 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Oct 09, 2025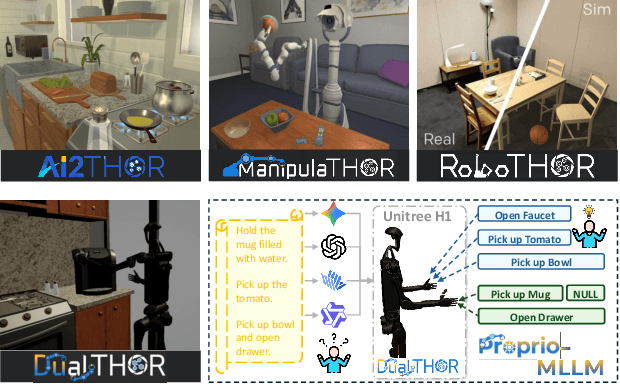


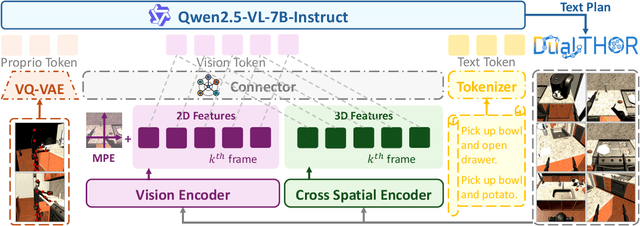
In recent years, Multimodal Large Language Models (MLLMs) have demonstrated the ability to serve as high-level planners, enabling robots to follow complex human instructions. However, their effectiveness, especially in long-horizon tasks involving dual-arm humanoid robots, remains limited. This limitation arises from two main challenges: (i) the absence of simulation platforms that systematically support task evaluation and data collection for humanoid robots, and (ii) the insufficient embodiment awareness of current MLLMs, which hinders reasoning about dual-arm selection logic and body positions during planning. To address these issues, we present DualTHOR, a new dual-arm humanoid simulator, with continuous transition and a contingency mechanism. Building on this platform, we propose Proprio-MLLM, a model that enhances embodiment awareness by incorporating proprioceptive information with motion-based position embedding and a cross-spatial encoder. Experiments show that, while existing MLLMs struggle in this environment, Proprio-MLLM achieves an average improvement of 19.75% in planning performance. Our work provides both an essential simulation platform and an effective model to advance embodied intelligence in humanoid robotics. The code is available at https://anonymous.4open.science/r/DualTHOR-5F3B.
Unified Mind Model: Reimagining Autonomous Agents in the LLM Era
Mar 06, 2025



Large language models (LLMs) have recently demonstrated remarkable capabilities across domains, tasks, and languages (e.g., ChatGPT and GPT-4), reviving the research of general autonomous agents with human-like cognitive abilities. Such human-level agents require semantic comprehension and instruction-following capabilities, which exactly fall into the strengths of LLMs. Although there have been several initial attempts to build human-level agents based on LLMs, the theoretical foundation remains a challenging open problem. In this paper, we propose a novel theoretical cognitive architecture, the Unified Mind Model (UMM), which offers guidance to facilitate the rapid creation of autonomous agents with human-level cognitive abilities. Specifically, our UMM starts with the global workspace theory and further leverage LLMs to enable the agent with various cognitive abilities, such as multi-modal perception, planning, reasoning, tool use, learning, memory, reflection and motivation. Building upon UMM, we then develop an agent-building engine, MindOS, which allows users to quickly create domain-/task-specific autonomous agents without any programming effort.
Tree-of-Mixed-Thought: Combining Fast and Slow Thinking for Multi-hop Visual Reasoning
Aug 21, 2023



