 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Regularized Wasserstein Proximal Sampling Algorithms
Jan 16, 2026We consider sampling from a Gibbs distribution by evolving a finite number of particles using a particular score estimator rather than Brownian motion. To accelerate the particles, we consider a second-order score-based ODE, similar to Nesterov acceleration. In contrast to traditional kernel density score estimation, we use the recently proposed regularized Wasserstein proximal method, yielding the Accelerated Regularized Wasserstein Proximal method (ARWP). We provide a detailed analysis of continuous- and discrete-time non-asymptotic and asymptotic mixing rates for Gaussian initial and target distributions, using techniques from Euclidean acceleration and accelerated information gradients. Compared with the kinetic Langevin sampling algorithm, the proposed algorithm exhibits a higher contraction rate in the asymptotic time regime. Numerical experiments are conducted across various low-dimensional experiments, including multi-modal Gaussian mixtures and ill-conditioned Rosenbrock distributions. ARWP exhibits structured and convergent particles, accelerated discrete-time mixing, and faster tail exploration than the non-accelerated regularized Wasserstein proximal method and kinetic Langevin methods. Additionally, ARWP particles exhibit better generalization properties for some non-log-concave Bayesian neural network tasks.
Towards understanding Accelerated Stein Variational Gradient Flow -- Analysis of Generalized Bilinear Kernels for Gaussian target distributions
Sep 04, 2025Stein variational gradient descent (SVGD) is a kernel-based and non-parametric particle method for sampling from a target distribution, such as in Bayesian inference and other machine learning tasks. Different from other particle methods, SVGD does not require estimating the score, which is the gradient of the log-density. However, in practice, SVGD can be slow compared to score-estimation-based sampling algorithms. To design a fast and efficient high-dimensional sampling algorithm with the advantages of SVGD, we introduce accelerated SVGD (ASVGD), based on an accelerated gradient flow in a metric space of probability densities following Nesterov's method. We then derive a momentum-based discrete-time sampling algorithm, which evolves a set of particles deterministically. To stabilize the particles' position update, we also include a Wasserstein metric regularization. This paper extends the conference version \cite{SL2025}. For the bilinear kernel and Gaussian target distributions, we study the kernel parameter and damping parameters with an optimal convergence rate of the proposed dynamics. This is achieved by analyzing the linearized accelerated gradient flows at the equilibrium. Interestingly, the optimal parameter is a constant, which does not depend on the covariance of the target distribution. For the generalized kernel functions, such as the Gaussian kernel, numerical examples with varied target distributions demonstrate the effectiveness of ASVGD compared to SVGD and other popular sampling methods. Furthermore, we show that in the setting of Bayesian neural networks, ASVGD outperforms SVGD significantly in terms of log-likelihood and total iteration times.
Accelerated Markov Chain Monte Carlo Algorithms on Discrete States
May 19, 2025We propose a class of discrete state sampling algorithms based on Nesterov's accelerated gradient method, which extends the classical Metropolis-Hastings (MH) algorithm. The evolution of the discrete states probability distribution governed by MH can be interpreted as a gradient descent direction of the Kullback--Leibler (KL) divergence, via a mobility function and a score function. Specifically, this gradient is defined on a probability simplex equipped with a discrete Wasserstein-2 metric with a mobility function. This motivates us to study a momentum-based acceleration framework using damped Hamiltonian flows on the simplex set, whose stationary distribution matches the discrete target distribution. Furthermore, we design an interacting particle system to approximate the proposed accelerated sampling dynamics. The extension of the algorithm with a general choice of potentials and mobilities is also discussed. In particular, we choose the accelerated gradient flow of the relative Fisher information, demonstrating the advantages of the algorithm in estimating discrete score functions without requiring the normalizing constant and keeping positive probabilities. Numerical examples, including sampling on a Gaussian mixture supported on lattices or a distribution on a hypercube, demonstrate the effectiveness of the proposed discrete-state sampling algorithm.
Transport f divergences
Apr 22, 2025We define a class of divergences to measure differences between probability density functions in one-dimensional sample space. The construction is based on the convex function with the Jacobi operator of mapping function that pushforwards one density to the other. We call these information measures {\em transport $f$-divergences}. We present several properties of transport $f$-divergences, including invariances, convexities, variational formulations, and Taylor expansions in terms of mapping functions. Examples of transport $f$-divergences in generative models are provided.
