 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCPO: Thought-Centric Preference Optimization for Effective Embodied Decision-making
Sep 10, 2025
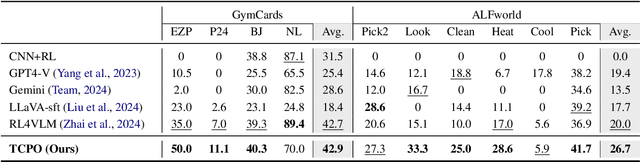
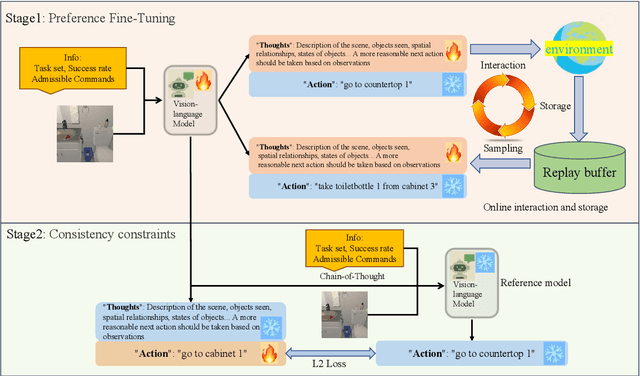

Using effective generalization capabilities of vision language models (VLMs) in context-specific dynamic tasks for embodied artificial intelligence remains a significant challenge. Although supervised fine-tuned models can better align with the real physical world, they still exhibit sluggish responses and hallucination issues in dynamically changing environments, necessitating further alignment. Existing post-SFT methods, reliant on reinforcement learning and chain-of-thought (CoT) approaches, are constrained by sparse rewards and action-only optimization, resulting in low sample efficiency, poor consistency, and model degradation. To address these issues, this paper proposes Thought-Centric Preference Optimization (TCPO) for effective embodied decision-making. Specifically, TCPO introduces a stepwise preference-based optimization approach, transforming sparse reward signals into richer step sample pairs. It emphasizes the alignment of the model's intermediate reasoning process, mitigating the problem of model degradation. Moreover, by incorporating Action Policy Consistency Constraint (APC), it further imposes consistency constraints on the model output. Experiments in the ALFWorld environment demonstrate an average success rate of 26.67%, achieving a 6% improvement over RL4VLM and validating the effectiveness of our approach in mitigating model degradation after fine-tuning. These results highlight the potential of integrating preference-based learning techniques with CoT processes to enhance the decision-making capabilities of vision-language models in embodied agents.
Object-Focus Actor for Data-efficient Robot Generalization Dexterous Manipulation
May 21, 2025Robot manipulation learning from human demonstrations offers a rapid means to acquire skills but often lacks generalization across diverse scenes and object placements. This limitation hinders real-world applications, particularly in complex tasks requiring dexterous manipulation. Vision-Language-Action (VLA) paradigm leverages large-scale data to enhance generalization. However, due to data scarcity, VLA's performance remains limited. In this work, we introduce Object-Focus Actor (OFA), a novel, data-efficient approach for generalized dexterous manipulation. OFA exploits the consistent end trajectories observed in dexterous manipulation tasks, allowing for efficient policy training. Our method employs a hierarchical pipeline: object perception and pose estimation, pre-manipulation pose arrival and OFA policy execution. This process ensures that the manipulation is focused and efficient, even in varied backgrounds and positional layout. Comprehensive real-world experiments across seven tasks demonstrate that OFA significantly outperforms baseline methods in both positional and background generalization tests. Notably, OFA achieves robust performance with only 10 demonstrations, highlighting its data efficiency.
