 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiPath: Hierarchical Vision-Language Alignment for Structured Pathology Report Prediction
Mar 20, 2026Pathology reports are structured, multi-granular documents encoding diagnostic conclusions, histological grades, and ancillary test results across one or more anatomical sites; yet existing pathology vision-language models (VLMs) reduce this output to a flat label or free-form text. We present HiPath, a lightweight VLM framework built on frozen UNI2 and Qwen3 backbones that treats structured report prediction as its primary training objective. Three trainable modules totalling 15M parameters address complementary aspects of the problem: a Hierarchical Patch Aggregator (HiPA) for multi-image visual encoding, Hierarchical Contrastive Learning (HiCL) for cross-modal alignment via optimal transport, and Slot-based Masked Diagnosis Prediction (Slot-MDP) for structured diagnosis generation. Trained on 749K real-world Chinese pathology cases from three hospitals, HiPath achieves 68.9% strict and 74.7% clinically acceptable accuracy with a 97.3% safety rate, outperforming all baselines under the same frozen backbone. Cross-hospital evaluation confirms generalisation with only a 3.4pp drop in strict accuracy while maintaining 97.1% safety.
Towards Trustworthy Selective Generation: Reliability-Guided Diffusion for Ultra-Low-Field to High-Field MRI Synthesis
Mar 11, 2026Low-field to high-field MRI synthesis has emerged as a cost-effective strategy to enhance image quality under hardware and acquisition constraints, particularly in scenarios where access to high-field scanners is limited or impractical. Despite recent progress in diffusion models, diffusion-based approaches often struggle to balance fine-detail recovery and structural fidelity. In particular, the uncontrolled generation of high-resolution details in structurally ambiguous regions may introduce anatomically inconsistent patterns, such as spurious edges or artificial texture variations. These artifacts can bias downstream quantitative analysis. For example, they may cause inaccurate tissue boundary delineation or erroneous volumetric estimation, ultimately reducing clinical trust in synthesized images. These limitations highlight the need for generative models that are not only visually accurate but also spatially reliable and anatomically consistent. To address this issue, we propose a reliability-aware diffusion framework (ReDiff) that improves synthesis robustness at both the sampling and post-generation stages. Specifically, we introduce a reliability-guided sampling strategy to suppress unreliable responses during the denoising process. We further develop an uncertainty-aware multi-candidate selection scheme to enhance the reliability of the final prediction. Experiments on multi-center MRI datasets demonstrate improved structural fidelity and reduced artifacts compared with state-of-the-art methods.
Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Oct 09, 2025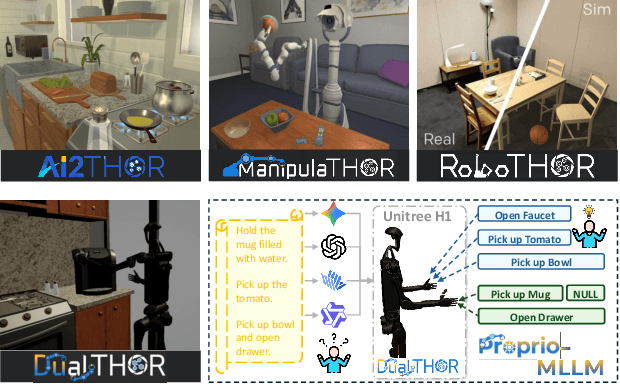


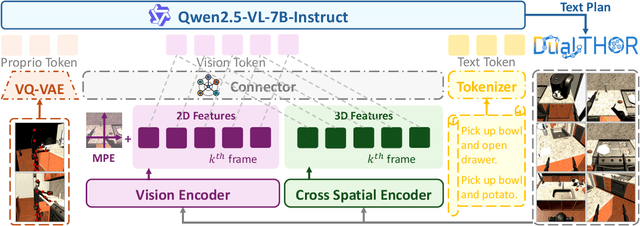
In recent years, Multimodal Large Language Models (MLLMs) have demonstrated the ability to serve as high-level planners, enabling robots to follow complex human instructions. However, their effectiveness, especially in long-horizon tasks involving dual-arm humanoid robots, remains limited. This limitation arises from two main challenges: (i) the absence of simulation platforms that systematically support task evaluation and data collection for humanoid robots, and (ii) the insufficient embodiment awareness of current MLLMs, which hinders reasoning about dual-arm selection logic and body positions during planning. To address these issues, we present DualTHOR, a new dual-arm humanoid simulator, with continuous transition and a contingency mechanism. Building on this platform, we propose Proprio-MLLM, a model that enhances embodiment awareness by incorporating proprioceptive information with motion-based position embedding and a cross-spatial encoder. Experiments show that, while existing MLLMs struggle in this environment, Proprio-MLLM achieves an average improvement of 19.75% in planning performance. Our work provides both an essential simulation platform and an effective model to advance embodied intelligence in humanoid robotics. The code is available at https://anonymous.4open.science/r/DualTHOR-5F3B.