Accelerated Stein Variational Gradient Flow
Mar 30, 2025

Stein variational gradient descent (SVGD) is a kernel-based particle method for sampling from a target distribution, e.g., in generative modeling and Bayesian inference. SVGD does not require estimating the gradient of the log-density, which is called score estimation. In practice, SVGD can be slow compared to score-estimation based sampling algorithms. To design fast and efficient high-dimensional sampling algorithms, we introduce ASVGD, an accelerated SVGD, based on an accelerated gradient flow in a metric space of probability densities following Nesterov's method. We then derive a momentum-based discrete-time sampling algorithm, which evolves a set of particles deterministically. To stabilize the particles' momentum update, we also study a Wasserstein metric regularization. For the generalized bilinear kernel and the Gaussian kernel, toy numerical examples with varied target distributions demonstrate the effectiveness of ASVGD compared to SVGD and other popular sampling methods.
A Natural Primal-Dual Hybrid Gradient Method for Adversarial Neural Network Training on Solving Partial Differential Equations
Nov 09, 2024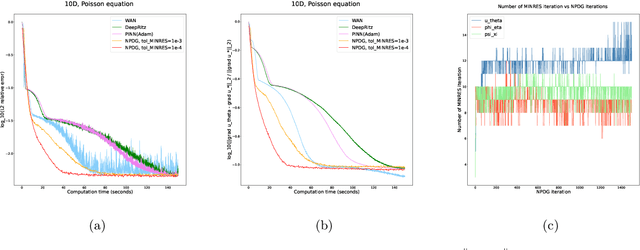

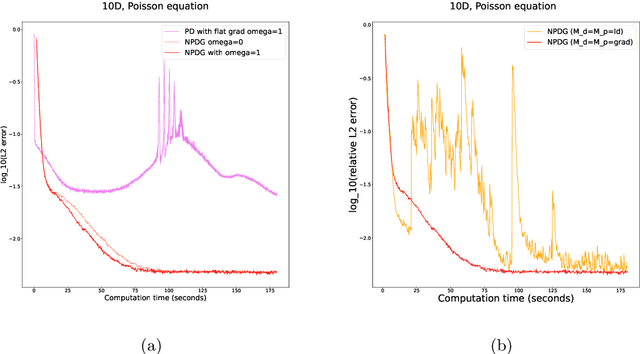
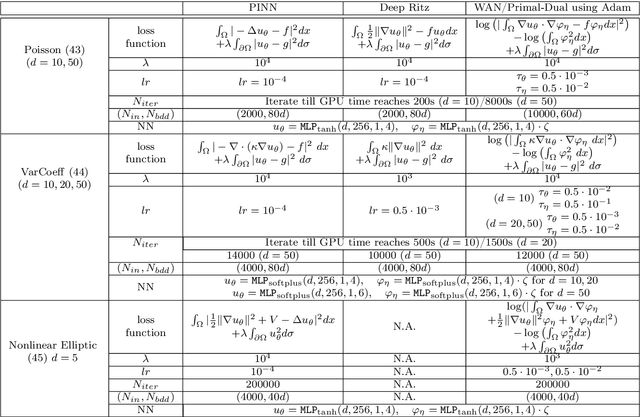
We propose a scalable preconditioned primal-dual hybrid gradient algorithm for solving partial differential equations (PDEs). We multiply the PDE with a dual test function to obtain an inf-sup problem whose loss functional involves lower-order differential operators. The Primal-Dual Hybrid Gradient (PDHG) algorithm is then leveraged for this saddle point problem. By introducing suitable precondition operators to the proximal steps in the PDHG algorithm, we obtain an alternative natural gradient ascent-descent optimization scheme for updating the neural network parameters. We apply the Krylov subspace method (MINRES) to evaluate the natural gradients efficiently. Such treatment readily handles the inversion of precondition matrices via matrix-vector multiplication. A posterior convergence analysis is established for the time-continuous version of the proposed method. The algorithm is tested on various types of PDEs with dimensions ranging from $1$ to $50$, including linear and nonlinear elliptic equations, reaction-diffusion equations, and Monge-Amp\`ere equations stemming from the $L^2$ optimal transport problems. We compare the performance of the proposed method with several commonly used deep learning algorithms such as physics-informed neural networks (PINNs), the DeepRitz method, weak adversarial networks (WANs), etc, for solving PDEs using the Adam and L-BFGS optimizers. The numerical results suggest that the proposed method performs efficiently and robustly and converges more stably.
