 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARA: Few-shot Budget Allocation in Online Advertising via In-Context Decision Making with RL-Finetuned LLMs
Jan 21, 2026Optimizing the advertiser's cumulative value of winning impressions under budget constraints poses a complex challenge in online advertising, under the paradigm of AI-Generated Bidding (AIGB). Advertisers often have personalized objectives but limited historical interaction data, resulting in few-shot scenarios where traditional reinforcement learning (RL) methods struggle to perform effectively. Large Language Models (LLMs) offer a promising alternative for AIGB by leveraging their in-context learning capabilities to generalize from limited data. However, they lack the numerical precision required for fine-grained optimization. To address this limitation, we introduce GRPO-Adaptive, an efficient LLM post-training strategy that enhances both reasoning and numerical precision by dynamically updating the reference policy during training. Built upon this foundation, we further propose DARA, a novel dual-phase framework that decomposes the decision-making process into two stages: a few-shot reasoner that generates initial plans via in-context prompting, and a fine-grained optimizer that refines these plans using feedback-driven reasoning. This separation allows DARA to combine LLMs' in-context learning strengths with precise adaptability required by AIGB tasks. Extensive experiments on both real-world and synthetic data environments demonstrate that our approach consistently outperforms existing baselines in terms of cumulative advertiser value under budget constraints.
MEgoHand: Multimodal Egocentric Hand-Object Interaction Motion Generation
May 22, 2025Egocentric hand-object motion generation is crucial for immersive AR/VR and robotic imitation but remains challenging due to unstable viewpoints, self-occlusions, perspective distortion, and noisy ego-motion. Existing methods rely on predefined 3D object priors, limiting generalization to novel objects, which restricts their generalizability to novel objects. Meanwhile, recent multimodal approaches suffer from ambiguous generation from abstract textual cues, intricate pipelines for modeling 3D hand-object correlation, and compounding errors in open-loop prediction. We propose MEgoHand, a multimodal framework that synthesizes physically plausible hand-object interactions from egocentric RGB, text, and initial hand pose. MEgoHand introduces a bi-level architecture: a high-level "cerebrum" leverages a vision language model (VLM) to infer motion priors from visual-textual context and a monocular depth estimator for object-agnostic spatial reasoning, while a low-level DiT-based flow-matching policy generates fine-grained trajectories with temporal orthogonal filtering to enhance stability. To address dataset inconsistency, we design a dataset curation paradigm with an Inverse MANO Retargeting Network and Virtual RGB-D Renderer, curating a unified dataset of 3.35M RGB-D frames, 24K interactions, and 1.2K objects. Extensive experiments across five in-domain and two cross-domain datasets demonstrate the effectiveness of MEgoHand, achieving substantial reductions in wrist translation error (86.9%) and joint rotation error (34.1%), highlighting its capacity to accurately model fine-grained hand joint structures and generalize robustly across diverse scenarios.
Accelerated Markov Chain Monte Carlo Algorithms on Discrete States
May 19, 2025We propose a class of discrete state sampling algorithms based on Nesterov's accelerated gradient method, which extends the classical Metropolis-Hastings (MH) algorithm. The evolution of the discrete states probability distribution governed by MH can be interpreted as a gradient descent direction of the Kullback--Leibler (KL) divergence, via a mobility function and a score function. Specifically, this gradient is defined on a probability simplex equipped with a discrete Wasserstein-2 metric with a mobility function. This motivates us to study a momentum-based acceleration framework using damped Hamiltonian flows on the simplex set, whose stationary distribution matches the discrete target distribution. Furthermore, we design an interacting particle system to approximate the proposed accelerated sampling dynamics. The extension of the algorithm with a general choice of potentials and mobilities is also discussed. In particular, we choose the accelerated gradient flow of the relative Fisher information, demonstrating the advantages of the algorithm in estimating discrete score functions without requiring the normalizing constant and keeping positive probabilities. Numerical examples, including sampling on a Gaussian mixture supported on lattices or a distribution on a hypercube, demonstrate the effectiveness of the proposed discrete-state sampling algorithm.
