 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Domain Shift Eraser
Mar 17, 2025Federated learning (FL) is emerging as a promising technique for collaborative learning without local data leaving their devices. However, clients' data originating from diverse domains may degrade model performance due to domain shifts, preventing the model from learning consistent representation space. In this paper, we propose a novel FL framework, Federated Domain Shift Eraser (FDSE), to improve model performance by differently erasing each client's domain skew and enhancing their consensus. First, we formulate the model forward passing as an iterative deskewing process that extracts and then deskews features alternatively. This is efficiently achieved by decomposing each original layer in the neural network into a Domain-agnostic Feature Extractor (DFE) and a Domain-specific Skew Eraser (DSE). Then, a regularization term is applied to promise the effectiveness of feature deskewing by pulling local statistics of DSE's outputs close to the globally consistent ones. Finally, DFE modules are fairly aggregated and broadcast to all the clients to maximize their consensus, and DSE modules are personalized for each client via similarity-aware aggregation to erase their domain skew differently. Comprehensive experiments were conducted on three datasets to confirm the advantages of our method in terms of accuracy, efficiency, and generalizability.
ConDo: Continual Domain Expansion for Absolute Pose Regression
Dec 18, 2024



Visual localization is a fundamental machine learning problem. Absolute Pose Regression (APR) trains a scene-dependent model to efficiently map an input image to the camera pose in a pre-defined scene. However, many applications have continually changing environments, where inference data at novel poses or scene conditions (weather, geometry) appear after deployment. Training APR on a fixed dataset leads to overfitting, making it fail catastrophically on challenging novel data. This work proposes Continual Domain Expansion (ConDo), which continually collects unlabeled inference data to update the deployed APR. Instead of applying standard unsupervised domain adaptation methods which are ineffective for APR, ConDo effectively learns from unlabeled data by distilling knowledge from scene-agnostic localization methods. By sampling data uniformly from historical and newly collected data, ConDo can effectively expand the generalization domain of APR. Large-scale benchmarks with various scene types are constructed to evaluate models under practical (long-term) data changes. ConDo consistently and significantly outperforms baselines across architectures, scene types, and data changes. On challenging scenes (Fig.1), it reduces the localization error by >7x (14.8m vs 1.7m). Analysis shows the robustness of ConDo against compute budgets, replay buffer sizes and teacher prediction noise. Comparing to model re-training, ConDo achieves similar performance up to 25x faster.
P4GCN: Vertical Federated Social Recommendation with Privacy-Preserving Two-Party Graph Convolution Networks
