 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Towards Proprioception-Aware Embodied Planning for Dual-Arm Humanoid Robots
Oct 09, 2025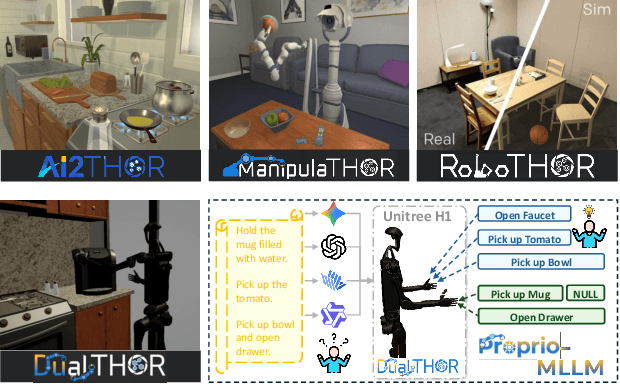


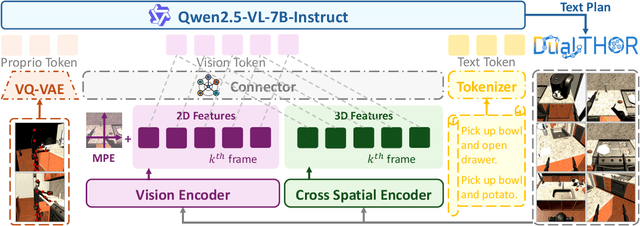
In recent years, Multimodal Large Language Models (MLLMs) have demonstrated the ability to serve as high-level planners, enabling robots to follow complex human instructions. However, their effectiveness, especially in long-horizon tasks involving dual-arm humanoid robots, remains limited. This limitation arises from two main challenges: (i) the absence of simulation platforms that systematically support task evaluation and data collection for humanoid robots, and (ii) the insufficient embodiment awareness of current MLLMs, which hinders reasoning about dual-arm selection logic and body positions during planning. To address these issues, we present DualTHOR, a new dual-arm humanoid simulator, with continuous transition and a contingency mechanism. Building on this platform, we propose Proprio-MLLM, a model that enhances embodiment awareness by incorporating proprioceptive information with motion-based position embedding and a cross-spatial encoder. Experiments show that, while existing MLLMs struggle in this environment, Proprio-MLLM achieves an average improvement of 19.75% in planning performance. Our work provides both an essential simulation platform and an effective model to advance embodied intelligence in humanoid robotics. The code is available at https://anonymous.4open.science/r/DualTHOR-5F3B.
L2RSI: Cross-view LiDAR-based Place Recognition for Large-scale Urban Scenes via Remote Sensing Imagery
Mar 14, 2025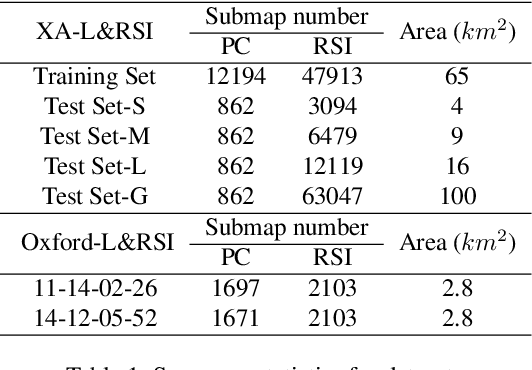
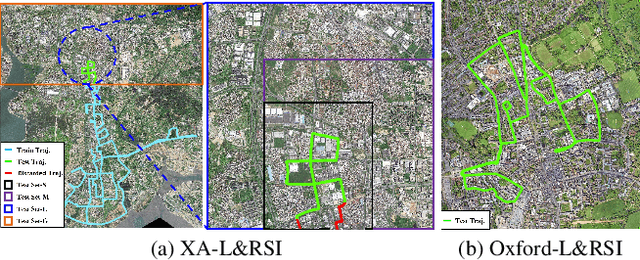
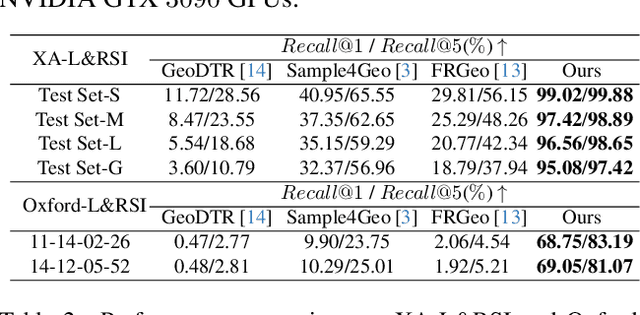
We tackle the challenge of LiDAR-based place recognition, which traditionally depends on costly and time-consuming prior 3D maps. To overcome this, we first construct XA-L&RSI dataset, which encompasses approximately $110,000$ remote sensing submaps and $13,000$ LiDAR point cloud submaps captured in urban scenes, and propose a novel method, L2RSI, for cross-view LiDAR place recognition using high-resolution Remote Sensing Imagery. This approach enables large-scale localization capabilities at a reduced cost by leveraging readily available overhead images as map proxies. L2RSI addresses the dual challenges of cross-view and cross-modal place recognition by learning feature alignment between point cloud submaps and remote sensing submaps in the semantic domain. Additionally, we introduce a novel probability propagation method based on a dynamic Gaussian mixture model to refine position predictions, effectively leveraging temporal and spatial information. This approach enables large-scale retrieval and cross-scene generalization without fine-tuning. Extensive experiments on XA-L&RSI demonstrate that, within a $100km^2$ retrieval range, L2RSI accurately localizes $95.08\%$ of point cloud submaps within a $30m$ radius for top-$1$ retrieved location. We provide a video to more vividly display the place recognition results of L2RSI at https://shizw695.github.io/L2RSI/.
