 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOD-SA: Infrared-Visible Decoupled Object Detection with Single-Modality Annotations
Aug 14, 2025Infrared-visible object detection has shown great potential in real-world applications, enabling robust all-day perception by leveraging the complementary information of infrared and visible images. However, existing methods typically require dual-modality annotations to output detection results for both modalities during prediction, which incurs high annotation costs. To address this challenge, we propose a novel infrared-visible Decoupled Object Detection framework with Single-modality Annotations, called DOD-SA. The architecture of DOD-SA is built upon a Single- and Dual-Modality Collaborative Teacher-Student Network (CoSD-TSNet), which consists of a single-modality branch (SM-Branch) and a dual-modality decoupled branch (DMD-Branch). The teacher model generates pseudo-labels for the unlabeled modality, simultaneously supporting the training of the student model. The collaborative design enables cross-modality knowledge transfer from the labeled modality to the unlabeled modality, and facilitates effective SM-to-DMD branch supervision. To further improve the decoupling ability of the model and the pseudo-label quality, we introduce a Progressive and Self-Tuning Training Strategy (PaST) that trains the model in three stages: (1) pretraining SM-Branch, (2) guiding the learning of DMD-Branch by SM-Branch, and (3) refining DMD-Branch. In addition, we design a Pseudo Label Assigner (PLA) to align and pair labels across modalities, explicitly addressing modality misalignment during training. Extensive experiments on the DroneVehicle dataset demonstrate that our method outperforms state-of-the-art (SOTA).
RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer
Jul 24, 2024In this report, we present RT-DETRv2, an improved Real-Time DEtection TRansformer (RT-DETR). RT-DETRv2 builds upon the previous state-of-the-art real-time detector, RT-DETR, and opens up a set of bag-of-freebies for flexibility and practicality, as well as optimizing the training strategy to achieve enhanced performance. To improve the flexibility, we suggest setting a distinct number of sampling points for features at different scales in the deformable attention to achieve selective multi-scale feature extraction by the decoder. To enhance practicality, we propose an optional discrete sampling operator to replace the grid_sample operator that is specific to RT-DETR compared to YOLOs. This removes the deployment constraints typically associated with DETRs. For the training strategy, we propose dynamic data augmentation and scale-adaptive hyperparameters customization to improve performance without loss of speed. Source code and pre-trained models will be available at https://github.com/lyuwenyu/RT-DETR.
PP-YOLOE: An evolved version of YOLO
Apr 02, 2022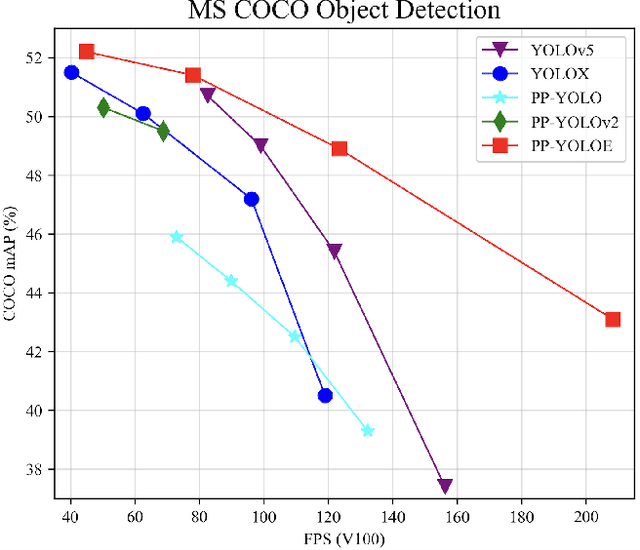

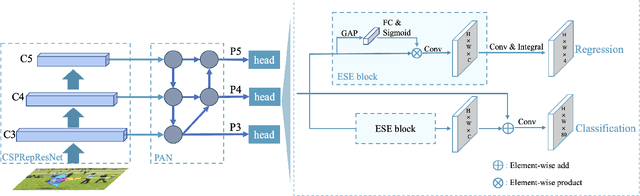

In this report, we present PP-YOLOE, an industrial state-of-the-art object detector with high performance and friendly deployment. We optimize on the basis of the previous PP-YOLOv2, using anchor-free paradigm, more powerful backbone and neck equipped with CSPRepResStage, ET-head and dynamic label assignment algorithm TAL. We provide s/m/l/x models for different practice scenarios. As a result, PP-YOLOE-l achieves 51.4 mAP on COCO test-dev and 78.1 FPS on Tesla V100, yielding a remarkable improvement of (+1.9 AP, +13.35% speed up) and (+1.3 AP, +24.96% speed up), compared to the previous state-of-the-art industrial models PP-YOLOv2 and YOLOX respectively. Further, PP-YOLOE inference speed achieves 149.2 FPS with TensorRT and FP16-precision. We also conduct extensive experiments to verify the effectiveness of our designs. Source code and pre-trained models are available at https://github.com/PaddlePaddle/PaddleDetection.