A Manifold-based Airfoil Geometric-feature Extraction and Discrepant Data Fusion Learning Method
Jun 23, 2022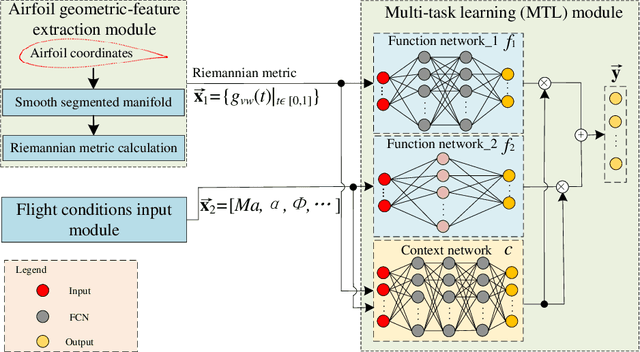
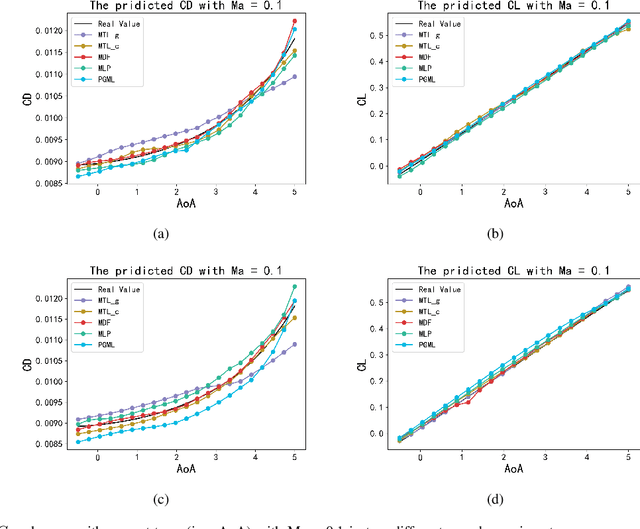
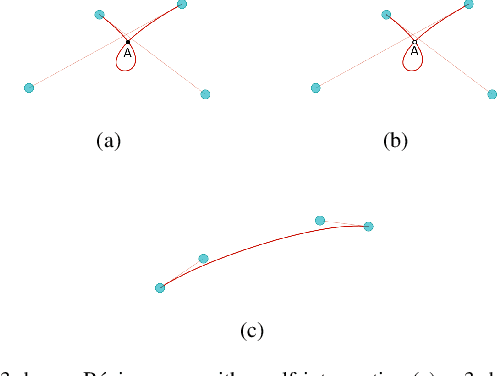
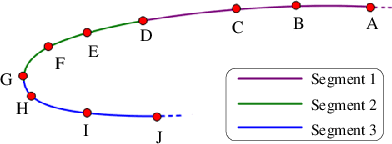
Geometrical shape of airfoils, together with the corresponding flight conditions, are crucial factors for aerodynamic performances prediction. The obtained airfoils geometrical features in most existing approaches (e.g., geometrical parameters extraction, polynomial description and deep learning) are in Euclidean space. State-of-the-art studies showed that curves or surfaces of an airfoil formed a manifold in Riemannian space. Therefore, the features extracted by existing methods are not sufficient to reflect the geometric-features of airfoils. Meanwhile, flight conditions and geometric features are greatly discrepant with different types, the relevant knowledge of the influence of these two factors that on final aerodynamic performances predictions must be evaluated and learned to improve prediction accuracy. Motivated by the advantages of manifold theory and multi-task learning, we propose a manifold-based airfoil geometric-feature extraction and discrepant data fusion learning method (MDF) to extract geometric-features of airfoils in Riemannian space (we call them manifold-features) and further fuse the manifold-features with flight conditions to predict aerodynamic performances. Experimental results show that our method could extract geometric-features of airfoils more accurately compared with existing methods, that the average MSE of re-built airfoils is reduced by 56.33%, and while keeping the same predicted accuracy level of CL, the MSE of CD predicted by MDF is further reduced by 35.37%.
