 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConservative Offline Robot Policy Learning via Posterior-Transition Reweighting
Mar 17, 2026Offline post-training adapts a pretrained robot policy to a target dataset by supervised regression on recorded actions. In practice, robot datasets are heterogeneous: they mix embodiments, camera setups, and demonstrations of varying quality, so many trajectories reflect recovery behavior, inconsistent operator skill, or weakly informative supervision. Uniform post-training gives equal credit to all samples and can therefore average over conflicting or low-attribution data. We propose Posterior-Transition Reweighting (PTR), a reward-free and conservative post-training method that decides how much each training sample should influence the supervised update. For each sample, PTR encodes the observed post-action consequence as a latent target, inserts it into a candidate pool of mismatched targets, and uses a separate transition scorer to estimate a softmax identification posterior over target indices. The posterior-to-uniform ratio defines the PTR score, which is converted into a clipped-and-mixed weight and applied to the original action objective through self-normalized weighted regression. This construction requires no tractable policy likelihood and is compatible with both diffusion and flow-matching action heads. Rather than uniformly trusting all recorded supervision, PTR reallocates credit according to how attributable each sample's post-action consequence is under the current representation, improving conservative offline adaptation to heterogeneous robot data.
Joint-Aligned Latent Action: Towards Scalable VLA Pretraining in the Wild
Feb 25, 2026Despite progress, Vision-Language-Action models (VLAs) are limited by a scarcity of large-scale, diverse robot data. While human manipulation videos offer a rich alternative, existing methods are forced to choose between small, precisely-labeled datasets and vast in-the-wild footage with unreliable hand tracking labels. We present JALA, a pretraining framework that learns Jointly-Aligned Latent Actions. JALA bypasses full visual dynamic reconstruction, instead learns a predictive action embedding aligned with both inverse dynamics and real actions. This yields a transition-aware, behavior-centric latent space for learning from heterogeneous human data. We scale this approach with UniHand-Mix, a 7.5M video corpus (>2,000 hours) blending laboratory and in-the-wild footage. Experiments demonstrate that JALA generates more realistic hand motions in both controlled and unconstrained scenarios, significantly improving downstream robot manipulation performance in both simulation and real-world tasks. These results indicate that jointly-aligned latent actions offer a scalable pathway for VLA pretraining from human data.
Rethinking Visual-Language-Action Model Scaling: Alignment, Mixture, and Regularization
Feb 10, 2026While Vision-Language-Action (VLA) models show strong promise for generalist robot control, it remains unclear whether -- and under what conditions -- the standard "scale data" recipe translates to robotics, where training data is inherently heterogeneous across embodiments, sensors, and action spaces. We present a systematic, controlled study of VLA scaling that revisits core training choices for pretraining across diverse robots. Using a representative VLA framework that combines a vision-language backbone with flow-matching, we ablate key design decisions under matched conditions and evaluate in extensive simulation and real-robot experiments. To improve the reliability of real-world results, we introduce a Grouped Blind Ensemble protocol that blinds operators to model identity and separates policy execution from outcome judgment, reducing experimenter bias. Our analysis targets three dimensions of VLA scaling. (1) Physical alignment: we show that a unified end-effector (EEF)-relative action representation is critical for robust cross-embodiment transfer. (2) Embodiment mixture: we find that naively pooling heterogeneous robot datasets often induces negative transfer rather than gains, underscoring the fragility of indiscriminate data scaling. (3) Training regularization: we observe that intuitive strategies, such as sensory dropout and multi-stage fine-tuning, do not consistently improve performance at scale. Together, this study challenge some common assumptions about embodied scaling and provide practical guidance for training large-scale VLA policies from diverse robotic data. Project website: https://research.beingbeyond.com/rethink_vla
Being-H0.5: Scaling Human-Centric Robot Learning for Cross-Embodiment Generalization
Jan 19, 2026We introduce Being-H0.5, a foundational Vision-Language-Action (VLA) model designed for robust cross-embodiment generalization across diverse robotic platforms. While existing VLAs often struggle with morphological heterogeneity and data scarcity, we propose a human-centric learning paradigm that treats human interaction traces as a universal "mother tongue" for physical interaction. To support this, we present UniHand-2.0, the largest embodied pre-training recipe to date, comprising over 35,000 hours of multimodal data across 30 distinct robotic embodiments. Our approach introduces a Unified Action Space that maps heterogeneous robot controls into semantically aligned slots, enabling low-resource robots to bootstrap skills from human data and high-resource platforms. Built upon this human-centric foundation, we design a unified sequential modeling and multi-task pre-training paradigm to bridge human demonstrations and robotic execution. Architecturally, Being-H0.5 utilizes a Mixture-of-Transformers design featuring a novel Mixture-of-Flow (MoF) framework to decouple shared motor primitives from specialized embodiment-specific experts. Finally, to make cross-embodiment policies stable in the real world, we introduce Manifold-Preserving Gating for robustness under sensory shift and Universal Async Chunking to universalize chunked control across embodiments with different latency and control profiles. We empirically demonstrate that Being-H0.5 achieves state-of-the-art results on simulated benchmarks, such as LIBERO (98.9%) and RoboCasa (53.9%), while also exhibiting strong cross-embodiment capabilities on five robotic platforms.