Score-based Neural Ordinary Differential Equations for Computing Mean Field Control Problems
Sep 24, 2024
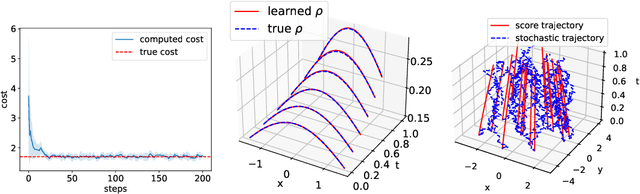

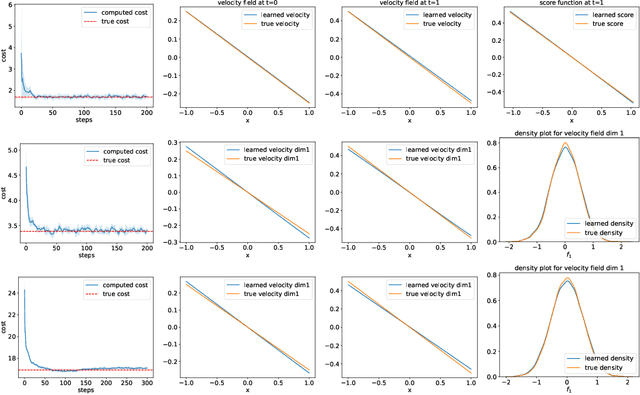
Classical neural ordinary differential equations (ODEs) are powerful tools for approximating the log-density functions in high-dimensional spaces along trajectories, where neural networks parameterize the velocity fields. This paper proposes a system of neural differential equations representing first- and second-order score functions along trajectories based on deep neural networks. We reformulate the mean field control (MFC) problem with individual noises into an unconstrained optimization problem framed by the proposed neural ODE system. Additionally, we introduce a novel regularization term to enforce characteristics of viscous Hamilton--Jacobi--Bellman (HJB) equations to be satisfied based on the evolution of the second-order score function. Examples include regularized Wasserstein proximal operators (RWPOs), probability flow matching of Fokker--Planck (FP) equations, and linear quadratic (LQ) MFC problems, which demonstrate the effectiveness and accuracy of the proposed method.
Wasserstein proximal operators describe score-based generative models and resolve memorization
Feb 09, 2024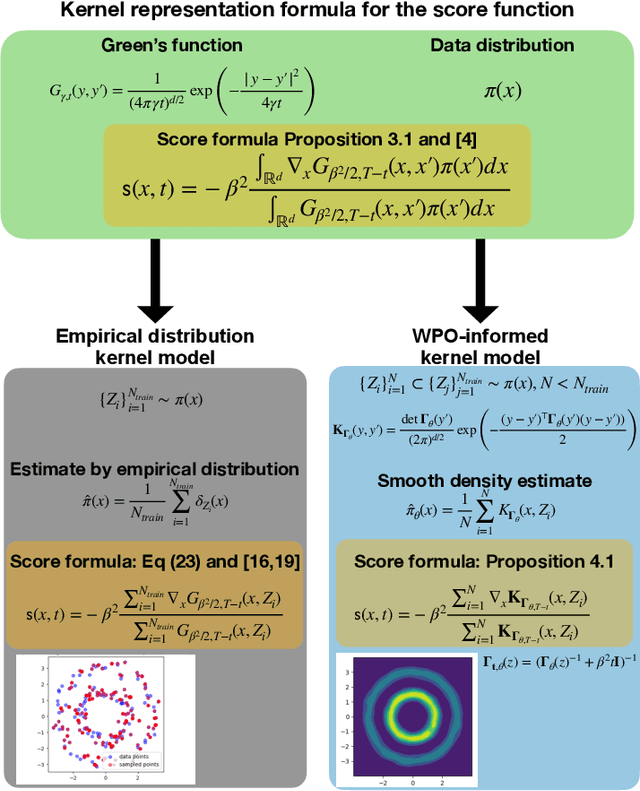
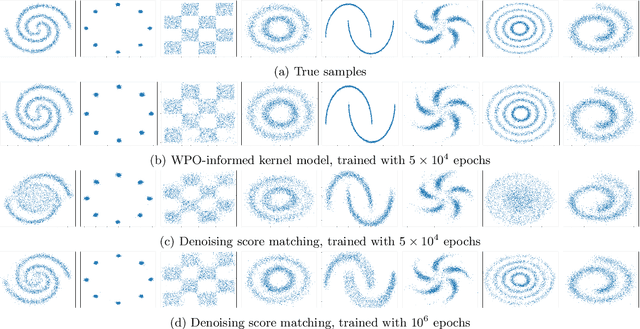
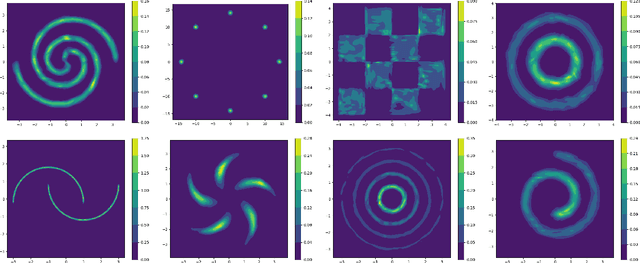
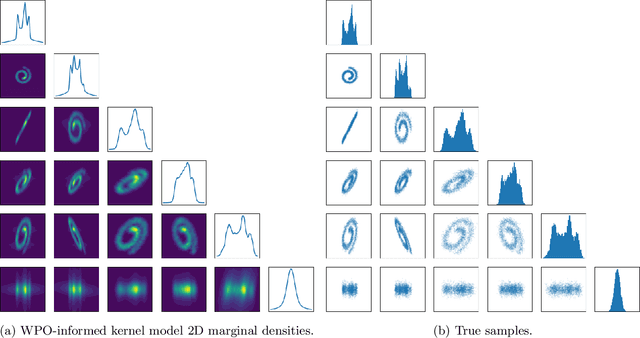
We focus on the fundamental mathematical structure of score-based generative models (SGMs). We first formulate SGMs in terms of the Wasserstein proximal operator (WPO) and demonstrate that, via mean-field games (MFGs), the WPO formulation reveals mathematical structure that describes the inductive bias of diffusion and score-based models. In particular, MFGs yield optimality conditions in the form of a pair of coupled partial differential equations: a forward-controlled Fokker-Planck (FP) equation, and a backward Hamilton-Jacobi-Bellman (HJB) equation. Via a Cole-Hopf transformation and taking advantage of the fact that the cross-entropy can be related to a linear functional of the density, we show that the HJB equation is an uncontrolled FP equation. Second, with the mathematical structure at hand, we present an interpretable kernel-based model for the score function which dramatically improves the performance of SGMs in terms of training samples and training time. In addition, the WPO-informed kernel model is explicitly constructed to avoid the recently studied memorization effects of score-based generative models. The mathematical form of the new kernel-based models in combination with the use of the terminal condition of the MFG reveals new explanations for the manifold learning and generalization properties of SGMs, and provides a resolution to their memorization effects. Finally, our mathematically informed, interpretable kernel-based model suggests new scalable bespoke neural network architectures for high-dimensional applications.