Aerodynamic Data Predictions Based on Multi-task Learning
Oct 15, 2020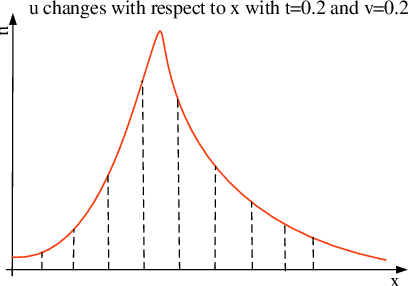
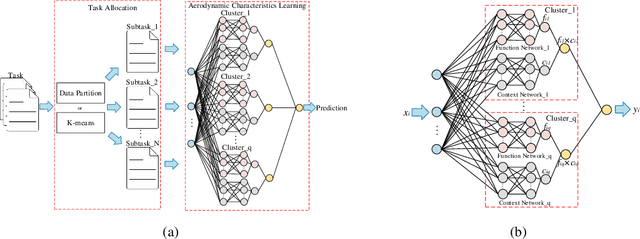

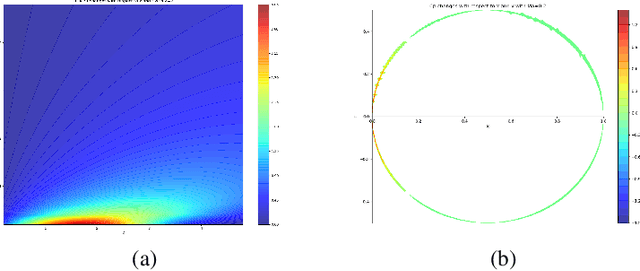
The quality of datasets is one of the key factors that affect the accuracy of aerodynamic data models. For example, in the uniformly sampled Burgers' dataset, the insufficient high-speed data is overwhelmed by massive low-speed data. Predicting high-speed data is more difficult than predicting low-speed data, owing to that the number of high-speed data is limited, i.e. the quality of the Burgers' dataset is not satisfactory. To improve the quality of datasets, traditional methods usually employ the data resampling technology to produce enough data for the insufficient parts in the original datasets before modeling, which increases computational costs. Recently, the mixtures of experts have been used in natural language processing to deal with different parts of sentences, which provides a solution for eliminating the need for data resampling in aerodynamic data modeling. Motivated by this, we propose the multi-task learning (MTL), a datasets quality-adaptive learning scheme, which combines task allocation and aerodynamic characteristics learning together to disperse the pressure of the entire learning task. The task allocation divides a whole learning task into several independent subtasks, while the aerodynamic characteristics learning learns these subtasks simultaneously to achieve better precision. Two experiments with poor quality datasets are conducted to verify the data quality-adaptivity of the MTL to datasets. The results show than the MTL is more accurate than FCNs and GANs in poor quality datasets.
Flow Field Reconstructions with GANs based on Radial Basis Functions
Aug 11, 2020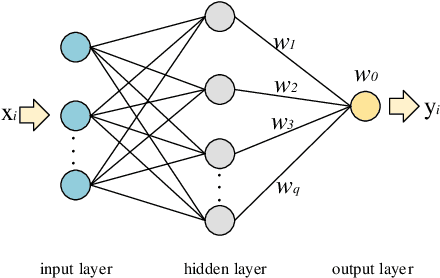
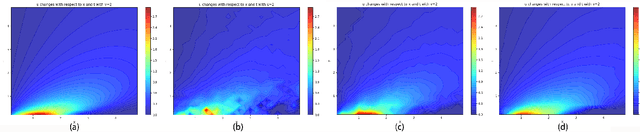
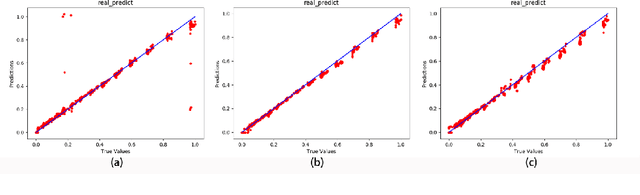
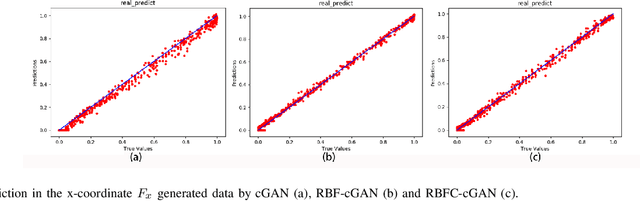
Nonlinear sparse data regression and generation have been a long-term challenge, to cite the flow field reconstruction as a typical example. The huge computational cost of computational fluid dynamics (CFD) makes it much expensive for large scale CFD data producing, which is the reason why we need some cheaper ways to do this, of which the traditional reduced order models (ROMs) were promising but they couldn't generate a large number of full domain flow field data (FFD) to realize high-precision flow field reconstructions. Motivated by the problems of existing approaches and inspired by the success of the generative adversarial networks (GANs) in the field of computer vision, we prove an optimal discriminator theorem that the optimal discriminator of a GAN is a radial basis function neural network (RBFNN) while dealing with nonlinear sparse FFD regression and generation. Based on this theorem, two radial basis function-based GANs (RBF-GAN and RBFC-GAN), for regression and generation purposes, are proposed. Three different datasets are applied to verify the feasibility of our models. The results show that the performance of the RBF-GAN and the RBFC-GAN are better than that of GANs/cGANs by means of both the mean square error (MSE) and the mean square percentage error (MSPE). Besides, compared with GANs/cGANs, the stability of the RBF-GAN and the RBFC-GAN improve by 34.62% and 72.31%, respectively. Consequently, our proposed models can be used to generate full domain FFD from limited and sparse datasets, to meet the requirement of high-precision flow field reconstructions.