 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2HMem: A Multimodal Memory Benchmark for Agents in Human-Human Interactions
Jun 08, 2026Large language model agents are increasingly deployed in human-human interaction settings, such as meeting assistants and clinical documentation systems, where they must observe conversations and retain information for downstream queries. Unlike traditional human-assistant settings, these environments are inherently multimodal, involve complex discourse phenomena such as anaphora and deixis, and contain asynchronous or conflicting information from multiple participants. However, existing memory benchmarks largely focus on single-user, text-only interactions, failing to capture these challenges. To address this gap, we introduce H2HMem, a Human-to-Human Multimodal Memory Benchmark for evaluating memory capabilities in complex human-human interactions. H2HMem includes both dyadic and multi-party conversations with multimodal information streams, and evaluates agents along three dimensions: memory recall, reasoning, and application. Experiments with advanced agents reveal substantial limitations in constructing, retaining, and utilizing memories across modalities, participants, and sessions, highlighting substantial room for improvement in next-generation LLM agents.
Temporal-Spatial Feature Pyramid for Video Saliency Detection
May 10, 2021
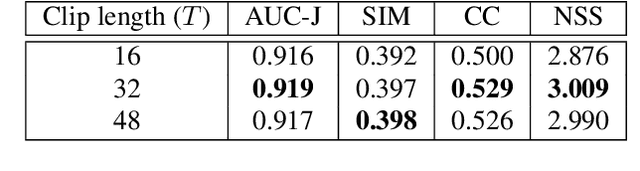
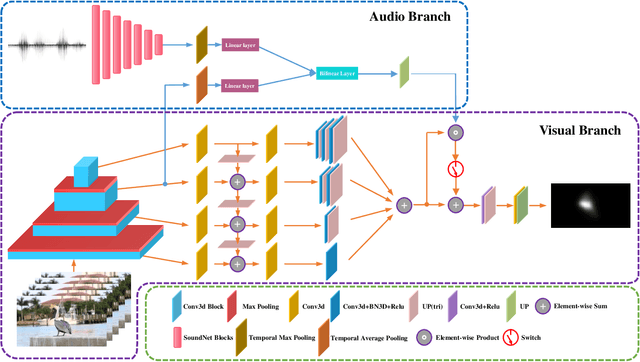
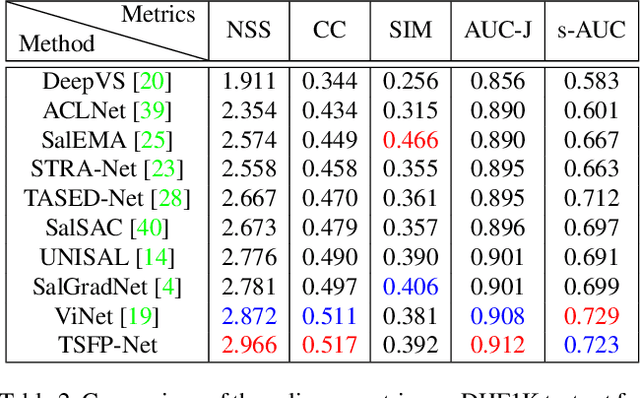
In this paper, we propose a 3D fully convolutional encoder-decoder architecture for video saliency detection, which combines scale, space and time information for video saliency modeling. The encoder extracts multi-scale temporal-spatial features from the input continuous video frames, and then constructs temporal-spatial feature pyramid through temporal-spatial convolution and top-down feature integration. The decoder performs hierarchical decoding of temporal-spatial features from different scales, and finally produces a saliency map from the integration of multiple video frames. Our model is simple yet effective, and can run in real time. We perform abundant experiments, and the results indicate that the well-designed structure can improve the precision of video saliency detection significantly. Experimental results on three purely visual video saliency benchmarks and six audio-video saliency benchmarks demonstrate that our method achieves state-of-theart performance.
