 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtocol-agnostic and Data-free Backdoor Attacks on Pre-trained Models in RF Fingerprinting
May 01, 2025While supervised deep neural networks (DNNs) have proven effective for device authentication via radio frequency (RF) fingerprinting, they are hindered by domain shift issues and the scarcity of labeled data. The success of large language models has led to increased interest in unsupervised pre-trained models (PTMs), which offer better generalization and do not require labeled datasets, potentially addressing the issues mentioned above. However, the inherent vulnerabilities of PTMs in RF fingerprinting remain insufficiently explored. In this paper, we thoroughly investigate data-free backdoor attacks on such PTMs in RF fingerprinting, focusing on a practical scenario where attackers lack access to downstream data, label information, and training processes. To realize the backdoor attack, we carefully design a set of triggers and predefined output representations (PORs) for the PTMs. By mapping triggers and PORs through backdoor training, we can implant backdoor behaviors into the PTMs, thereby introducing vulnerabilities across different downstream RF fingerprinting tasks without requiring prior knowledge. Extensive experiments demonstrate the wide applicability of our proposed attack to various input domains, protocols, and PTMs. Furthermore, we explore potential detection and defense methods, demonstrating the difficulty of fully safeguarding against our proposed backdoor attack.
Kongzi: A Historical Large Language Model with Fact Enhancement
Apr 13, 2025The capabilities of the latest large language models (LLMs) have been extended from pure natural language understanding to complex reasoning tasks. However, current reasoning models often exhibit factual inaccuracies in longer reasoning chains, which poses challenges for historical reasoning and limits the potential of LLMs in complex, knowledge-intensive tasks. Historical studies require not only the accurate presentation of factual information but also the ability to establish cross-temporal correlations and derive coherent conclusions from fragmentary and often ambiguous sources. To address these challenges, we propose Kongzi, a large language model specifically designed for historical analysis. Through the integration of curated, high-quality historical data and a novel fact-reinforcement learning strategy, Kongzi demonstrates strong factual alignment and sophisticated reasoning depth. Extensive experiments on tasks such as historical question answering and narrative generation demonstrate that Kongzi outperforms existing models in both factual accuracy and reasoning depth. By effectively addressing the unique challenges inherent in historical texts, Kongzi sets a new standard for the development of accurate and reliable LLMs in professional domains.
TensorCoder: Dimension-Wise Attention via Tensor Representation for Natural Language Modeling
Aug 12, 2020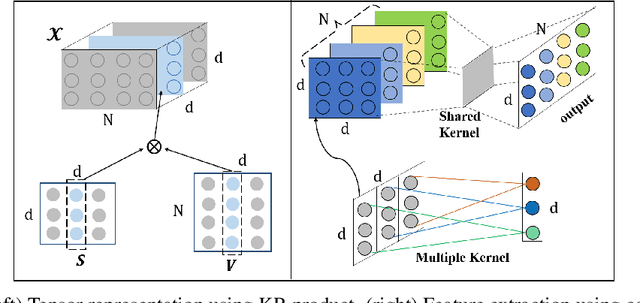
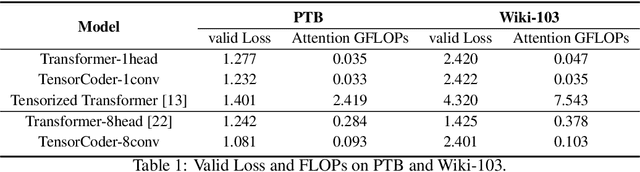
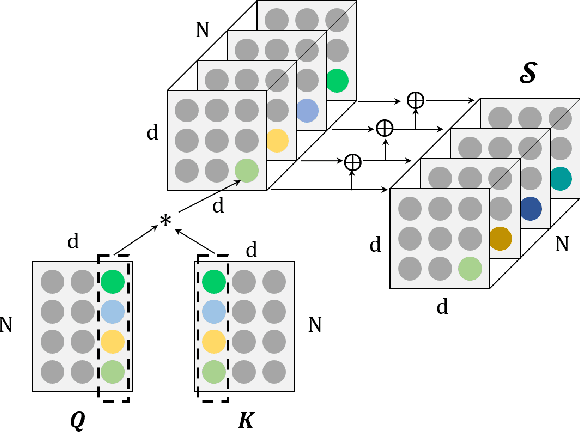
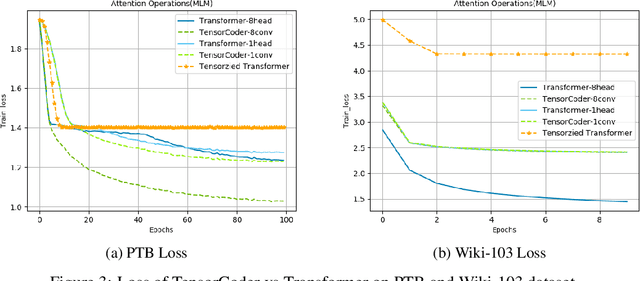
Transformer has been widely-used in many Natural Language Processing (NLP) tasks and the scaled dot-product attention between tokens is a core module of Transformer. This attention is a token-wise design and its complexity is quadratic to the length of sequence, limiting its application potential for long sequence tasks. In this paper, we propose a dimension-wise attention mechanism based on which a novel language modeling approach (namely TensorCoder) can be developed. The dimension-wise attention can reduce the attention complexity from the original $O(N^2d)$ to $O(Nd^2)$, where $N$ is the length of the sequence and $d$ is the dimensionality of head. We verify TensorCoder on two tasks including masked language modeling and neural machine translation. Compared with the original Transformer, TensorCoder not only greatly reduces the calculation of the original model but also obtains improved performance on masked language modeling task (in PTB dataset) and comparable performance on machine translation tasks.
