 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTune-Your-Style: Intensity-tunable 3D Style Transfer with Gaussian Splatting
Jan 31, 20263D style transfer refers to the artistic stylization of 3D assets based on reference style images. Recently, 3DGS-based stylization methods have drawn considerable attention, primarily due to their markedly enhanced training and rendering speeds. However, a vital challenge for 3D style transfer is to strike a balance between the content and the patterns and colors of the style. Although the existing methods strive to achieve relatively balanced outcomes, the fixed-output paradigm struggles to adapt to the diverse content-style balance requirements from different users. In this work, we introduce a creative intensity-tunable 3D style transfer paradigm, dubbed \textbf{Tune-Your-Style}, which allows users to flexibly adjust the style intensity injected into the scene to match their desired content-style balance, thus enhancing the customizability of 3D style transfer. To achieve this goal, we first introduce Gaussian neurons to explicitly model the style intensity and parameterize a learnable style tuner to achieve intensity-tunable style injection. To facilitate the learning of tunable stylization, we further propose the tunable stylization guidance, which obtains multi-view consistent stylized views from diffusion models through cross-view style alignment, and then employs a two-stage optimization strategy to provide stable and efficient guidance by modulating the balance between full-style guidance from the stylized views and zero-style guidance from the initial rendering. Extensive experiments demonstrate that our method not only delivers visually appealing results, but also exhibits flexible customizability for 3D style transfer. Project page is available at https://zhao-yian.github.io/TuneStyle.
SPAN: Spatial-Projection Alignment for Monocular 3D Object Detection
Nov 10, 2025Existing monocular 3D detectors typically tame the pronounced nonlinear regression of 3D bounding box through decoupled prediction paradigm, which employs multiple branches to estimate geometric center, depth, dimensions, and rotation angle separately. Although this decoupling strategy simplifies the learning process, it inherently ignores the geometric collaborative constraints between different attributes, resulting in the lack of geometric consistency prior, thereby leading to suboptimal performance. To address this issue, we propose novel Spatial-Projection Alignment (SPAN) with two pivotal components: (i). Spatial Point Alignment enforces an explicit global spatial constraint between the predicted and ground-truth 3D bounding boxes, thereby rectifying spatial drift caused by decoupled attribute regression. (ii). 3D-2D Projection Alignment ensures that the projected 3D box is aligned tightly within its corresponding 2D detection bounding box on the image plane, mitigating projection misalignment overlooked in previous works. To ensure training stability, we further introduce a Hierarchical Task Learning strategy that progressively incorporates spatial-projection alignment as 3D attribute predictions refine, preventing early stage error propagation across attributes. Extensive experiments demonstrate that the proposed method can be easily integrated into any established monocular 3D detector and delivers significant performance improvements.
E-4DGS: High-Fidelity Dynamic Reconstruction from the Multi-view Event Cameras
Aug 13, 2025Novel view synthesis and 4D reconstruction techniques predominantly rely on RGB cameras, thereby inheriting inherent limitations such as the dependence on adequate lighting, susceptibility to motion blur, and a limited dynamic range. Event cameras, offering advantages of low power, high temporal resolution and high dynamic range, have brought a new perspective to addressing the scene reconstruction challenges in high-speed motion and low-light scenes. To this end, we propose E-4DGS, the first event-driven dynamic Gaussian Splatting approach, for novel view synthesis from multi-view event streams with fast-moving cameras. Specifically, we introduce an event-based initialization scheme to ensure stable training and propose event-adaptive slicing splatting for time-aware reconstruction. Additionally, we employ intensity importance pruning to eliminate floating artifacts and enhance 3D consistency, while incorporating an adaptive contrast threshold for more precise optimization. We design a synthetic multi-view camera setup with six moving event cameras surrounding the object in a 360-degree configuration and provide a benchmark multi-view event stream dataset that captures challenging motion scenarios. Our approach outperforms both event-only and event-RGB fusion baselines and paves the way for the exploration of multi-view event-based reconstruction as a novel approach for rapid scene capture.