A New Adversarial Perspective for LiDAR-based 3D Object Detection
Dec 17, 2024



Autonomous vehicles (AVs) rely on LiDAR sensors for environmental perception and decision-making in driving scenarios. However, ensuring the safety and reliability of AVs in complex environments remains a pressing challenge. To address this issue, we introduce a real-world dataset (ROLiD) comprising LiDAR-scanned point clouds of two random objects: water mist and smoke. In this paper, we introduce a novel adversarial perspective by proposing an attack framework that utilizes water mist and smoke to simulate environmental interference. Specifically, we propose a point cloud sequence generation method using a motion and content decomposition generative adversarial network named PCS-GAN to simulate the distribution of random objects. Furthermore, leveraging the simulated LiDAR scanning characteristics implemented with Range Image, we examine the effects of introducing random object perturbations at various positions on the target vehicle. Extensive experiments demonstrate that adversarial perturbations based on random objects effectively deceive vehicle detection and reduce the recognition rate of 3D object detection models.
E2PNet: Event to Point Cloud Registration with Spatio-Temporal Representation Learning
Nov 30, 2023Event cameras have emerged as a promising vision sensor in recent years due to their unparalleled temporal resolution and dynamic range. While registration of 2D RGB images to 3D point clouds is a long-standing problem in computer vision, no prior work studies 2D-3D registration for event cameras. To this end, we propose E2PNet, the first learning-based method for event-to-point cloud registration. The core of E2PNet is a novel feature representation network called Event-Points-to-Tensor (EP2T), which encodes event data into a 2D grid-shaped feature tensor. This grid-shaped feature enables matured RGB-based frameworks to be easily used for event-to-point cloud registration, without changing hyper-parameters and the training procedure. EP2T treats the event input as spatio-temporal point clouds. Unlike standard 3D learning architectures that treat all dimensions of point clouds equally, the novel sampling and information aggregation modules in EP2T are designed to handle the inhomogeneity of the spatial and temporal dimensions. Experiments on the MVSEC and VECtor datasets demonstrate the superiority of E2PNet over hand-crafted and other learning-based methods. Compared to RGB-based registration, E2PNet is more robust to extreme illumination or fast motion due to the use of event data. Beyond 2D-3D registration, we also show the potential of EP2T for other vision tasks such as flow estimation, event-to-image reconstruction and object recognition. The source code can be found at: https://github.com/Xmu-qcj/E2PNet.
Decoupled Local Aggregation for Point Cloud Learning
Aug 31, 2023



The unstructured nature of point clouds demands that local aggregation be adaptive to different local structures. Previous methods meet this by explicitly embedding spatial relations into each aggregation process. Although this coupled approach has been shown effective in generating clear semantics, aggregation can be greatly slowed down due to repeated relation learning and redundant computation to mix directional and point features. In this work, we propose to decouple the explicit modelling of spatial relations from local aggregation. We theoretically prove that basic neighbor pooling operations can too function without loss of clarity in feature fusion, so long as essential spatial information has been encoded in point features. As an instantiation of decoupled local aggregation, we present DeLA, a lightweight point network, where in each learning stage relative spatial encodings are first formed, and only pointwise convolutions plus edge max-pooling are used for local aggregation then. Further, a regularization term is employed to reduce potential ambiguity through the prediction of relative coordinates. Conceptually simple though, experimental results on five classic benchmarks demonstrate that DeLA achieves state-of-the-art performance with reduced or comparable latency. Specifically, DeLA achieves over 90\% overall accuracy on ScanObjectNN and 74\% mIoU on S3DIS Area 5. Our code is available at https://github.com/Matrix-ASC/DeLA .
