 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein proximal operators describe score-based generative models and resolve memorization
Paper and Code
Feb 09, 2024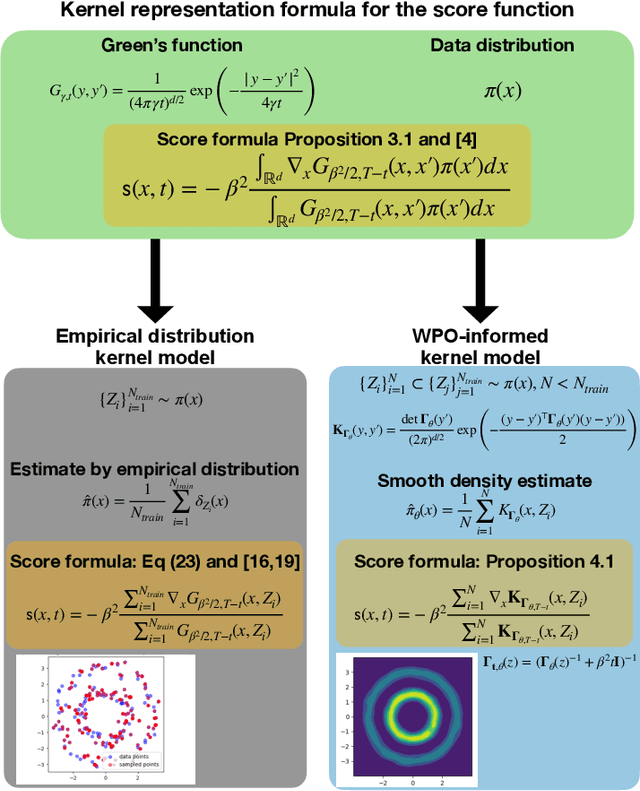
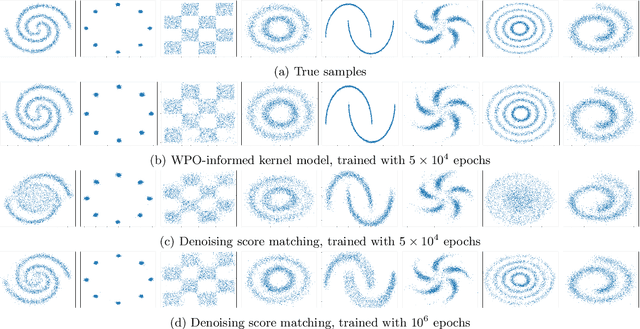
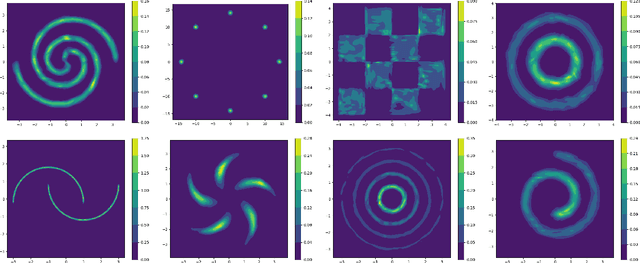
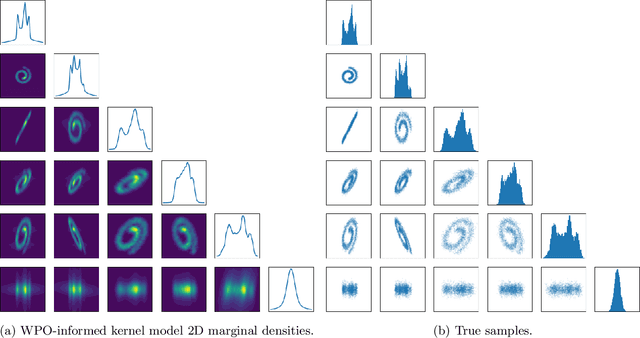
We focus on the fundamental mathematical structure of score-based generative models (SGMs). We first formulate SGMs in terms of the Wasserstein proximal operator (WPO) and demonstrate that, via mean-field games (MFGs), the WPO formulation reveals mathematical structure that describes the inductive bias of diffusion and score-based models. In particular, MFGs yield optimality conditions in the form of a pair of coupled partial differential equations: a forward-controlled Fokker-Planck (FP) equation, and a backward Hamilton-Jacobi-Bellman (HJB) equation. Via a Cole-Hopf transformation and taking advantage of the fact that the cross-entropy can be related to a linear functional of the density, we show that the HJB equation is an uncontrolled FP equation. Second, with the mathematical structure at hand, we present an interpretable kernel-based model for the score function which dramatically improves the performance of SGMs in terms of training samples and training time. In addition, the WPO-informed kernel model is explicitly constructed to avoid the recently studied memorization effects of score-based generative models. The mathematical form of the new kernel-based models in combination with the use of the terminal condition of the MFG reveals new explanations for the manifold learning and generalization properties of SGMs, and provides a resolution to their memorization effects. Finally, our mathematically informed, interpretable kernel-based model suggests new scalable bespoke neural network architectures for high-dimensional applications.