There emerges a promising trend of using large language models (LLMs) to generate code-like plans for complex inference tasks such as visual reasoning. This paradigm, known as LLM-based planning, provides flexibility in problem solving and endows better interpretability. However, current research is mostly limited to basic scenarios of simple questions that can be straightforward answered in a few inference steps. Planning for the more challenging multi-hop visual reasoning tasks remains under-explored. Specifically, under multi-hop reasoning situations, the trade-off between accuracy and the complexity of plan-searching becomes prominent. The prevailing algorithms either address the efficiency issue by employing the fast one-stop generation or adopt a complex iterative generation method to improve accuracy. Both fail to balance the need for efficiency and performance. Drawing inspiration from the dual system of cognition in the human brain, the fast and the slow think processes, we propose a hierarchical plan-searching algorithm that integrates the one-stop reasoning (fast) and the Tree-of-thought (slow). Our approach succeeds in performance while significantly saving inference steps. Moreover, we repurpose the PTR and the CLEVER datasets, developing a systematic framework for evaluating the performance and efficiency of LLMs-based plan-search algorithms under reasoning tasks at different levels of difficulty. Extensive experiments demonstrate the superiority of our proposed algorithm in terms of performance and efficiency. The dataset and code will be release soon.
Boosting Multi-modal Model Performance with Adaptive Gradient Modulation
Aug 15, 2023



While the field of multi-modal learning keeps growing fast, the deficiency of the standard joint training paradigm has become clear through recent studies. They attribute the sub-optimal performance of the jointly trained model to the modality competition phenomenon. Existing works attempt to improve the jointly trained model by modulating the training process. Despite their effectiveness, those methods can only apply to late fusion models. More importantly, the mechanism of the modality competition remains unexplored. In this paper, we first propose an adaptive gradient modulation method that can boost the performance of multi-modal models with various fusion strategies. Extensive experiments show that our method surpasses all existing modulation methods. Furthermore, to have a quantitative understanding of the modality competition and the mechanism behind the effectiveness of our modulation method, we introduce a novel metric to measure the competition strength. This metric is built on the mono-modal concept, a function that is designed to represent the competition-less state of a modality. Through systematic investigation, our results confirm the intuition that the modulation encourages the model to rely on the more informative modality. In addition, we find that the jointly trained model typically has a preferred modality on which the competition is weaker than other modalities. However, this preferred modality need not dominate others. Our code will be available at https://github.com/lihong2303/AGM_ICCV2023.
SHAPE: An Unified Approach to Evaluate the Contribution and Cooperation of Individual Modalities
Apr 30, 2022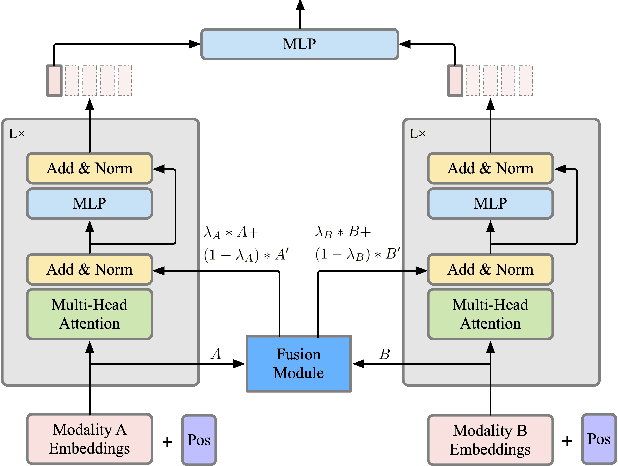


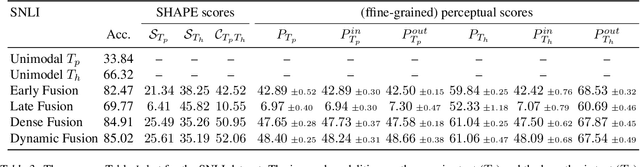
As deep learning advances, there is an ever-growing demand for models capable of synthesizing information from multi-modal resources to address the complex tasks raised from real-life applications. Recently, many large multi-modal datasets have been collected, on which researchers actively explore different methods of fusing multi-modal information. However, little attention has been paid to quantifying the contribution of different modalities within the proposed models. In this paper, we propose the {\bf SH}apley v{\bf A}lue-based {\bf PE}rceptual (SHAPE) scores that measure the marginal contribution of individual modalities and the degree of cooperation across modalities. Using these scores, we systematically evaluate different fusion methods on different multi-modal datasets for different tasks. Our experiments suggest that for some tasks where different modalities are complementary, the multi-modal models still tend to use the dominant modality alone and ignore the cooperation across modalities. On the other hand, models learn to exploit cross-modal cooperation when different modalities are indispensable for the task. In this case, the scores indicate it is better to fuse different modalities at relatively early stages. We hope our scores can help improve the understanding of how the present multi-modal models operate on different modalities and encourage more sophisticated methods of integrating multiple modalities.