Learning Statistical Texture for Semantic Segmentation
Mar 06, 2021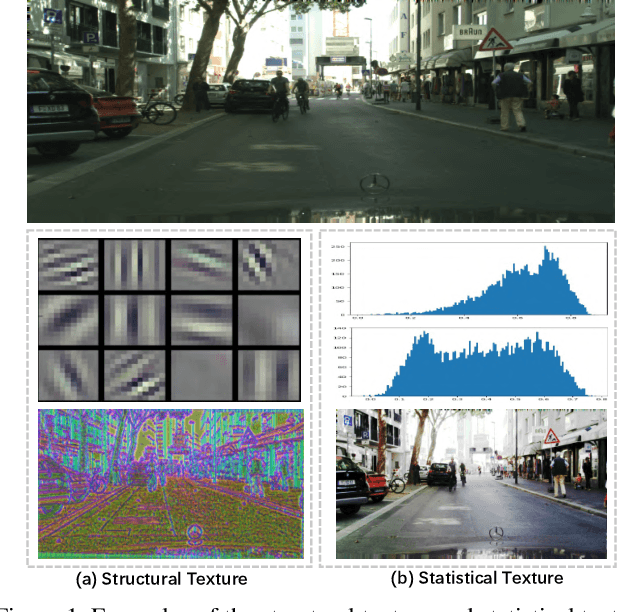
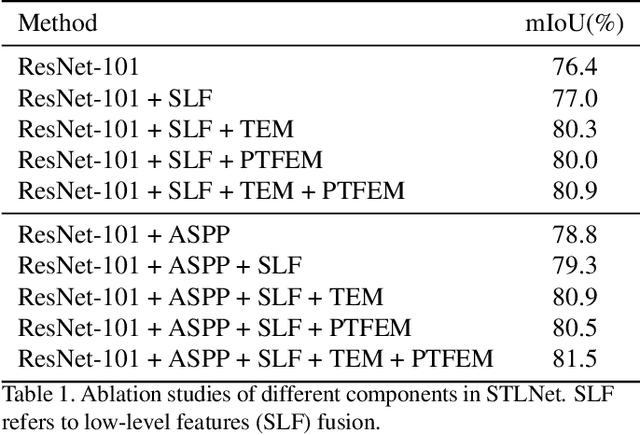
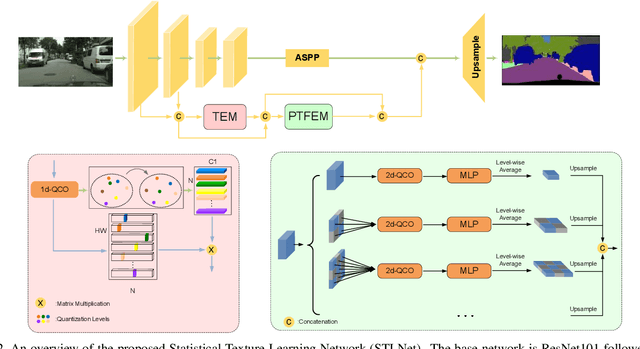

Existing semantic segmentation works mainly focus on learning the contextual information in high-level semantic features with CNNs. In order to maintain a precise boundary, low-level texture features are directly skip-connected into the deeper layers. Nevertheless, texture features are not only about local structure, but also include global statistical knowledge of the input image. In this paper, we fully take advantages of the low-level texture features and propose a novel Statistical Texture Learning Network (STLNet) for semantic segmentation. For the first time, STLNet analyzes the distribution of low level information and efficiently utilizes them for the task. Specifically, a novel Quantization and Counting Operator (QCO) is designed to describe the texture information in a statistical manner. Based on QCO, two modules are introduced: (1) Texture Enhance Module (TEM), to capture texture-related information and enhance the texture details; (2) Pyramid Texture Feature Extraction Module (PTFEM), to effectively extract the statistical texture features from multiple scales. Through extensive experiments, we show that the proposed STLNet achieves state-of-the-art performance on three semantic segmentation benchmarks: Cityscapes, PASCAL Context and ADE20K.