Exploration by Random Distribution Distillation
May 16, 2025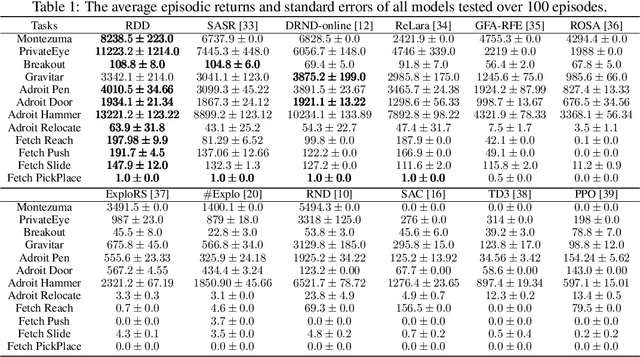
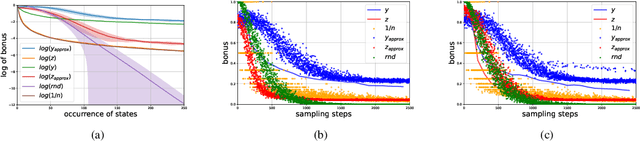
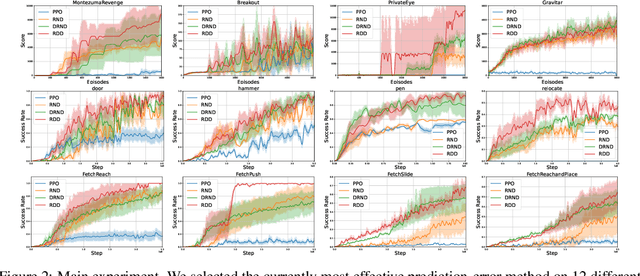
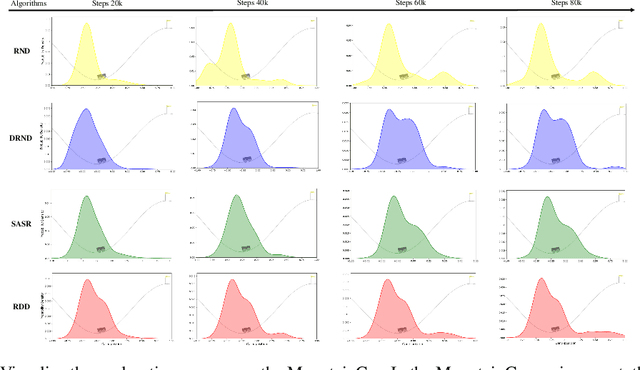
Exploration remains a critical challenge in online reinforcement learning, as an agent must effectively explore unknown environments to achieve high returns. Currently, the main exploration algorithms are primarily count-based methods and curiosity-based methods, with prediction-error methods being a prominent example. In this paper, we propose a novel method called \textbf{R}andom \textbf{D}istribution \textbf{D}istillation (RDD), which samples the output of a target network from a normal distribution. RDD facilitates a more extensive exploration by explicitly treating the difference between the prediction network and the target network as an intrinsic reward. Furthermore, by introducing randomness into the output of the target network for a given state and modeling it as a sample from a normal distribution, intrinsic rewards are bounded by two key components: a pseudo-count term ensuring proper exploration decay and a discrepancy term accounting for predictor convergence. We demonstrate that RDD effectively unifies both count-based and prediction-error approaches. It retains the advantages of prediction-error methods in high-dimensional spaces, while also implementing an intrinsic reward decay mode akin to the pseudo-count method. In the experimental section, RDD is compared with more advanced methods in a series of environments. Both theoretical analysis and experimental results confirm the effectiveness of our approach in improving online exploration for reinforcement learning tasks.
Kongzi: A Historical Large Language Model with Fact Enhancement
Apr 13, 2025The capabilities of the latest large language models (LLMs) have been extended from pure natural language understanding to complex reasoning tasks. However, current reasoning models often exhibit factual inaccuracies in longer reasoning chains, which poses challenges for historical reasoning and limits the potential of LLMs in complex, knowledge-intensive tasks. Historical studies require not only the accurate presentation of factual information but also the ability to establish cross-temporal correlations and derive coherent conclusions from fragmentary and often ambiguous sources. To address these challenges, we propose Kongzi, a large language model specifically designed for historical analysis. Through the integration of curated, high-quality historical data and a novel fact-reinforcement learning strategy, Kongzi demonstrates strong factual alignment and sophisticated reasoning depth. Extensive experiments on tasks such as historical question answering and narrative generation demonstrate that Kongzi outperforms existing models in both factual accuracy and reasoning depth. By effectively addressing the unique challenges inherent in historical texts, Kongzi sets a new standard for the development of accurate and reliable LLMs in professional domains.