Fisher information dissipation for time inhomogeneous stochastic differential equations
Feb 01, 2024



We provide a Lyapunov convergence analysis for time-inhomogeneous variable coefficient stochastic differential equations (SDEs). Three typical examples include overdamped, irreversible drift, and underdamped Langevin dynamics. We first formula the probability transition equation of Langevin dynamics as a modified gradient flow of the Kullback-Leibler divergence in the probability space with respect to time-dependent optimal transport metrics. This formulation contains both gradient and non-gradient directions depending on a class of time-dependent target distribution. We then select a time-dependent relative Fisher information functional as a Lyapunov functional. We develop a time-dependent Hessian matrix condition, which guarantees the convergence of the probability density function of the SDE. We verify the proposed conditions for several time-inhomogeneous Langevin dynamics. For the overdamped Langevin dynamics, we prove the $O(t^{-1/2})$ convergence in $L^1$ distance for the simulated annealing dynamics with a strongly convex potential function. For the irreversible drift Langevin dynamics, we prove an improved convergence towards the target distribution in an asymptotic regime. We also verify the convergence condition for the underdamped Langevin dynamics. Numerical examples demonstrate the convergence results for the time-dependent Langevin dynamics.
Scaling Limits of the Wasserstein information matrix on Gaussian Mixture Models
Sep 22, 2023We consider the Wasserstein metric on the Gaussian mixture models (GMMs), which is defined as the pullback of the full Wasserstein metric on the space of smooth probability distributions with finite second moment. It derives a class of Wasserstein metrics on probability simplices over one-dimensional bounded homogeneous lattices via a scaling limit of the Wasserstein metric on GMMs. Specifically, for a sequence of GMMs whose variances tend to zero, we prove that the limit of the Wasserstein metric exists after certain renormalization. Generalizations of this metric in general GMMs are established, including inhomogeneous lattice models whose lattice gaps are not the same, extended GMMs whose mean parameters of Gaussian components can also change, and the second-order metric containing high-order information of the scaling limit. We further study the Wasserstein gradient flows on GMMs for three typical functionals: potential, internal, and interaction energies. Numerical examples demonstrate the effectiveness of the proposed GMM models for approximating Wasserstein gradient flows.