Distance Guided Channel Weighting for Semantic Segmentation
May 05, 2020
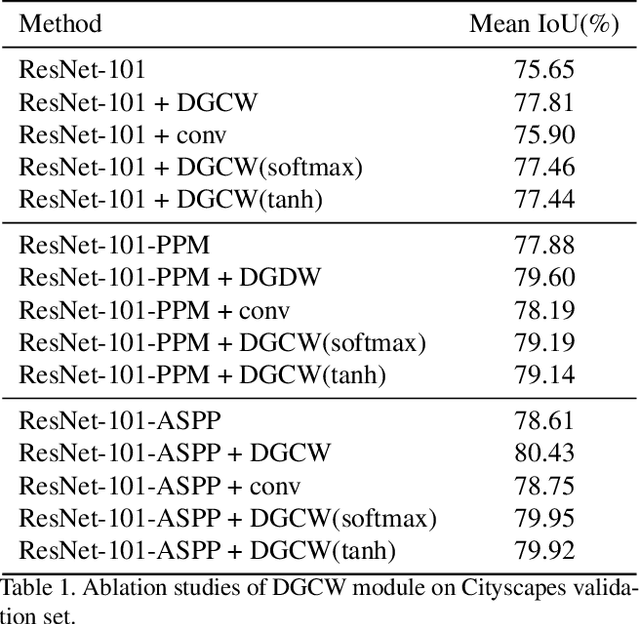
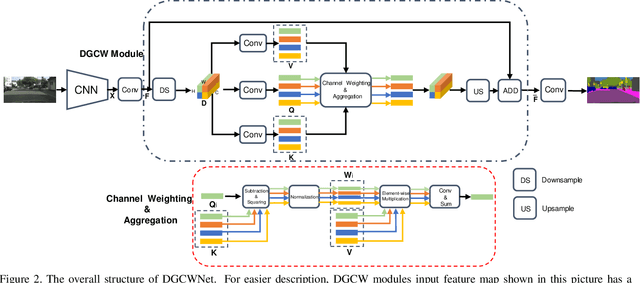
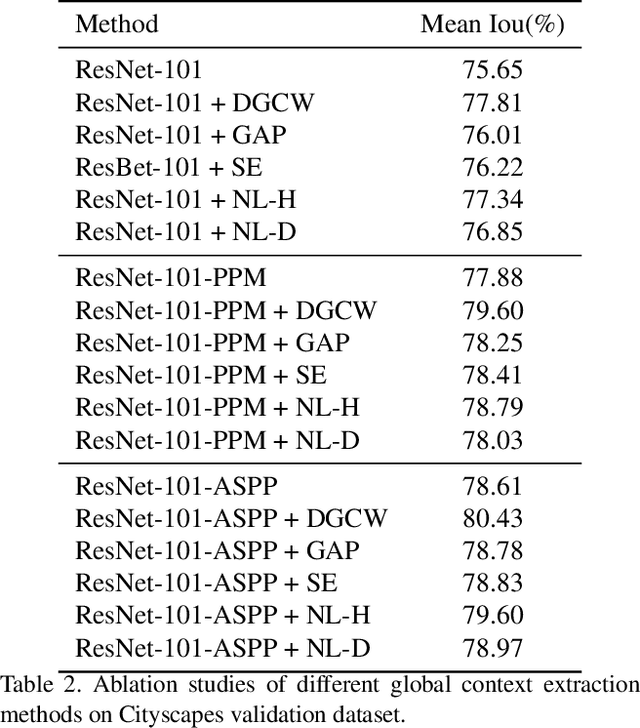
Recent works have achieved great success in improving the performance of multiple computer vision tasks by capturing features with a high channel number utilizing deep neural networks. However, many channels of extracted features are not discriminative and contain a lot of redundant information. In this paper, we address above issue by introducing the Distance Guided Channel Weighting (DGCW) Module. The DGCW module is constructed in a pixel-wise context extraction manner, which enhances the discriminativeness of features by weighting different channels of each pixel's feature vector when modeling its relationship with other pixels. It can make full use of the high-discriminative information while ignore the low-discriminative information containing in feature maps, as well as capture the long-range dependencies. Furthermore, by incorporating the DGCW module with a baseline segmentation network, we propose the Distance Guided Channel Weighting Network (DGCWNet). We conduct extensive experiments to demonstrate the effectiveness of DGCWNet. In particular, it achieves 81.6% mIoU on Cityscapes with only fine annotated data for training, and also gains satisfactory performance on another two semantic segmentation datasets, i.e. Pascal Context and ADE20K. Code will be available soon at https://github.com/LanyunZhu/DGCWNet.
