 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeing-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills
Mar 16, 2025Building autonomous robotic agents capable of achieving human-level performance in real-world embodied tasks is an ultimate goal in humanoid robot research. Recent advances have made significant progress in high-level cognition with Foundation Models (FMs) and low-level skill development for humanoid robots. However, directly combining these components often results in poor robustness and efficiency due to compounding errors in long-horizon tasks and the varied latency of different modules. We introduce Being-0, a hierarchical agent framework that integrates an FM with a modular skill library. The FM handles high-level cognitive tasks such as instruction understanding, task planning, and reasoning, while the skill library provides stable locomotion and dexterous manipulation for low-level control. To bridge the gap between these levels, we propose a novel Connector module, powered by a lightweight vision-language model (VLM). The Connector enhances the FM's embodied capabilities by translating language-based plans into actionable skill commands and dynamically coordinating locomotion and manipulation to improve task success. With all components, except the FM, deployable on low-cost onboard computation devices, Being-0 achieves efficient, real-time performance on a full-sized humanoid robot equipped with dexterous hands and active vision. Extensive experiments in large indoor environments demonstrate Being-0's effectiveness in solving complex, long-horizon tasks that require challenging navigation and manipulation subtasks. For further details and videos, visit https://beingbeyond.github.io/being-0.
Efficient Residual Learning with Mixture-of-Experts for Universal Dexterous Grasping
Oct 03, 2024



Universal dexterous grasping across diverse objects presents a fundamental yet formidable challenge in robot learning. Existing approaches using reinforcement learning (RL) to develop policies on extensive object datasets face critical limitations, including complex curriculum design for multi-task learning and limited generalization to unseen objects. To overcome these challenges, we introduce ResDex, a novel approach that integrates residual policy learning with a mixture-of-experts (MoE) framework. ResDex is distinguished by its use of geometry-unaware base policies that are efficiently acquired on individual objects and capable of generalizing across a wide range of unseen objects. Our MoE framework incorporates several base policies to facilitate diverse grasping styles suitable for various objects. By learning residual actions alongside weights that combine these base policies, ResDex enables efficient multi-task RL for universal dexterous grasping. ResDex achieves state-of-the-art performance on the DexGraspNet dataset comprising 3,200 objects with an 88.8% success rate. It exhibits no generalization gap with unseen objects and demonstrates superior training efficiency, mastering all tasks within only 12 hours on a single GPU.
Cross-Embodiment Dexterous Grasping with Reinforcement Learning
Oct 03, 2024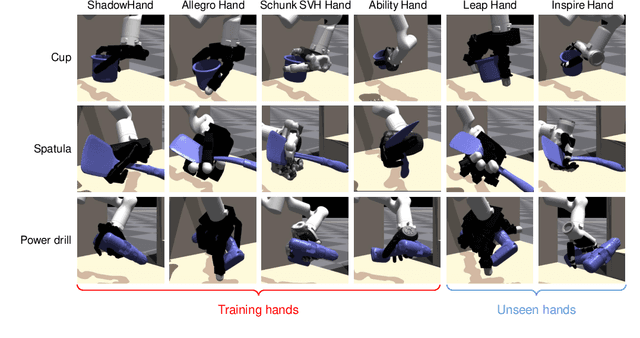

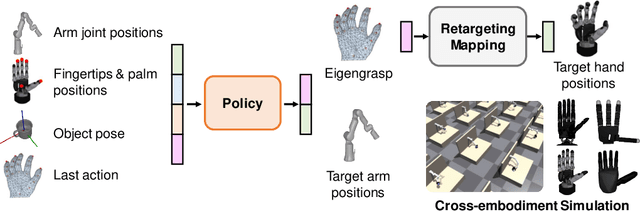

Dexterous hands exhibit significant potential for complex real-world grasping tasks. While recent studies have primarily focused on learning policies for specific robotic hands, the development of a universal policy that controls diverse dexterous hands remains largely unexplored. In this work, we study the learning of cross-embodiment dexterous grasping policies using reinforcement learning (RL). Inspired by the capability of human hands to control various dexterous hands through teleoperation, we propose a universal action space based on the human hand's eigengrasps. The policy outputs eigengrasp actions that are then converted into specific joint actions for each robot hand through a retargeting mapping. We simplify the robot hand's proprioception to include only the positions of fingertips and the palm, offering a unified observation space across different robot hands. Our approach demonstrates an 80% success rate in grasping objects from the YCB dataset across four distinct embodiments using a single vision-based policy. Additionally, our policy exhibits zero-shot generalization to two previously unseen embodiments and significant improvement in efficient finetuning. For further details and videos, visit our project page https://sites.google.com/view/crossdex.
Learning Diverse Bimanual Dexterous Manipulation Skills from Human Demonstrations
Oct 03, 2024Bimanual dexterous manipulation is a critical yet underexplored area in robotics. Its high-dimensional action space and inherent task complexity present significant challenges for policy learning, and the limited task diversity in existing benchmarks hinders general-purpose skill development. Existing approaches largely depend on reinforcement learning, often constrained by intricately designed reward functions tailored to a narrow set of tasks. In this work, we present a novel approach for efficiently learning diverse bimanual dexterous skills from abundant human demonstrations. Specifically, we introduce BiDexHD, a framework that unifies task construction from existing bimanual datasets and employs teacher-student policy learning to address all tasks. The teacher learns state-based policies using a general two-stage reward function across tasks with shared behaviors, while the student distills the learned multi-task policies into a vision-based policy. With BiDexHD, scalable learning of numerous bimanual dexterous skills from auto-constructed tasks becomes feasible, offering promising advances toward universal bimanual dexterous manipulation. Our empirical evaluation on the TACO dataset, spanning 141 tasks across six categories, demonstrates a task fulfillment rate of 74.59% on trained tasks and 51.07% on unseen tasks, showcasing the effectiveness and competitive zero-shot generalization capabilities of BiDexHD. For videos and more information, visit our project page https://sites.google.com/view/bidexhd.
Creative Agents: Empowering Agents with Imagination for Creative Tasks
Dec 05, 2023



We study building embodied agents for open-ended creative tasks. While existing methods build instruction-following agents that can perform diverse open-ended tasks, none of them demonstrates creativity -- the ability to give novel and diverse task solutions implicit in the language instructions. This limitation comes from their inability to convert abstract language instructions into concrete task goals in the environment and perform long-horizon planning for such complicated goals. Given the observation that humans perform creative tasks with the help of imagination, we propose a class of solutions for creative agents, where the controller is enhanced with an imaginator that generates detailed imaginations of task outcomes conditioned on language instructions. We introduce several approaches to implementing the components of creative agents. We implement the imaginator with either a large language model for textual imagination or a diffusion model for visual imagination. The controller can either be a behavior-cloning policy learned from data or a pre-trained foundation model generating executable codes in the environment. We benchmark creative tasks with the challenging open-world game Minecraft, where the agents are asked to create diverse buildings given free-form language instructions. In addition, we propose novel evaluation metrics for open-ended creative tasks utilizing GPT-4V, which holds many advantages over existing metrics. We perform a detailed experimental analysis of creative agents, showing that creative agents are the first AI agents accomplishing diverse building creation in the survival mode of Minecraft. Our benchmark and models are open-source for future research on creative agents (https://github.com/PKU-RL/Creative-Agents).