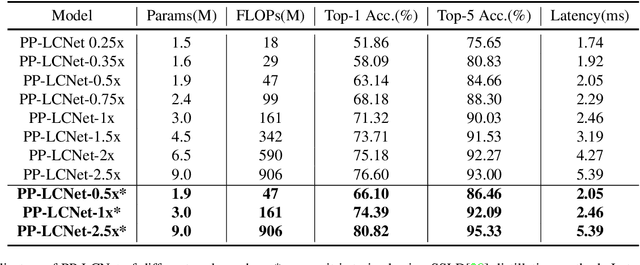
We propose a lightweight CPU network based on the MKLDNN acceleration strategy, named PP-LCNet, which improves the performance of lightweight models on multiple tasks. This paper lists technologies which can improve network accuracy while the latency is almost constant. With these improvements, the accuracy of PP-LCNet can greatly surpass the previous network structure with the same inference time for classification. As shown in Figure 1, it outperforms the most state-of-the-art models. And for downstream tasks of computer vision, it also performs very well, such as object detection, semantic segmentation, etc. All our experiments are implemented based on PaddlePaddle. Code and pretrained models are available at PaddleClas.