Oct 16, 2024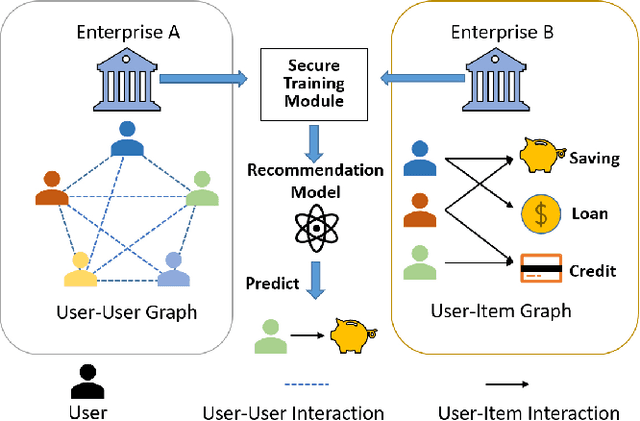
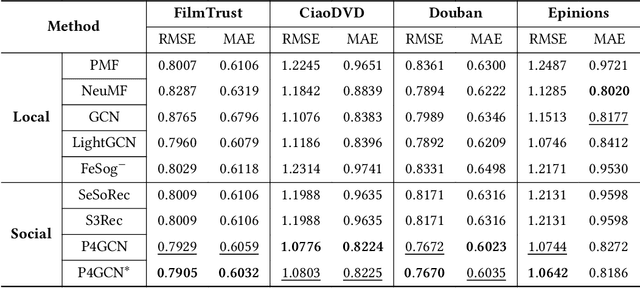

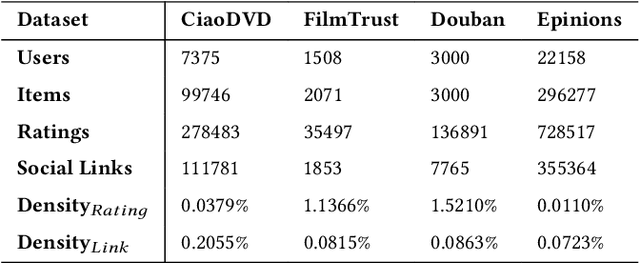
In recent years, graph neural networks (GNNs) have been commonly utilized for social recommendation systems. However, real-world scenarios often present challenges related to user privacy and business constraints, inhibiting direct access to valuable social information from other platforms. While many existing methods have tackled matrix factorization-based social recommendations without direct social data access, developing GNN-based federated social recommendation models under similar conditions remains largely unexplored. To address this issue, we propose a novel vertical federated social recommendation method leveraging privacy-preserving two-party graph convolution networks (P4GCN) to enhance recommendation accuracy without requiring direct access to sensitive social information. First, we introduce a Sandwich-Encryption module to ensure comprehensive data privacy during the collaborative computing process. Second, we provide a thorough theoretical analysis of the privacy guarantees, considering the participation of both curious and honest parties. Extensive experiments on four real-world datasets demonstrate that P4GCN outperforms state-of-the-art methods in terms of recommendation accuracy. The code is available at https://github.com/WwZzz/P4GCN.
Federated Graph Learning for Cross-Domain Recommendation
Oct 10, 2024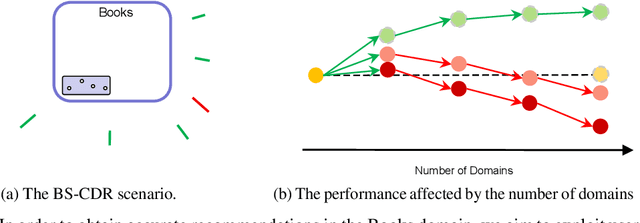
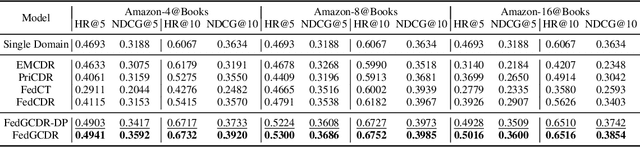
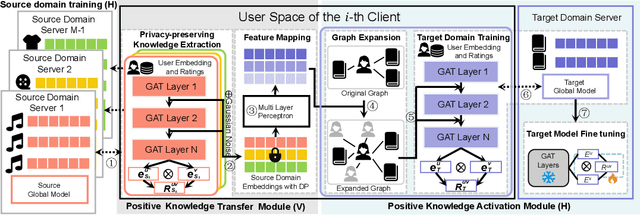
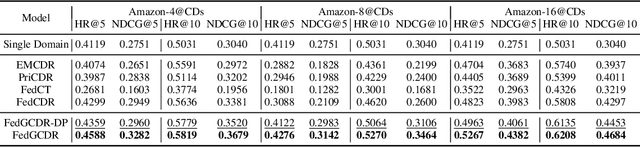
Cross-domain recommendation (CDR) offers a promising solution to the data sparsity problem by enabling knowledge transfer across source and target domains. However, many recent CDR models overlook crucial issues such as privacy as well as the risk of negative transfer (which negatively impact model performance), especially in multi-domain settings. To address these challenges, we propose FedGCDR, a novel federated graph learning framework that securely and effectively leverages positive knowledge from multiple source domains. First, we design a positive knowledge transfer module that ensures privacy during inter-domain knowledge transmission. This module employs differential privacy-based knowledge extraction combined with a feature mapping mechanism, transforming source domain embeddings from federated graph attention networks into reliable domain knowledge. Second, we design a knowledge activation module to filter out potential harmful or conflicting knowledge from source domains, addressing the issues of negative transfer. This module enhances target domain training by expanding the graph of the target domain to generate reliable domain attentions and fine-tunes the target model for improved negative knowledge filtering and more accurate predictions. We conduct extensive experiments on 16 popular domains of the Amazon dataset, demonstrating that FedGCDR significantly outperforms state-of-the-art methods.
