 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeing-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
Jan 19, 2026We introduce Being-H0.5, a foundational Vision-Language-Action (VLA) model designed for robust cross-embodiment generalization across diverse robotic platforms. While existing VLAs often struggle with morphological heterogeneity and data scarcity, we propose a human-centric learning paradigm that treats human interaction traces as a universal "mother tongue" for physical interaction. To support this, we present UniHand-2.0, the largest embodied pre-training recipe to date, comprising over 35,000 hours of multimodal data across 30 distinct robotic embodiments. Our approach introduces a Unified Action Space that maps heterogeneous robot controls into semantically aligned slots, enabling low-resource robots to bootstrap skills from human data and high-resource platforms. Built upon this human-centric foundation, we design a unified sequential modeling and multi-task pre-training paradigm to bridge human demonstrations and robotic execution. Architecturally, Being-H0.5 utilizes a Mixture-of-Transformers design featuring a novel Mixture-of-Flow (MoF) framework to decouple shared motor primitives from specialized embodiment-specific experts. Finally, to make cross-embodiment policies stable in the real world, we introduce Manifold-Preserving Gating for robustness under sensory shift and Universal Async Chunking to universalize chunked control across embodiments with different latency and control profiles. We empirically demonstrate that Being-H0.5 achieves state-of-the-art results on simulated benchmarks, such as LIBERO (98.9%) and RoboCasa (53.9%), while also exhibiting strong cross-embodiment capabilities on five robotic platforms.
Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos
Dec 15, 2025Vision-Language-Action (VLA) models provide a promising paradigm for robot learning by integrating visual perception with language-guided policy learning. However, most existing approaches rely on 2D visual inputs to perform actions in 3D physical environments, creating a significant gap between perception and action grounding. To bridge this gap, we propose a Spatial-Aware VLA Pretraining paradigm that performs explicit alignment between visual space and physical space during pretraining, enabling models to acquire 3D spatial understanding before robot policy learning. Starting from pretrained vision-language models, we leverage large-scale human demonstration videos to extract 3D visual and 3D action annotations, forming a new source of supervision that aligns 2D visual observations with 3D spatial reasoning. We instantiate this paradigm with VIPA-VLA, a dual-encoder architecture that incorporates a 3D visual encoder to augment semantic visual representations with 3D-aware features. When adapted to downstream robot tasks, VIPA-VLA achieves significantly improved grounding between 2D vision and 3D action, resulting in more robust and generalizable robotic policies.
Being-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills
Mar 16, 2025Building autonomous robotic agents capable of achieving human-level performance in real-world embodied tasks is an ultimate goal in humanoid robot research. Recent advances have made significant progress in high-level cognition with Foundation Models (FMs) and low-level skill development for humanoid robots. However, directly combining these components often results in poor robustness and efficiency due to compounding errors in long-horizon tasks and the varied latency of different modules. We introduce Being-0, a hierarchical agent framework that integrates an FM with a modular skill library. The FM handles high-level cognitive tasks such as instruction understanding, task planning, and reasoning, while the skill library provides stable locomotion and dexterous manipulation for low-level control. To bridge the gap between these levels, we propose a novel Connector module, powered by a lightweight vision-language model (VLM). The Connector enhances the FM's embodied capabilities by translating language-based plans into actionable skill commands and dynamically coordinating locomotion and manipulation to improve task success. With all components, except the FM, deployable on low-cost onboard computation devices, Being-0 achieves efficient, real-time performance on a full-sized humanoid robot equipped with dexterous hands and active vision. Extensive experiments in large indoor environments demonstrate Being-0's effectiveness in solving complex, long-horizon tasks that require challenging navigation and manipulation subtasks. For further details and videos, visit https://beingbeyond.github.io/being-0.