DSMNet: Deep High-precision 3D Surface Modeling from Sparse Point Cloud Frames
Apr 09, 2023



Existing point cloud modeling datasets primarily express the modeling precision by pose or trajectory precision rather than the point cloud modeling effect itself. Under this demand, we first independently construct a set of LiDAR system with an optical stage, and then we build a HPMB dataset based on the constructed LiDAR system, a High-Precision, Multi-Beam, real-world dataset. Second, we propose an modeling evaluation method based on HPMB for object-level modeling to overcome this limitation. In addition, the existing point cloud modeling methods tend to generate continuous skeletons of the global environment, hence lacking attention to the shape of complex objects. To tackle this challenge, we propose a novel learning-based joint framework, DSMNet, for high-precision 3D surface modeling from sparse point cloud frames. DSMNet comprises density-aware Point Cloud Registration (PCR) and geometry-aware Point Cloud Sampling (PCS) to effectively learn the implicit structure feature of sparse point clouds. Extensive experiments demonstrate that DSMNet outperforms the state-of-the-art methods in PCS and PCR on Multi-View Partial Point Cloud (MVP) database. Furthermore, the experiments on the open source KITTI and our proposed HPMB datasets show that DSMNet can be generalized as a post-processing of Simultaneous Localization And Mapping (SLAM), thereby improving modeling precision in environments with sparse point clouds.
ConTIG: Continuous Representation Learning on Temporal Interaction Graphs
Sep 27, 2021
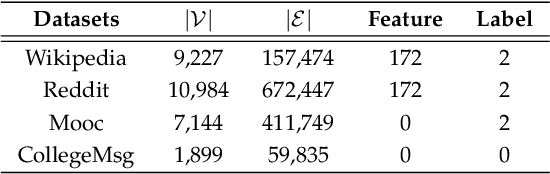
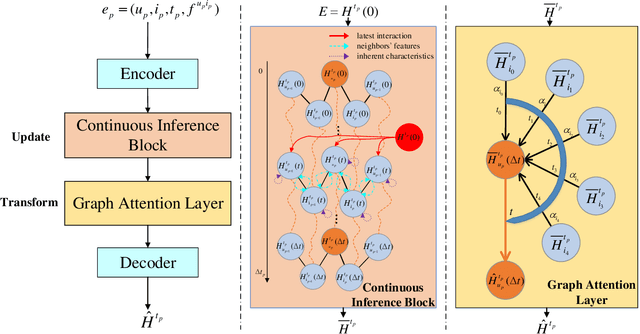
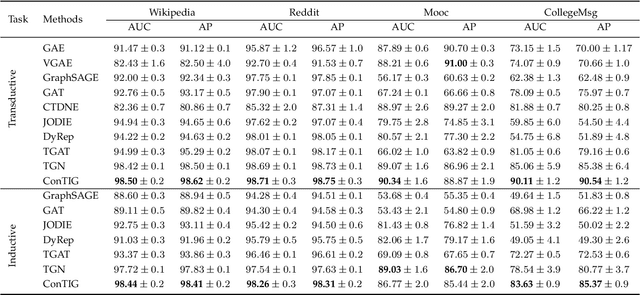
Representation learning on temporal interaction graphs (TIG) is to model complex networks with the dynamic evolution of interactions arising in a broad spectrum of problems. Existing dynamic embedding methods on TIG discretely update node embeddings merely when an interaction occurs. They fail to capture the continuous dynamic evolution of embedding trajectories of nodes. In this paper, we propose a two-module framework named ConTIG, a continuous representation method that captures the continuous dynamic evolution of node embedding trajectories. With two essential modules, our model exploit three-fold factors in dynamic networks which include latest interaction, neighbor features and inherent characteristics. In the first update module, we employ a continuous inference block to learn the nodes' state trajectories by learning from time-adjacent interaction patterns between node pairs using ordinary differential equations. In the second transform module, we introduce a self-attention mechanism to predict future node embeddings by aggregating historical temporal interaction information. Experiments results demonstrate the superiority of ConTIG on temporal link prediction, temporal node recommendation and dynamic node classification tasks compared with a range of state-of-the-art baselines, especially for long-interval interactions prediction.