iSegMan: Interactive Segment-and-Manipulate 3D Gaussians
May 17, 2025The efficient rendering and explicit nature of 3DGS promote the advancement of 3D scene manipulation. However, existing methods typically encounter challenges in controlling the manipulation region and are unable to furnish the user with interactive feedback, which inevitably leads to unexpected results. Intuitively, incorporating interactive 3D segmentation tools can compensate for this deficiency. Nevertheless, existing segmentation frameworks impose a pre-processing step of scene-specific parameter training, which limits the efficiency and flexibility of scene manipulation. To deliver a 3D region control module that is well-suited for scene manipulation with reliable efficiency, we propose interactive Segment-and-Manipulate 3D Gaussians (iSegMan), an interactive segmentation and manipulation framework that only requires simple 2D user interactions in any view. To propagate user interactions to other views, we propose Epipolar-guided Interaction Propagation (EIP), which innovatively exploits epipolar constraint for efficient and robust interaction matching. To avoid scene-specific training to maintain efficiency, we further propose the novel Visibility-based Gaussian Voting (VGV), which obtains 2D segmentations from SAM and models the region extraction as a voting game between 2D Pixels and 3D Gaussians based on Gaussian visibility. Taking advantage of the efficient and precise region control of EIP and VGV, we put forth a Manipulation Toolbox to implement various functions on selected regions, enhancing the controllability, flexibility and practicality of scene manipulation. Extensive results on 3D scene manipulation and segmentation tasks fully demonstrate the significant advantages of iSegMan. Project page is available at https://zhao-yian.github.io/iSegMan.
Kongzi: A Historical Large Language Model with Fact Enhancement
Apr 13, 2025The capabilities of the latest large language models (LLMs) have been extended from pure natural language understanding to complex reasoning tasks. However, current reasoning models often exhibit factual inaccuracies in longer reasoning chains, which poses challenges for historical reasoning and limits the potential of LLMs in complex, knowledge-intensive tasks. Historical studies require not only the accurate presentation of factual information but also the ability to establish cross-temporal correlations and derive coherent conclusions from fragmentary and often ambiguous sources. To address these challenges, we propose Kongzi, a large language model specifically designed for historical analysis. Through the integration of curated, high-quality historical data and a novel fact-reinforcement learning strategy, Kongzi demonstrates strong factual alignment and sophisticated reasoning depth. Extensive experiments on tasks such as historical question answering and narrative generation demonstrate that Kongzi outperforms existing models in both factual accuracy and reasoning depth. By effectively addressing the unique challenges inherent in historical texts, Kongzi sets a new standard for the development of accurate and reliable LLMs in professional domains.
MagicComp: Training-free Dual-Phase Refinement for Compositional Video Generation
Mar 18, 2025Text-to-video (T2V) generation has made significant strides with diffusion models. However, existing methods still struggle with accurately binding attributes, determining spatial relationships, and capturing complex action interactions between multiple subjects. To address these limitations, we propose MagicComp, a training-free method that enhances compositional T2V generation through dual-phase refinement. Specifically, (1) During the Conditioning Stage: We introduce the Semantic Anchor Disambiguation to reinforces subject-specific semantics and resolve inter-subject ambiguity by progressively injecting the directional vectors of semantic anchors into original text embedding; (2) During the Denoising Stage: We propose Dynamic Layout Fusion Attention, which integrates grounding priors and model-adaptive spatial perception to flexibly bind subjects to their spatiotemporal regions through masked attention modulation. Furthermore, MagicComp is a model-agnostic and versatile approach, which can be seamlessly integrated into existing T2V architectures. Extensive experiments on T2V-CompBench and VBench demonstrate that MagicComp outperforms state-of-the-art methods, highlighting its potential for applications such as complex prompt-based and trajectory-controllable video generation. Project page: https://hong-yu-zhang.github.io/MagicComp-Page/.