Sobolev Gradient Ascent for Optimal Transport: Barycenter Optimization and Convergence Analysis
May 19, 2025This paper introduces a new constraint-free concave dual formulation for the Wasserstein barycenter. Tailoring the vanilla dual gradient ascent algorithm to the Sobolev geometry, we derive a scalable Sobolev gradient ascent (SGA) algorithm to compute the barycenter for input distributions supported on a regular grid. Despite the algorithmic simplicity, we provide a global convergence analysis that achieves the same rate as the classical subgradient descent methods for minimizing nonsmooth convex functions in the Euclidean space. A central feature of our SGA algorithm is that the computationally expensive $c$-concavity projection operator enforced on the Kantorovich dual potentials is unnecessary to guarantee convergence, leading to significant algorithmic and theoretical simplifications over all existing primal and dual methods for computing the exact barycenter. Our numerical experiments demonstrate the superior empirical performance of SGA over the existing optimal transport barycenter solvers.
Being-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills
Mar 16, 2025Building autonomous robotic agents capable of achieving human-level performance in real-world embodied tasks is an ultimate goal in humanoid robot research. Recent advances have made significant progress in high-level cognition with Foundation Models (FMs) and low-level skill development for humanoid robots. However, directly combining these components often results in poor robustness and efficiency due to compounding errors in long-horizon tasks and the varied latency of different modules. We introduce Being-0, a hierarchical agent framework that integrates an FM with a modular skill library. The FM handles high-level cognitive tasks such as instruction understanding, task planning, and reasoning, while the skill library provides stable locomotion and dexterous manipulation for low-level control. To bridge the gap between these levels, we propose a novel Connector module, powered by a lightweight vision-language model (VLM). The Connector enhances the FM's embodied capabilities by translating language-based plans into actionable skill commands and dynamically coordinating locomotion and manipulation to improve task success. With all components, except the FM, deployable on low-cost onboard computation devices, Being-0 achieves efficient, real-time performance on a full-sized humanoid robot equipped with dexterous hands and active vision. Extensive experiments in large indoor environments demonstrate Being-0's effectiveness in solving complex, long-horizon tasks that require challenging navigation and manipulation subtasks. For further details and videos, visit https://beingbeyond.github.io/being-0.
Pre-trained Visual Dynamics Representations for Efficient Policy Learning
Nov 05, 2024Pre-training for Reinforcement Learning (RL) with purely video data is a valuable yet challenging problem. Although in-the-wild videos are readily available and inhere a vast amount of prior world knowledge, the absence of action annotations and the common domain gap with downstream tasks hinder utilizing videos for RL pre-training. To address the challenge of pre-training with videos, we propose Pre-trained Visual Dynamics Representations (PVDR) to bridge the domain gap between videos and downstream tasks for efficient policy learning. By adopting video prediction as a pre-training task, we use a Transformer-based Conditional Variational Autoencoder (CVAE) to learn visual dynamics representations. The pre-trained visual dynamics representations capture the visual dynamics prior knowledge in the videos. This abstract prior knowledge can be readily adapted to downstream tasks and aligned with executable actions through online adaptation. We conduct experiments on a series of robotics visual control tasks and verify that PVDR is an effective form for pre-training with videos to promote policy learning.
Learning Diverse Bimanual Dexterous Manipulation Skills from Human Demonstrations
Oct 03, 2024Bimanual dexterous manipulation is a critical yet underexplored area in robotics. Its high-dimensional action space and inherent task complexity present significant challenges for policy learning, and the limited task diversity in existing benchmarks hinders general-purpose skill development. Existing approaches largely depend on reinforcement learning, often constrained by intricately designed reward functions tailored to a narrow set of tasks. In this work, we present a novel approach for efficiently learning diverse bimanual dexterous skills from abundant human demonstrations. Specifically, we introduce BiDexHD, a framework that unifies task construction from existing bimanual datasets and employs teacher-student policy learning to address all tasks. The teacher learns state-based policies using a general two-stage reward function across tasks with shared behaviors, while the student distills the learned multi-task policies into a vision-based policy. With BiDexHD, scalable learning of numerous bimanual dexterous skills from auto-constructed tasks becomes feasible, offering promising advances toward universal bimanual dexterous manipulation. Our empirical evaluation on the TACO dataset, spanning 141 tasks across six categories, demonstrates a task fulfillment rate of 74.59% on trained tasks and 51.07% on unseen tasks, showcasing the effectiveness and competitive zero-shot generalization capabilities of BiDexHD. For videos and more information, visit our project page https://sites.google.com/view/bidexhd.
