 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOGNet: Salient Object Detection with Output-guided Attention Module
Paper and Code
Jul 17, 2019
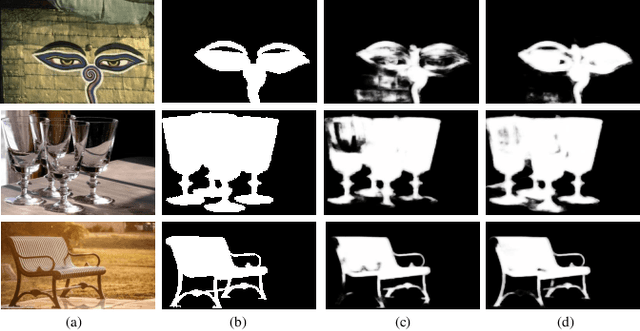
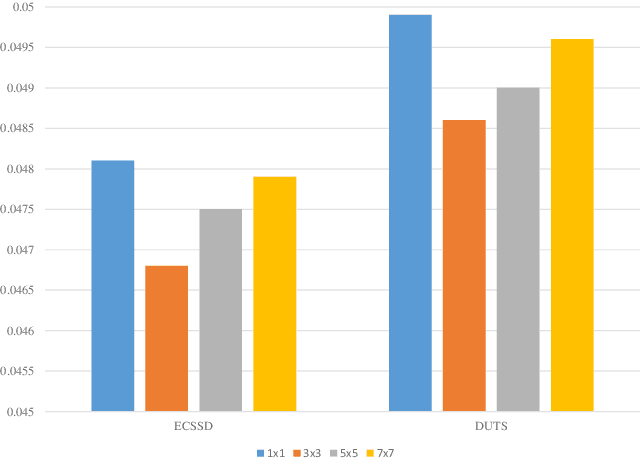
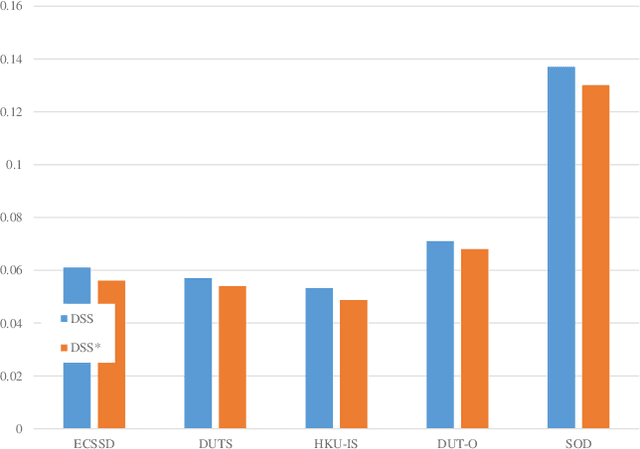
Attention mechanisms are widely used in salient object detection models based on deep learning, which can effectively promote the extraction and utilization of useful information by neural networks. However, most of the existing attention modules used in salient object detection are input with the processed feature map itself, which easily leads to the problem of `blind overconfidence'. In this paper, instead of applying the widely used self-attention module, we present an output-guided attention module built with multi-scale outputs to overcome the problem of `blind overconfidence'. We also construct a new loss function, the intractable area F-measure loss function, which is based on the F-measure of the hard-to-handle area to improve the detection effect of the model in the edge areas and confusing areas of an image. Extensive experiments and abundant ablation studies are conducted to evaluate the effect of our methods and to explore the most suitable structure for the model. Tests on several data sets show that our model performs very well, even though it is very lightweight.