Dexterous Hand Manipulation via Efficient Imitation-Bootstrapped Online Reinforcement Learning
Mar 06, 2025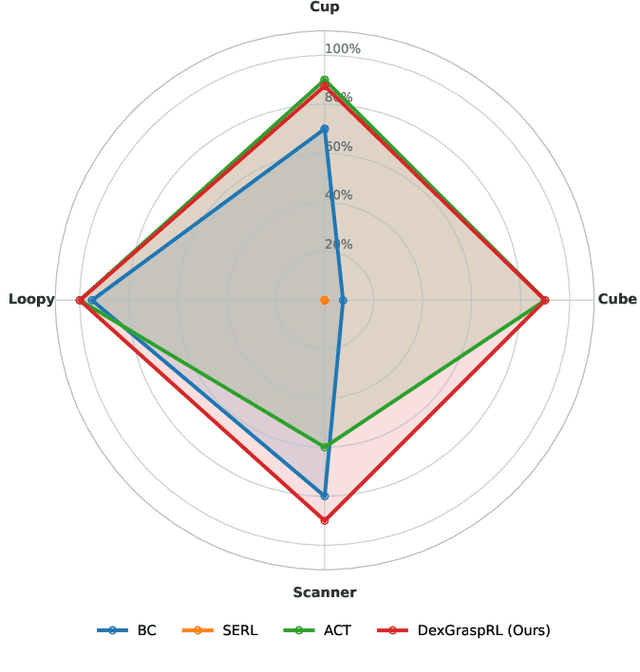
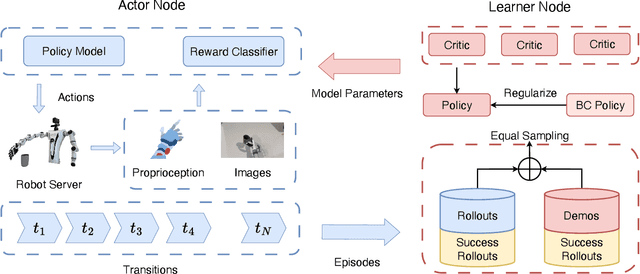
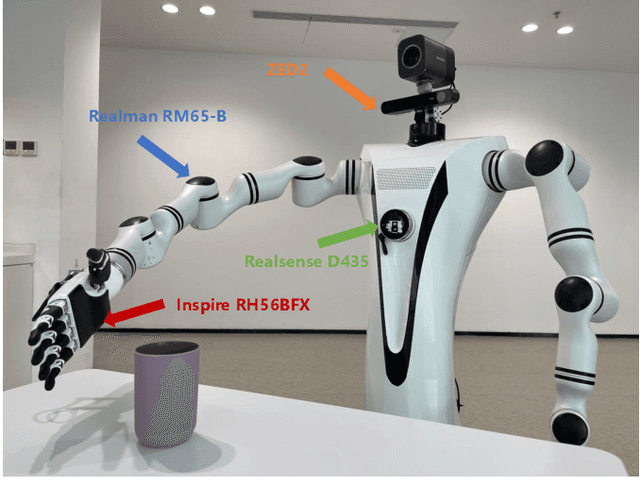

Dexterous hand manipulation in real-world scenarios presents considerable challenges due to its demands for both dexterity and precision. While imitation learning approaches have thoroughly examined these challenges, they still require a significant number of expert demonstrations and are limited by a constrained performance upper bound. In this paper, we propose a novel and efficient Imitation-Bootstrapped Online Reinforcement Learning (IBORL) method tailored for robotic dexterous hand manipulation in real-world environments. Specifically, we pretrain the policy using a limited set of expert demonstrations and subsequently finetune this policy through direct reinforcement learning in the real world. To address the catastrophic forgetting issues that arise from the distribution shift between expert demonstrations and real-world environments, we design a regularization term that balances the exploration of novel behaviors with the preservation of the pretrained policy. Our experiments with real-world tasks demonstrate that our method significantly outperforms existing approaches, achieving an almost 100% success rate and a 23% improvement in cycle time. Furthermore, by finetuning with online reinforcement learning, our method surpasses expert demonstrations and uncovers superior policies. Our code and empirical results are available in https://hggforget.github.io/iborl.github.io/.
Egocentric Vision Language Planning
Aug 11, 2024We explore leveraging large multi-modal models (LMMs) and text2image models to build a more general embodied agent. LMMs excel in planning long-horizon tasks over symbolic abstractions but struggle with grounding in the physical world, often failing to accurately identify object positions in images. A bridge is needed to connect LMMs to the physical world. The paper proposes a novel approach, egocentric vision language planning (EgoPlan), to handle long-horizon tasks from an egocentric perspective in varying household scenarios. This model leverages a diffusion model to simulate the fundamental dynamics between states and actions, integrating techniques like style transfer and optical flow to enhance generalization across different environmental dynamics. The LMM serves as a planner, breaking down instructions into sub-goals and selecting actions based on their alignment with these sub-goals, thus enabling more generalized and effective decision-making. Experiments show that EgoPlan improves long-horizon task success rates from the egocentric view compared to baselines across household scenarios.