Echo: Simulating Distributed Training At Scale
Dec 17, 2024


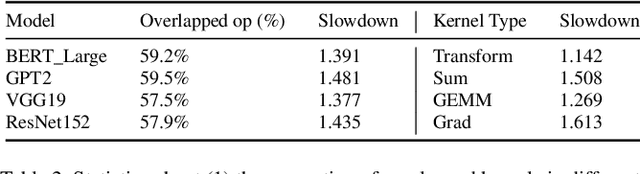
Simulation offers unique values for both enumeration and extrapolation purposes, and is becoming increasingly important for managing the massive machine learning (ML) clusters and large-scale distributed training jobs. In this paper, we build Echo to tackle three key challenges in large-scale training simulation: (1) tracing the runtime training workloads at each device in an ex-situ fashion so we can use a single device to obtain the actual execution graphs of 1K-GPU training, (2) accurately estimating the collective communication without high overheads of discrete-event based network simulation, and (3) accounting for the interference-induced computation slowdown from overlapping communication and computation kernels on the same device. Echo delivers on average 8% error in training step -- roughly 3x lower than state-of-the-art simulators -- for GPT-175B on a 96-GPU H800 cluster with 3D parallelism on Megatron-LM under 2 minutes.
VideoOrion: Tokenizing Object Dynamics in Videos
Nov 25, 2024We present VideoOrion, a Video Large Language Model (Video-LLM) that explicitly captures the key semantic information in videos--the spatial-temporal dynamics of objects throughout the videos. VideoOrion employs expert vision models to extract object dynamics through a detect-segment-track pipeline, encoding them into a set of object tokens by aggregating spatial-temporal object features. Our method addresses the persistent challenge in Video-LLMs of efficiently compressing high-dimensional video data into semantic tokens that are comprehensible to LLMs. Compared to prior methods which resort to downsampling the original video or aggregating visual tokens using resamplers, leading to information loss and entangled semantics, VideoOrion not only offers a more natural and efficient way to derive compact, disentangled semantic representations but also enables explicit object modeling of video content with minimal computational cost. Moreover, the introduced object tokens naturally allow VideoOrion to accomplish video-based referring tasks. Experimental results show that VideoOrion can learn to make good use of the object tokens, and achieves competitive results on both general video question answering and video-based referring benchmarks.
From Pixels to Tokens: Byte-Pair Encoding on Quantized Visual Modalities
Oct 03, 2024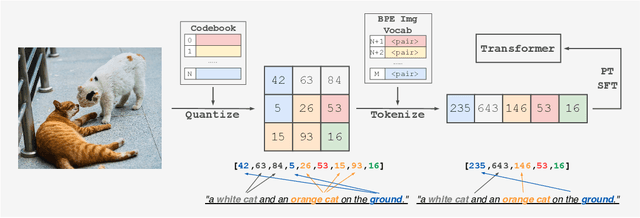
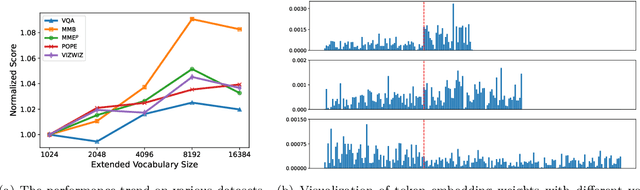
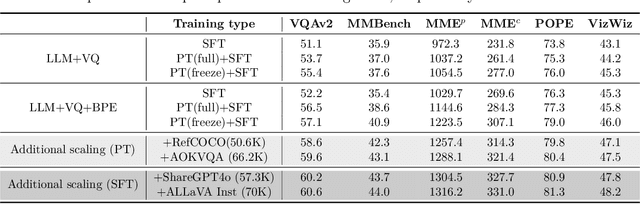
Multimodal Large Language Models have made significant strides in integrating visual and textual information, yet they often struggle with effectively aligning these modalities. We introduce a novel image tokenizer that bridges this gap by applying the principle of Byte-Pair Encoding (BPE) to visual data. Unlike conventional approaches that rely on separate visual encoders, our method directly incorporates structural prior information into image tokens, mirroring the successful tokenization strategies used in text-only Large Language Models. This innovative approach enables Transformer models to more effectively learn and reason across modalities. Through theoretical analysis and extensive experiments, we demonstrate that our BPE Image Tokenizer significantly enhances MLLMs' multimodal understanding capabilities, even with limited training data. Our method not only improves performance across various benchmarks but also shows promising scalability, potentially paving the way for more efficient and capable multimodal foundation models.