Cross-Embodiment Dexterous Grasping with Reinforcement Learning
Oct 03, 2024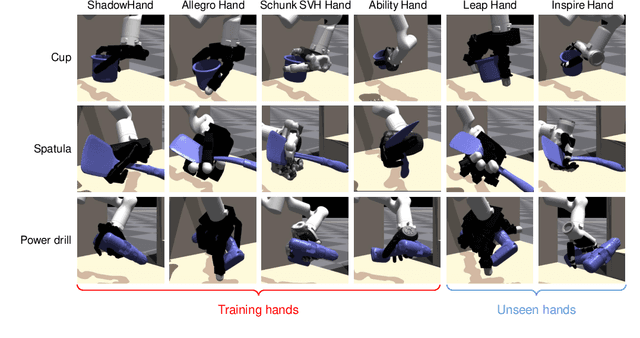

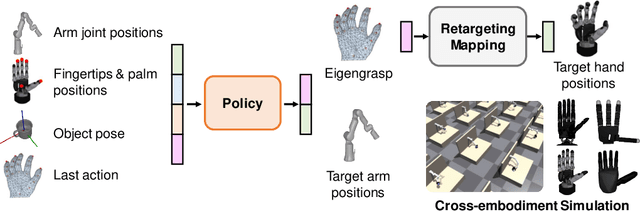

Dexterous hands exhibit significant potential for complex real-world grasping tasks. While recent studies have primarily focused on learning policies for specific robotic hands, the development of a universal policy that controls diverse dexterous hands remains largely unexplored. In this work, we study the learning of cross-embodiment dexterous grasping policies using reinforcement learning (RL). Inspired by the capability of human hands to control various dexterous hands through teleoperation, we propose a universal action space based on the human hand's eigengrasps. The policy outputs eigengrasp actions that are then converted into specific joint actions for each robot hand through a retargeting mapping. We simplify the robot hand's proprioception to include only the positions of fingertips and the palm, offering a unified observation space across different robot hands. Our approach demonstrates an 80% success rate in grasping objects from the YCB dataset across four distinct embodiments using a single vision-based policy. Additionally, our policy exhibits zero-shot generalization to two previously unseen embodiments and significant improvement in efficient finetuning. For further details and videos, visit our project page https://sites.google.com/view/crossdex.
NOLO: Navigate Only Look Once
Aug 02, 2024The in-context learning ability of Transformer models has brought new possibilities to visual navigation. In this paper, we focus on the video navigation setting, where an in-context navigation policy needs to be learned purely from videos in an offline manner, without access to the actual environment. For this setting, we propose Navigate Only Look Once (NOLO), a method for learning a navigation policy that possesses the in-context ability and adapts to new scenes by taking corresponding context videos as input without finetuning or re-training. To enable learning from videos, we first propose a pseudo action labeling procedure using optical flow to recover the action label from egocentric videos. Then, offline reinforcement learning is applied to learn the navigation policy. Through extensive experiments on different scenes, we show that our algorithm outperforms baselines by a large margin, which demonstrates the in-context learning ability of the learned policy.
UniCode: Learning a Unified Codebook for Multimodal Large Language Models
Mar 14, 2024In this paper, we propose \textbf{UniCode}, a novel approach within the domain of multimodal large language models (MLLMs) that learns a unified codebook to efficiently tokenize visual, text, and potentially other types of signals. This innovation addresses a critical limitation in existing MLLMs: their reliance on a text-only codebook, which restricts MLLM's ability to generate images and texts in a multimodal context. Towards this end, we propose a language-driven iterative training paradigm, coupled with an in-context pre-training task we term ``image decompression'', enabling our model to interpret compressed visual data and generate high-quality images.The unified codebook empowers our model to extend visual instruction tuning to non-linguistic generation tasks. Moreover, UniCode is adaptable to diverse stacked quantization approaches in order to compress visual signals into a more compact token representation. Despite using significantly fewer parameters and less data during training, Unicode demonstrates promising capabilities in visual reconstruction and generation. It also achieves performances comparable to leading MLLMs across a spectrum of VQA benchmarks.