Adaptive Fusion for RGB-D Salient Object Detection
Jan 08, 2019
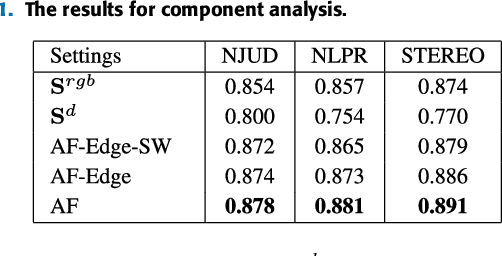
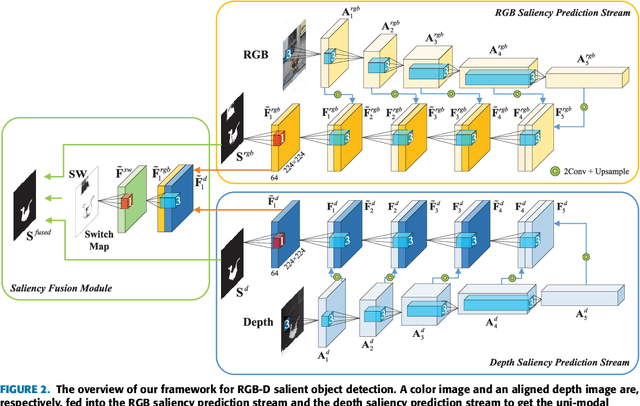
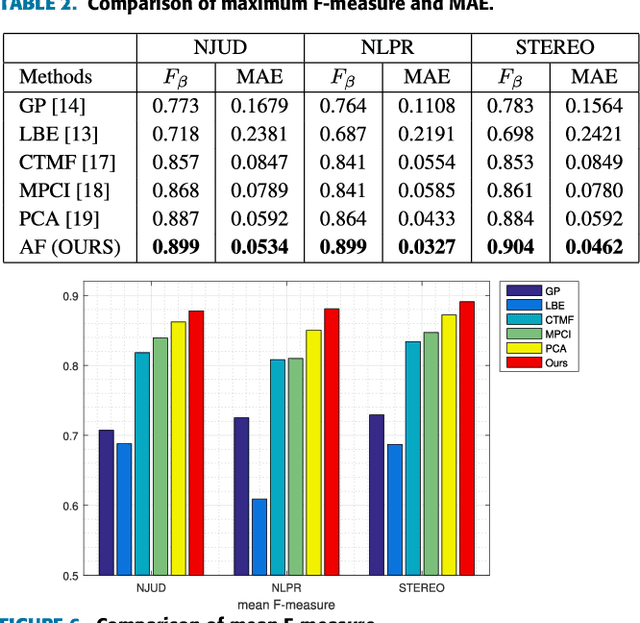
RGB-D salient object detection aims to identify the most visually distinctive objects in a pair of color and depth images. Based upon an observation that most of the salient objects may stand out at least in one modality, this paper proposes an adaptive fusion scheme to fuse saliency predictions generated from two modalities. Specifically, we design a two-streamed convolutional neural network (CNN), each of which extracts features and predicts a saliency map from either RGB or depth modality. Then, a saliency fusion module learns a switch map that is used to adaptively fuse the predicted saliency maps. A loss function composed of saliency supervision, switch map supervision, and edge-preserving constraints is designed to make full supervision, and the entire network is trained in an end-to-end manner. Benefited from the adaptive fusion strategy and the edge-preserving constraint, our approach outperforms state-of-the-art methods on three publicly available datasets.