ProGDF: Progressive Gaussian Differential Field for Controllable and Flexible 3D Editing
Dec 11, 2024



3D editing plays a crucial role in editing and reusing existing 3D assets, thereby enhancing productivity. Recently, 3DGS-based methods have gained increasing attention due to their efficient rendering and flexibility. However, achieving desired 3D editing results often requires multiple adjustments in an iterative loop, resulting in tens of minutes of training time cost for each attempt and a cumbersome trial-and-error cycle for users. This in-the-loop training paradigm results in a poor user experience. To address this issue, we introduce the concept of process-oriented modelling for 3D editing and propose the Progressive Gaussian Differential Field (ProGDF), an out-of-loop training approach that requires only a single training session to provide users with controllable editing capability and variable editing results through a user-friendly interface in real-time. ProGDF consists of two key components: Progressive Gaussian Splatting (PGS) and Gaussian Differential Field (GDF). PGS introduces the progressive constraint to extract the diverse intermediate results of the editing process and employs rendering quality regularization to improve the quality of these results. Based on these intermediate results, GDF leverages a lightweight neural network to model the editing process. Extensive results on two novel applications, namely controllable 3D editing and flexible fine-grained 3D manipulation, demonstrate the effectiveness, practicality and flexibility of the proposed ProGDF.
RT-DETRv2: Improved Baseline with Bag-of-Freebies for Real-Time Detection Transformer
Jul 24, 2024In this report, we present RT-DETRv2, an improved Real-Time DEtection TRansformer (RT-DETR). RT-DETRv2 builds upon the previous state-of-the-art real-time detector, RT-DETR, and opens up a set of bag-of-freebies for flexibility and practicality, as well as optimizing the training strategy to achieve enhanced performance. To improve the flexibility, we suggest setting a distinct number of sampling points for features at different scales in the deformable attention to achieve selective multi-scale feature extraction by the decoder. To enhance practicality, we propose an optional discrete sampling operator to replace the grid_sample operator that is specific to RT-DETR compared to YOLOs. This removes the deployment constraints typically associated with DETRs. For the training strategy, we propose dynamic data augmentation and scale-adaptive hyperparameters customization to improve performance without loss of speed. Source code and pre-trained models will be available at https://github.com/lyuwenyu/RT-DETR.
GraCo: Granularity-Controllable Interactive Segmentation
May 01, 2024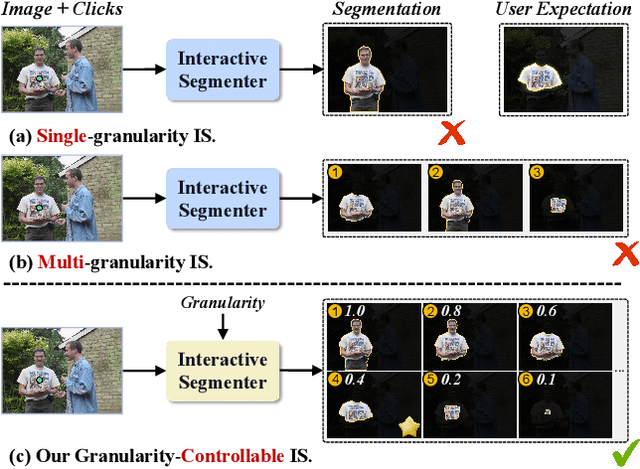
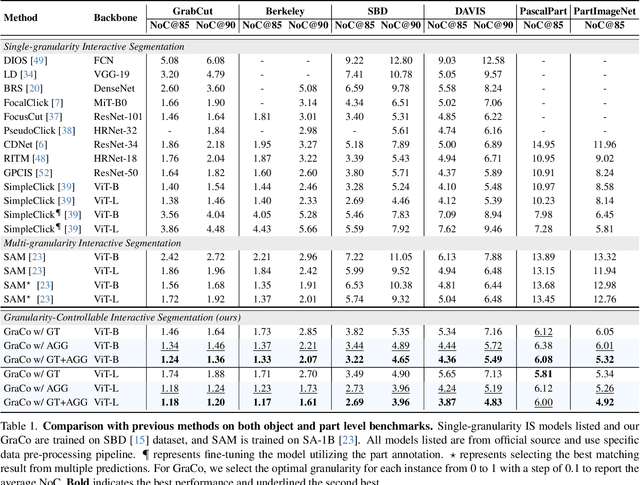
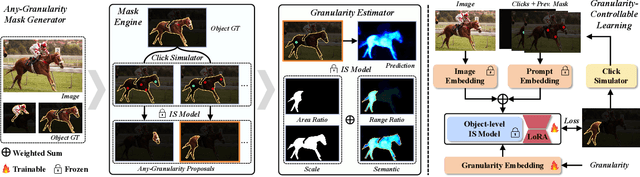
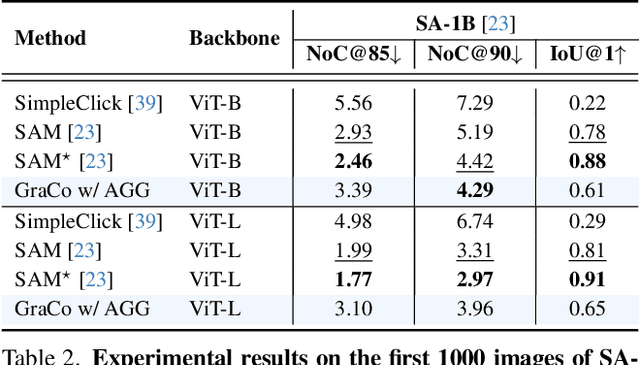