PP-PicoDet: A Better Real-Time Object Detector on Mobile Devices
Nov 01, 2021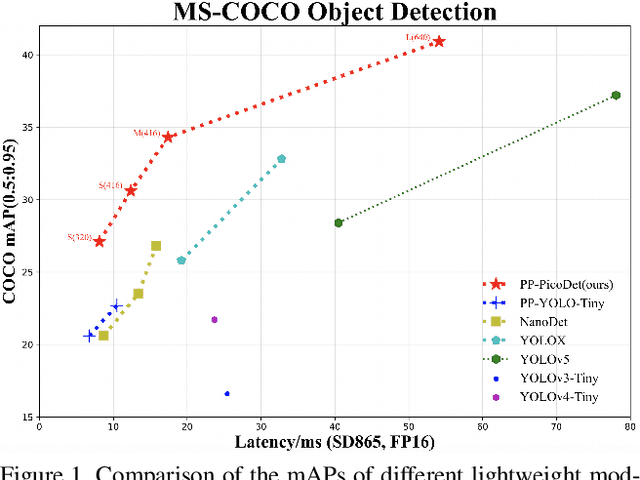
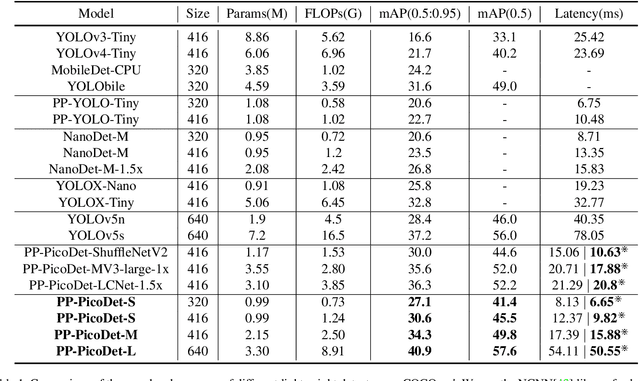
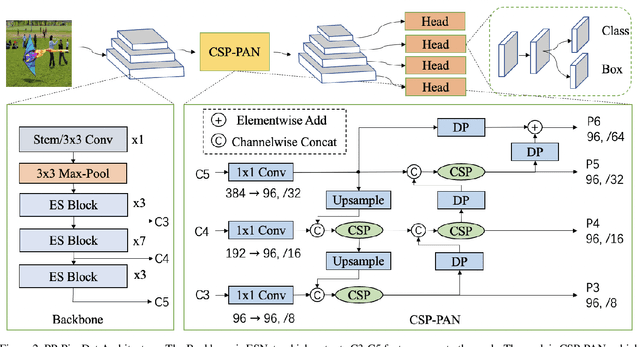
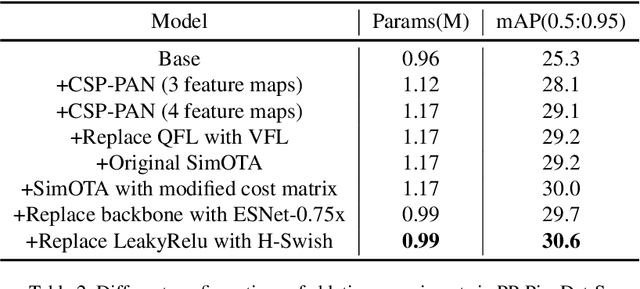
The better accuracy and efficiency trade-off has been a challenging problem in object detection. In this work, we are dedicated to studying key optimizations and neural network architecture choices for object detection to improve accuracy and efficiency. We investigate the applicability of the anchor-free strategy on lightweight object detection models. We enhance the backbone structure and design the lightweight structure of the neck, which improves the feature extraction ability of the network. We improve label assignment strategy and loss function to make training more stable and efficient. Through these optimizations, we create a new family of real-time object detectors, named PP-PicoDet, which achieves superior performance on object detection for mobile devices. Our models achieve better trade-offs between accuracy and latency compared to other popular models. PicoDet-S with only 0.99M parameters achieves 30.6% mAP, which is an absolute 4.8% improvement in mAP while reducing mobile CPU inference latency by 55% compared to YOLOX-Nano, and is an absolute 7.1% improvement in mAP compared to NanoDet. It reaches 123 FPS (150 FPS using Paddle Lite) on mobile ARM CPU when the input size is 320. PicoDet-L with only 3.3M parameters