 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Oct 09, 2025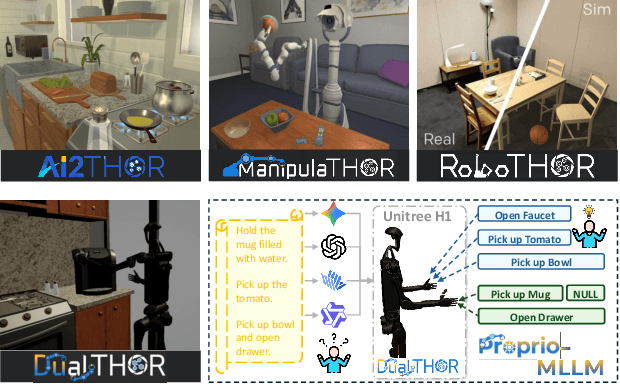


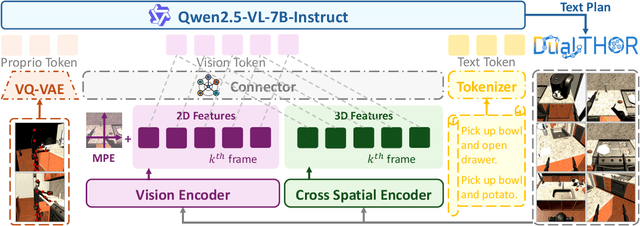
In recent years, Multimodal Large Language Models (MLLMs) have demonstrated the ability to serve as high-level planners, enabling robots to follow complex human instructions. However, their effectiveness, especially in long-horizon tasks involving dual-arm humanoid robots, remains limited. This limitation arises from two main challenges: (i) the absence of simulation platforms that systematically support task evaluation and data collection for humanoid robots, and (ii) the insufficient embodiment awareness of current MLLMs, which hinders reasoning about dual-arm selection logic and body positions during planning. To address these issues, we present DualTHOR, a new dual-arm humanoid simulator, with continuous transition and a contingency mechanism. Building on this platform, we propose Proprio-MLLM, a model that enhances embodiment awareness by incorporating proprioceptive information with motion-based position embedding and a cross-spatial encoder. Experiments show that, while existing MLLMs struggle in this environment, Proprio-MLLM achieves an average improvement of 19.75% in planning performance. Our work provides both an essential simulation platform and an effective model to advance embodied intelligence in humanoid robotics. The code is available at https://anonymous.4open.science/r/DualTHOR-5F3B.
RL from Physical Feedback: Aligning Large Motion Models with Humanoid Control
Jun 15, 2025This paper focuses on a critical challenge in robotics: translating text-driven human motions into executable actions for humanoid robots, enabling efficient and cost-effective learning of new behaviors. While existing text-to-motion generation methods achieve semantic alignment between language and motion, they often produce kinematically or physically infeasible motions unsuitable for real-world deployment. To bridge this sim-to-real gap, we propose Reinforcement Learning from Physical Feedback (RLPF), a novel framework that integrates physics-aware motion evaluation with text-conditioned motion generation. RLPF employs a motion tracking policy to assess feasibility in a physics simulator, generating rewards for fine-tuning the motion generator. Furthermore, RLPF introduces an alignment verification module to preserve semantic fidelity to text instructions. This joint optimization ensures both physical plausibility and instruction alignment. Extensive experiments show that RLPF greatly outperforms baseline methods in generating physically feasible motions while maintaining semantic correspondence with text instruction, enabling successful deployment on real humanoid robots.
MLLM as Retriever: Interactively Learning Multimodal Retrieval for Embodied Agents
Oct 04, 2024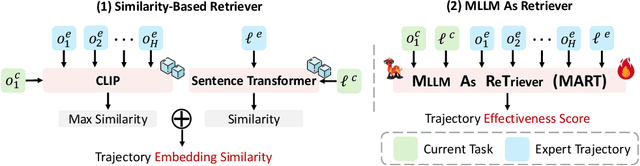

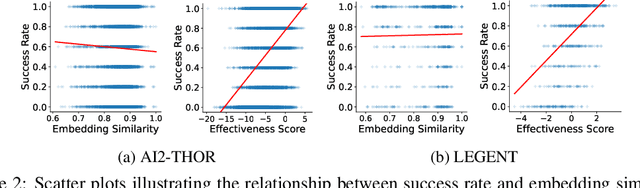
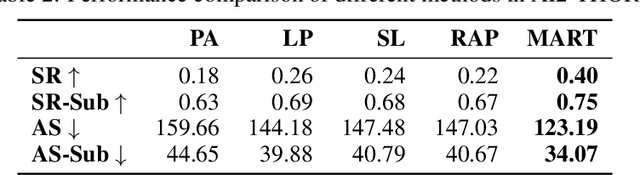
MLLM agents demonstrate potential for complex embodied tasks by retrieving multimodal task-relevant trajectory data. However, current retrieval methods primarily focus on surface-level similarities of textual or visual cues in trajectories, neglecting their effectiveness for the specific task at hand. To address this issue, we propose a novel method, MLLM as ReTriever (MART), which enhances the performance of embodied agents by utilizing interaction data to fine-tune an MLLM retriever based on preference learning, such that the retriever fully considers the effectiveness of trajectories and prioritize them for unseen tasks. We also introduce Trajectory Abstraction, a mechanism that leverages MLLMs' summarization capabilities to represent trajectories with fewer tokens while preserving key information, enabling agents to better comprehend milestones in the trajectory. Experimental results across various environments demonstrate our method significantly improves task success rates in unseen scenes compared to baseline methods. This work presents a new paradigm for multimodal retrieval in embodied agents, by fine-tuning a general-purpose MLLM as the retriever to assess trajectory effectiveness. All benchmark task sets and simulator code modifications for action and observation spaces will be released.