Interactive Segmentation (IS) segments specific objects or parts in the image according to user input. Current IS pipelines fall into two categories: single-granularity output and multi-granularity output. The latter aims to alleviate the spatial ambiguity present in the former. However, the multi-granularity output pipeline suffers from limited interaction flexibility and produces redundant results. In this work, we introduce Granularity-Controllable Interactive Segmentation (GraCo), a novel approach that allows precise control of prediction granularity by introducing additional parameters to input. This enhances the customization of the interactive system and eliminates redundancy while resolving ambiguity. Nevertheless, the exorbitant cost of annotating multi-granularity masks and the lack of available datasets with granularity annotations make it difficult for models to acquire the necessary guidance to control output granularity. To address this problem, we design an any-granularity mask generator that exploits the semantic property of the pre-trained IS model to automatically generate abundant mask-granularity pairs without requiring additional manual annotation. Based on these pairs, we propose a granularity-controllable learning strategy that efficiently imparts the granularity controllability to the IS model. Extensive experiments on intricate scenarios at object and part levels demonstrate that our GraCo has significant advantages over previous methods. This highlights the potential of GraCo to be a flexible annotation tool, capable of adapting to diverse segmentation scenarios. The project page: https://zhao-yian.github.io/GraCo.
DETRs Beat YOLOs on Real-time Object Detection
Apr 17, 2023



Recently, end-to-end transformer-based detectors (DETRs) have achieved remarkable performance. However, the issue of the high computational cost of DETRs has not been effectively addressed, limiting their practical application and preventing them from fully exploiting the benefits of no post-processing, such as non-maximum suppression (NMS). In this paper, we first analyze the influence of NMS in modern real-time object detectors on inference speed, and establish an end-to-end speed benchmark. To avoid the inference delay caused by NMS, we propose a Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge. Specifically, we design an efficient hybrid encoder to efficiently process multi-scale features by decoupling the intra-scale interaction and cross-scale fusion, and propose IoU-aware query selection to improve the initialization of object queries. In addition, our proposed detector supports flexibly adjustment of the inference speed by using different decoder layers without the need for retraining, which facilitates the practical application of real-time object detectors. Our RT-DETR-L achieves 53.0% AP on COCO val2017 and 114 FPS on T4 GPU, while RT-DETR-X achieves 54.8% AP and 74 FPS, outperforming all YOLO detectors of the same scale in both speed and accuracy. Furthermore, our RT-DETR-R50 achieves 53.1% AP and 108 FPS, outperforming DINO-Deformable-DETR-R50 by 2.2% AP in accuracy and by about 21 times in FPS. Source code and pretrained models will be available at PaddleDetection.