achieves 40.9% mAP, which is an absolute 3.7% improvement in mAP and 44% faster than YOLOv5s. As shown in Figure 1, our models far outperform the state-of-the-art results for lightweight object detection. Code and pre-trained models are available at https://github.com/PaddlePaddle/PaddleDetection.
Temporal-Spatial Feature Pyramid for Video Saliency Detection
May 10, 2021
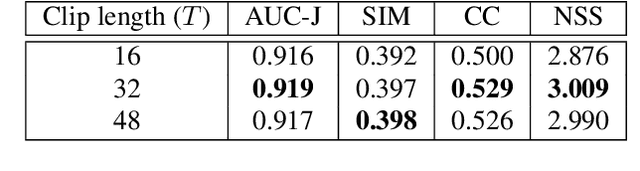
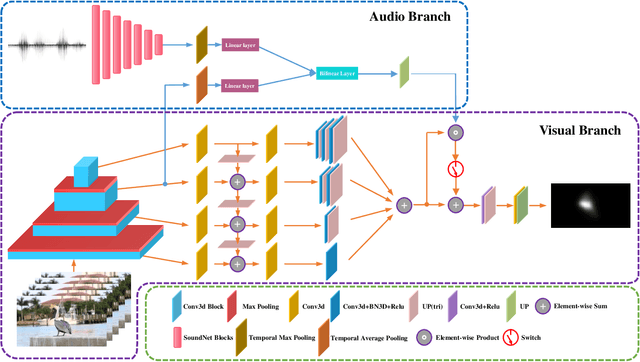
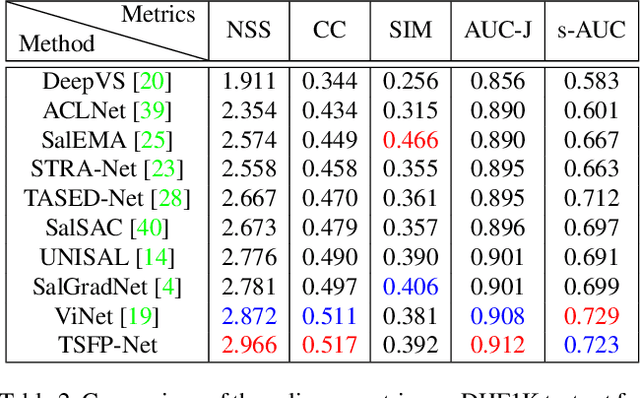
In this paper, we propose a 3D fully convolutional encoder-decoder architecture for video saliency detection, which combines scale, space and time information for video saliency modeling. The encoder extracts multi-scale temporal-spatial features from the input continuous video frames, and then constructs temporal-spatial feature pyramid through temporal-spatial convolution and top-down feature integration. The decoder performs hierarchical decoding of temporal-spatial features from different scales, and finally produces a saliency map from the integration of multiple video frames. Our model is simple yet effective, and can run in real time. We perform abundant experiments, and the results indicate that the well-designed structure can improve the precision of video saliency detection significantly. Experimental results on three purely visual video saliency benchmarks and six audio-video saliency benchmarks demonstrate that our method achieves state-of-theart performance.