FedSAC: Dynamic Submodel Allocation for Collaborative Fairness in Federated Learning
May 28, 2024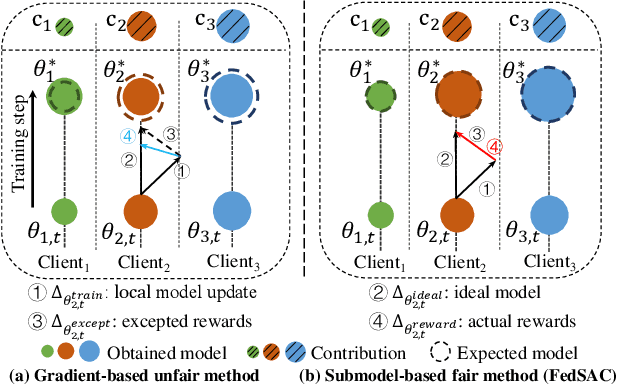



Collaborative fairness stands as an essential element in federated learning to encourage client participation by equitably distributing rewards based on individual contributions. Existing methods primarily focus on adjusting gradient allocations among clients to achieve collaborative fairness. However, they frequently overlook crucial factors such as maintaining consistency across local models and catering to the diverse requirements of high-contributing clients. This oversight inevitably decreases both fairness and model accuracy in practice. To address these issues, we propose FedSAC, a novel Federated learning framework with dynamic Submodel Allocation for Collaborative fairness, backed by a theoretical convergence guarantee. First, we present the concept of "bounded collaborative fairness (BCF)", which ensures fairness by tailoring rewards to individual clients based on their contributions. Second, to implement the BCF, we design a submodel allocation module with a theoretical guarantee of fairness. This module incentivizes high-contributing clients with high-performance submodels containing a diverse range of crucial neurons, thereby preserving consistency across local models. Third, we further develop a dynamic aggregation module to adaptively aggregate submodels, ensuring the equitable treatment of low-frequency neurons and consequently enhancing overall model accuracy. Extensive experiments conducted on three public benchmarks demonstrate that FedSAC outperforms all baseline methods in both fairness and model accuracy. We see this work as a significant step towards incentivizing broader client participation in federated learning. The source code is available at https://github.com/wangzihuixmu/FedSAC.
FedPFT: Federated Proxy Fine-Tuning of Foundation Models
Apr 17, 2024Adapting Foundation Models (FMs) for downstream tasks through Federated Learning (FL) emerges a promising strategy for protecting data privacy and valuable FMs. Existing methods fine-tune FM by allocating sub-FM to clients in FL, however, leading to suboptimal performance due to insufficient tuning and inevitable error accumulations of gradients. In this paper, we propose Federated Proxy Fine-Tuning (FedPFT), a novel method enhancing FMs adaptation in downstream tasks through FL by two key modules. First, the sub-FM construction module employs a layer-wise compression approach, facilitating comprehensive FM fine-tuning across all layers by emphasizing those crucial neurons. Second, the sub-FM alignment module conducts a two-step distillations-layer-level and neuron-level-before and during FL fine-tuning respectively, to reduce error of gradient by accurately aligning sub-FM with FM under theoretical guarantees. Experimental results on seven commonly used datasets (i.e., four text and three vision) demonstrate the superiority of FedPFT.