UniCode: Learning a Unified Codebook for Multimodal Large Language Models
Mar 14, 2024In this paper, we propose \textbf{UniCode}, a novel approach within the domain of multimodal large language models (MLLMs) that learns a unified codebook to efficiently tokenize visual, text, and potentially other types of signals. This innovation addresses a critical limitation in existing MLLMs: their reliance on a text-only codebook, which restricts MLLM's ability to generate images and texts in a multimodal context. Towards this end, we propose a language-driven iterative training paradigm, coupled with an in-context pre-training task we term ``image decompression'', enabling our model to interpret compressed visual data and generate high-quality images.The unified codebook empowers our model to extend visual instruction tuning to non-linguistic generation tasks. Moreover, UniCode is adaptable to diverse stacked quantization approaches in order to compress visual signals into a more compact token representation. Despite using significantly fewer parameters and less data during training, Unicode demonstrates promising capabilities in visual reconstruction and generation. It also achieves performances comparable to leading MLLMs across a spectrum of VQA benchmarks.
Steve-Eye: Equipping LLM-based Embodied Agents with Visual Perception in Open Worlds
Oct 20, 2023



Recent studies have presented compelling evidence that large language models (LLMs) can equip embodied agents with the self-driven capability to interact with the world, which marks an initial step toward versatile robotics. However, these efforts tend to overlook the visual richness of open worlds, rendering the entire interactive process akin to "a blindfolded text-based game." Consequently, LLM-based agents frequently encounter challenges in intuitively comprehending their surroundings and producing responses that are easy to understand. In this paper, we propose Steve-Eye, an end-to-end trained large multimodal model designed to address this limitation. Steve-Eye integrates the LLM with a visual encoder which enables it to process visual-text inputs and generate multimodal feedback. In addition, we use a semi-automatic strategy to collect an extensive dataset comprising 850K open-world instruction pairs, empowering our model to encompass three essential functions for an agent: multimodal perception, foundational knowledge base, and skill prediction and planning. Lastly, we develop three open-world evaluation benchmarks, then carry out extensive experiments from a wide range of perspectives to validate our model's capability to strategically act and plan. Codes and datasets will be released.
LLaMA Rider: Spurring Large Language Models to Explore the Open World
Oct 13, 2023



Recently, various studies have leveraged Large Language Models (LLMs) to help decision-making and planning in environments, and try to align the LLMs' knowledge with the world conditions. Nonetheless, the capacity of LLMs to continuously acquire environmental knowledge and adapt in an open world remains uncertain. In this paper, we propose an approach to spur LLMs to explore the open world, gather experiences, and learn to improve their task-solving capabilities. In this approach, a multi-round feedback-revision mechanism is utilized to encourage LLMs to actively select appropriate revision actions guided by feedback information from the environment. This facilitates exploration and enhances the model's performance. Besides, we integrate sub-task relabeling to assist LLMs in maintaining consistency in sub-task planning and help the model learn the combinatorial nature between tasks, enabling it to complete a wider range of tasks through training based on the acquired exploration experiences. By evaluation in Minecraft, an open-ended sandbox world, we demonstrate that our approach LLaMA-Rider enhances the efficiency of the LLM in exploring the environment, and effectively improves the LLM's ability to accomplish more tasks through fine-tuning with merely 1.3k instances of collected data, showing minimal training costs compared to the baseline using reinforcement learning.
Learning Multi-Object Positional Relationships via Emergent Communication
Feb 16, 2023



The study of emergent communication has been dedicated to interactive artificial intelligence. While existing work focuses on communication about single objects or complex image scenes, we argue that communicating relationships between multiple objects is important in more realistic tasks, but understudied. In this paper, we try to fill this gap and focus on emergent communication about positional relationships between two objects. We train agents in the referential game where observations contain two objects, and find that generalization is the major problem when the positional relationship is involved. The key factor affecting the generalization ability of the emergent language is the input variation between Speaker and Listener, which is realized by a random image generator in our work. Further, we find that the learned language can generalize well in a new multi-step MDP task where the positional relationship describes the goal, and performs better than raw-pixel images as well as pre-trained image features, verifying the strong generalization ability of discrete sequences. We also show that language transfer from the referential game performs better in the new task than learning language directly in this task, implying the potential benefits of pre-training in referential games. All in all, our experiments demonstrate the viability and merit of having agents learn to communicate positional relationships between multiple objects through emergent communication.