Egocentric Vision Language Planning
Aug 11, 2024We explore leveraging large multi-modal models (LMMs) and text2image models to build a more general embodied agent. LMMs excel in planning long-horizon tasks over symbolic abstractions but struggle with grounding in the physical world, often failing to accurately identify object positions in images. A bridge is needed to connect LMMs to the physical world. The paper proposes a novel approach, egocentric vision language planning (EgoPlan), to handle long-horizon tasks from an egocentric perspective in varying household scenarios. This model leverages a diffusion model to simulate the fundamental dynamics between states and actions, integrating techniques like style transfer and optical flow to enhance generalization across different environmental dynamics. The LMM serves as a planner, breaking down instructions into sub-goals and selecting actions based on their alignment with these sub-goals, thus enabling more generalized and effective decision-making. Experiments show that EgoPlan improves long-horizon task success rates from the egocentric view compared to baselines across household scenarios.
Towards General Computer Control: A Multimodal Agent for Red Dead Redemption II as a Case Study
Mar 07, 2024Despite the success in specific tasks and scenarios, existing foundation agents, empowered by large models (LMs) and advanced tools, still cannot generalize to different scenarios, mainly due to dramatic differences in the observations and actions across scenarios. In this work, we propose the General Computer Control (GCC) setting: building foundation agents that can master any computer task by taking only screen images (and possibly audio) of the computer as input, and producing keyboard and mouse operations as output, similar to human-computer interaction. The main challenges of achieving GCC are: 1) the multimodal observations for decision-making, 2) the requirements of accurate control of keyboard and mouse, 3) the need for long-term memory and reasoning, and 4) the abilities of efficient exploration and self-improvement. To target GCC, we introduce Cradle, an agent framework with six main modules, including: 1) information gathering to extract multi-modality information, 2) self-reflection to rethink past experiences, 3) task inference to choose the best next task, 4) skill curation for generating and updating relevant skills for given tasks, 5) action planning to generate specific operations for keyboard and mouse control, and 6) memory for storage and retrieval of past experiences and known skills. To demonstrate the capabilities of generalization and self-improvement of Cradle, we deploy it in the complex AAA game Red Dead Redemption II, serving as a preliminary attempt towards GCC with a challenging target. To our best knowledge, our work is the first to enable LMM-based agents to follow the main storyline and finish real missions in complex AAA games, with minimal reliance on prior knowledge or resources. The project website is at https://baai-agents.github.io/Cradle/.
CLIP4MC: An RL-Friendly Vision-Language Model for Minecraft
Mar 19, 2023One of the essential missions in the AI research community is to build an autonomous embodied agent that can attain high-level performance across a wide spectrum of tasks. However, acquiring reward/penalty in all open-ended tasks is unrealistic, making the Reinforcement Learning (RL) training procedure impossible. In this paper, we propose a novel cross-modal contrastive learning framework architecture, CLIP4MC, aiming to learn an RL-friendly vision-language model that serves as a reward function for open-ended tasks. Therefore, no further task-specific reward design is needed. Intuitively, it is more reasonable for the model to address the similarity between the video snippet and the language prompt at both the action and entity levels. To this end, a motion encoder is proposed to capture the motion embeddings across different intervals. The correlation scores are then used to construct the auxiliary reward signal for RL agents. Moreover, we construct a neat YouTube dataset based on the large-scale YouTube database provided by MineDojo. Specifically, two rounds of filtering operations guarantee that the dataset covers enough essential information and that the video-text pair is highly correlated. Empirically, we show that the proposed method achieves better performance on RL tasks compared with baselines.
Entity Divider with Language Grounding in Multi-Agent Reinforcement Learning
Oct 25, 2022We investigate the use of natural language to drive the generalization of policies in multi-agent settings. Unlike single-agent settings, the generalization of policies should also consider the influence of other agents. Besides, with the increasing number of entities in multi-agent settings, more agent-entity interactions are needed for language grounding, and the enormous search space could impede the learning process. Moreover, given a simple general instruction,e.g., beating all enemies, agents are required to decompose it into multiple subgoals and figure out the right one to focus on. Inspired by previous work, we try to address these issues at the entity level and propose a novel framework for language grounding in multi-agent reinforcement learning, entity divider (EnDi). EnDi enables agents to independently learn subgoal division at the entity level and act in the environment based on the associated entities. The subgoal division is regularized by opponent modeling to avoid subgoal conflicts and promote coordinated strategies. Empirically, EnDi demonstrates the strong generalization ability to unseen games with new dynamics and expresses the superiority over existing methods.