Sunshine to Rainstorm: Cross-Weather Knowledge Distillation for Robust 3D Object Detection
Feb 28, 2024LiDAR-based 3D object detection models have traditionally struggled under rainy conditions due to the degraded and noisy scanning signals. Previous research has attempted to address this by simulating the noise from rain to improve the robustness of detection models. However, significant disparities exist between simulated and actual rain-impacted data points. In this work, we propose a novel rain simulation method, termed DRET, that unifies Dynamics and Rainy Environment Theory to provide a cost-effective means of expanding the available realistic rain data for 3D detection training. Furthermore, we present a Sunny-to-Rainy Knowledge Distillation (SRKD) approach to enhance 3D detection under rainy conditions. Extensive experiments on the WaymoOpenDataset large-scale dataset show that, when combined with the state-of-the-art DSVT model and other classical 3D detectors, our proposed framework demonstrates significant detection accuracy improvements, without losing efficiency. Remarkably, our framework also improves detection capabilities under sunny conditions, therefore offering a robust solution for 3D detection regardless of whether the weather is rainy or sunny
Urban Region Representation Learning with Attentive Fusion
Dec 07, 2023



An increasing number of related urban data sources have brought forth novel opportunities for learning urban region representations, i.e., embeddings. The embeddings describe latent features of urban regions and enable discovering similar regions for urban planning applications. Existing methods learn an embedding for a region using every different type of region feature data, and subsequently fuse all learned embeddings of a region to generate a unified region embedding. However, these studies often overlook the significance of the fusion process. The typical fusion methods rely on simple aggregation, such as summation and concatenation, thereby disregarding correlations within the fused region embeddings. To address this limitation, we propose a novel model named HAFusion. Our model is powered by a dual-feature attentive fusion module named DAFusion, which fuses embeddings from different region features to learn higher-order correlations between the regions as well as between the different types of region features. DAFusion is generic - it can be integrated into existing models to enhance their fusion process. Further, motivated by the effective fusion capability of an attentive module, we propose a hybrid attentive feature learning module named HALearning to enhance the embedding learning from each individual type of region features. Extensive experiments on three real-world datasets demonstrate that our model HAFusion outperforms state-of-the-art methods across three different prediction tasks. Using our learned region embedding leads to consistent and up to 31% improvements in the prediction accuracy.
FLGo: A Fully Customizable Federated Learning Platform
Jun 21, 2023Federated learning (FL) has found numerous applications in healthcare, finance, and IoT scenarios. Many existing FL frameworks offer a range of benchmarks to evaluate the performance of FL under realistic conditions. However, the process of customizing simulations to accommodate application-specific settings, data heterogeneity, and system heterogeneity typically remains unnecessarily complicated. This creates significant hurdles for traditional ML researchers in exploring the usage of FL, while also compromising the shareability of codes across FL frameworks. To address this issue, we propose a novel lightweight FL platform called FLGo, to facilitate cross-application FL studies with a high degree of shareability. Our platform offers 40+ benchmarks, 20+ algorithms, and 2 system simulators as out-of-the-box plugins. We also provide user-friendly APIs for quickly customizing new plugins that can be readily shared and reused for improved reproducibility. Finally, we develop a range of experimental tools, including parallel acceleration, experiment tracker and analyzer, and parameters auto-tuning. FLGo is maintained at \url{flgo-xmu.github.io}.
INCREASE: Inductive Graph Representation Learning for Spatio-Temporal Kriging
Feb 06, 2023Spatio-temporal kriging is an important problem in web and social applications, such as Web or Internet of Things, where things (e.g., sensors) connected into a web often come with spatial and temporal properties. It aims to infer knowledge for (the things at) unobserved locations using the data from (the things at) observed locations during a given time period of interest. This problem essentially requires \emph{inductive learning}. Once trained, the model should be able to perform kriging for different locations including newly given ones, without retraining. However, it is challenging to perform accurate kriging results because of the heterogeneous spatial relations and diverse temporal patterns. In this paper, we propose a novel inductive graph representation learning model for spatio-temporal kriging. We first encode heterogeneous spatial relations between the unobserved and observed locations by their spatial proximity, functional similarity, and transition probability. Based on each relation, we accurately aggregate the information of most correlated observed locations to produce inductive representations for the unobserved locations, by jointly modeling their similarities and differences. Then, we design relation-aware gated recurrent unit (GRU) networks to adaptively capture the temporal correlations in the generated sequence representations for each relation. Finally, we propose a multi-relation attention mechanism to dynamically fuse the complex spatio-temporal information at different time steps from multiple relations to compute the kriging output. Experimental results on three real-world datasets show that our proposed model outperforms state-of-the-art methods consistently, and the advantage is more significant when there are fewer observed locations. Our code is available at https://github.com/zhengchuanpan/INCREASE.