OGNet: Salient Object Detection with Output-guided Attention Module
Jul 17, 2019
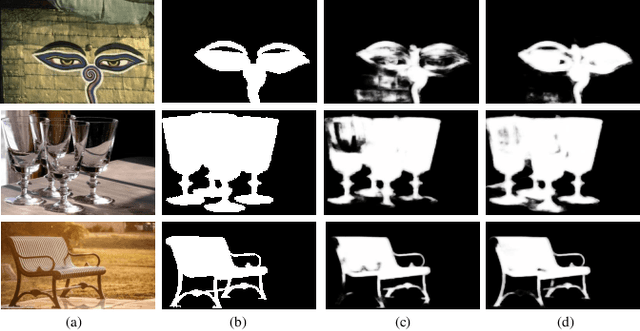
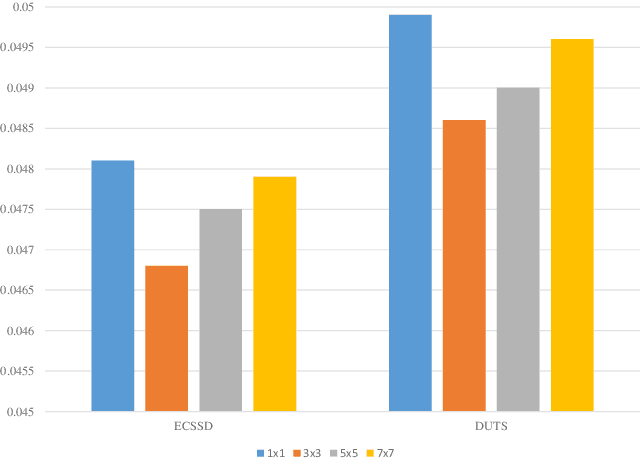
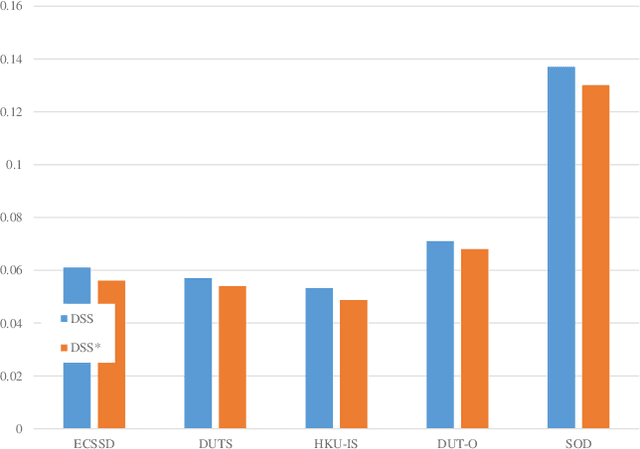
Attention mechanisms are widely used in salient object detection models based on deep learning, which can effectively promote the extraction and utilization of useful information by neural networks. However, most of the existing attention modules used in salient object detection are input with the processed feature map itself, which easily leads to the problem of `blind overconfidence'. In this paper, instead of applying the widely used self-attention module, we present an output-guided attention module built with multi-scale outputs to overcome the problem of `blind overconfidence'. We also construct a new loss function, the intractable area F-measure loss function, which is based on the F-measure of the hard-to-handle area to improve the detection effect of the model in the edge areas and confusing areas of an image. Extensive experiments and abundant ablation studies are conducted to evaluate the effect of our methods and to explore the most suitable structure for the model. Tests on several data sets show that our model performs very well, even though it is very lightweight.