UniTacHand: Unified Spatio-Tactile Representation for Human to Robotic Hand Skill Transfer
Dec 24, 2025Tactile sensing is crucial for robotic hands to achieve human-level dexterous manipulation, especially in scenarios with visual occlusion. However, its application is often hindered by the difficulty of collecting large-scale real-world robotic tactile data. In this study, we propose to collect low-cost human manipulation data using haptic gloves for tactile-based robotic policy learning. The misalignment between human and robotic tactile data makes it challenging to transfer policies learned from human data to robots. To bridge this gap, we propose UniTacHand, a unified representation to align robotic tactile information captured by dexterous hands with human hand touch obtained from gloves. First, we project tactile signals from both human hands and robotic hands onto a morphologically consistent 2D surface space of the MANO hand model. This unification standardizes the heterogeneous data structures and inherently embeds the tactile signals with spatial context. Then, we introduce a contrastive learning method to align them into a unified latent space, trained on only 10 minutes of paired data from our data collection system. Our approach enables zero-shot tactile-based policy transfer from humans to a real robot, generalizing to objects unseen in the pre-training data. We also demonstrate that co-training on mixed data, including both human and robotic demonstrations via UniTacHand, yields better performance and data efficiency compared with using only robotic data. UniTacHand paves a path toward general, scalable, and data-efficient learning for tactile-based dexterous hands.
Spatial-Aware VLA Pretraining through Visual-Physical Alignment from Human Videos
Dec 15, 2025Vision-Language-Action (VLA) models provide a promising paradigm for robot learning by integrating visual perception with language-guided policy learning. However, most existing approaches rely on 2D visual inputs to perform actions in 3D physical environments, creating a significant gap between perception and action grounding. To bridge this gap, we propose a Spatial-Aware VLA Pretraining paradigm that performs explicit alignment between visual space and physical space during pretraining, enabling models to acquire 3D spatial understanding before robot policy learning. Starting from pretrained vision-language models, we leverage large-scale human demonstration videos to extract 3D visual and 3D action annotations, forming a new source of supervision that aligns 2D visual observations with 3D spatial reasoning. We instantiate this paradigm with VIPA-VLA, a dual-encoder architecture that incorporates a 3D visual encoder to augment semantic visual representations with 3D-aware features. When adapted to downstream robot tasks, VIPA-VLA achieves significantly improved grounding between 2D vision and 3D action, resulting in more robust and generalizable robotic policies.
Universal Dexterous Functional Grasping via Demonstration-Editing Reinforcement Learning
Dec 15, 2025Reinforcement learning (RL) has achieved great success in dexterous grasping, significantly improving grasp performance and generalization from simulation to the real world. However, fine-grained functional grasping, which is essential for downstream manipulation tasks, remains underexplored and faces several challenges: the complexity of specifying goals and reward functions for functional grasps across diverse objects, the difficulty of multi-task RL exploration, and the challenge of sim-to-real transfer. In this work, we propose DemoFunGrasp for universal dexterous functional grasping. We factorize functional grasping conditions into two complementary components - grasping style and affordance - and integrate them into an RL framework that can learn to grasp any object with any functional grasping condition. To address the multi-task optimization challenge, we leverage a single grasping demonstration and reformulate the RL problem as one-step demonstration editing, substantially enhancing sample efficiency and performance. Experimental results in both simulation and the real world show that DemoFunGrasp generalizes to unseen combinations of objects, affordances, and grasping styles, outperforming baselines in both success rate and functional grasping accuracy. In addition to strong sim-to-real capability, by incorporating a vision-language model (VLM) for planning, our system achieves autonomous instruction-following grasp execution.
Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Oct 09, 2025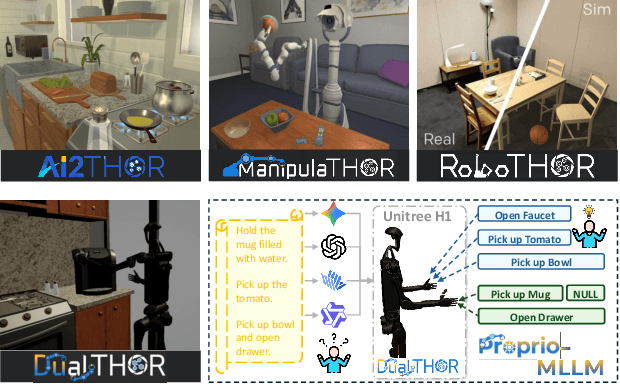


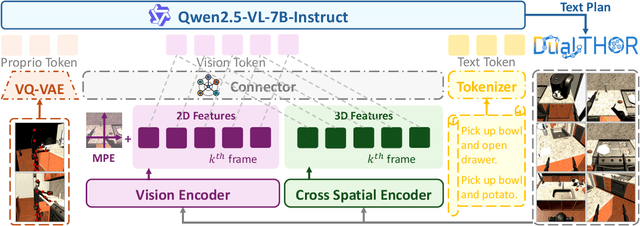
In recent years, Multimodal Large Language Models (MLLMs) have demonstrated the ability to serve as high-level planners, enabling robots to follow complex human instructions. However, their effectiveness, especially in long-horizon tasks involving dual-arm humanoid robots, remains limited. This limitation arises from two main challenges: (i) the absence of simulation platforms that systematically support task evaluation and data collection for humanoid robots, and (ii) the insufficient embodiment awareness of current MLLMs, which hinders reasoning about dual-arm selection logic and body positions during planning. To address these issues, we present DualTHOR, a new dual-arm humanoid simulator, with continuous transition and a contingency mechanism. Building on this platform, we propose Proprio-MLLM, a model that enhances embodiment awareness by incorporating proprioceptive information with motion-based position embedding and a cross-spatial encoder. Experiments show that, while existing MLLMs struggle in this environment, Proprio-MLLM achieves an average improvement of 19.75% in planning performance. Our work provides both an essential simulation platform and an effective model to advance embodied intelligence in humanoid robotics. The code is available at https://anonymous.4open.science/r/DualTHOR-5F3B.
DemoGrasp: Universal Dexterous Grasping from a Single Demonstration
Sep 26, 2025Universal grasping with multi-fingered dexterous hands is a fundamental challenge in robotic manipulation. While recent approaches successfully learn closed-loop grasping policies using reinforcement learning (RL), the inherent difficulty of high-dimensional, long-horizon exploration necessitates complex reward and curriculum design, often resulting in suboptimal solutions across diverse objects. We propose DemoGrasp, a simple yet effective method for learning universal dexterous grasping. We start from a single successful demonstration trajectory of grasping a specific object and adapt to novel objects and poses by editing the robot actions in this trajectory: changing the wrist pose determines where to grasp, and changing the hand joint angles determines how to grasp. We formulate this trajectory editing as a single-step Markov Decision Process (MDP) and use RL to optimize a universal policy across hundreds of objects in parallel in simulation, with a simple reward consisting of a binary success term and a robot-table collision penalty. In simulation, DemoGrasp achieves a 95% success rate on DexGraspNet objects using the Shadow Hand, outperforming previous state-of-the-art methods. It also shows strong transferability, achieving an average success rate of 84.6% across diverse dexterous hand embodiments on six unseen object datasets, while being trained on only 175 objects. Through vision-based imitation learning, our policy successfully grasps 110 unseen real-world objects, including small, thin items. It generalizes to spatial, background, and lighting changes, supports both RGB and depth inputs, and extends to language-guided grasping in cluttered scenes.
Being-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills
Mar 16, 2025Building autonomous robotic agents capable of achieving human-level performance in real-world embodied tasks is an ultimate goal in humanoid robot research. Recent advances have made significant progress in high-level cognition with Foundation Models (FMs) and low-level skill development for humanoid robots. However, directly combining these components often results in poor robustness and efficiency due to compounding errors in long-horizon tasks and the varied latency of different modules. We introduce Being-0, a hierarchical agent framework that integrates an FM with a modular skill library. The FM handles high-level cognitive tasks such as instruction understanding, task planning, and reasoning, while the skill library provides stable locomotion and dexterous manipulation for low-level control. To bridge the gap between these levels, we propose a novel Connector module, powered by a lightweight vision-language model (VLM). The Connector enhances the FM's embodied capabilities by translating language-based plans into actionable skill commands and dynamically coordinating locomotion and manipulation to improve task success. With all components, except the FM, deployable on low-cost onboard computation devices, Being-0 achieves efficient, real-time performance on a full-sized humanoid robot equipped with dexterous hands and active vision. Extensive experiments in large indoor environments demonstrate Being-0's effectiveness in solving complex, long-horizon tasks that require challenging navigation and manipulation subtasks. For further details and videos, visit https://beingbeyond.github.io/being-0.