 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedPFT: Federated Proxy Fine-Tuning of Foundation Models
Apr 17, 2024Adapting Foundation Models (FMs) for downstream tasks through Federated Learning (FL) emerges a promising strategy for protecting data privacy and valuable FMs. Existing methods fine-tune FM by allocating sub-FM to clients in FL, however, leading to suboptimal performance due to insufficient tuning and inevitable error accumulations of gradients. In this paper, we propose Federated Proxy Fine-Tuning (FedPFT), a novel method enhancing FMs adaptation in downstream tasks through FL by two key modules. First, the sub-FM construction module employs a layer-wise compression approach, facilitating comprehensive FM fine-tuning across all layers by emphasizing those crucial neurons. Second, the sub-FM alignment module conducts a two-step distillations-layer-level and neuron-level-before and during FL fine-tuning respectively, to reduce error of gradient by accurately aligning sub-FM with FM under theoretical guarantees. Experimental results on seven commonly used datasets (i.e., four text and three vision) demonstrate the superiority of FedPFT.
EEMC: Embedding Enhanced Multi-tag Classification
Sep 29, 2020
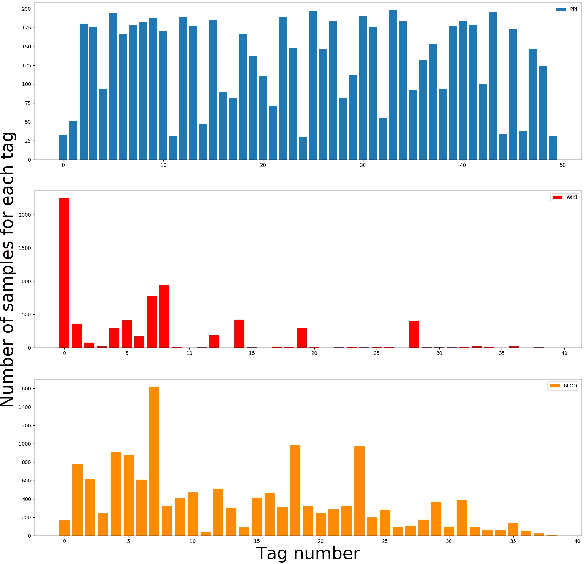
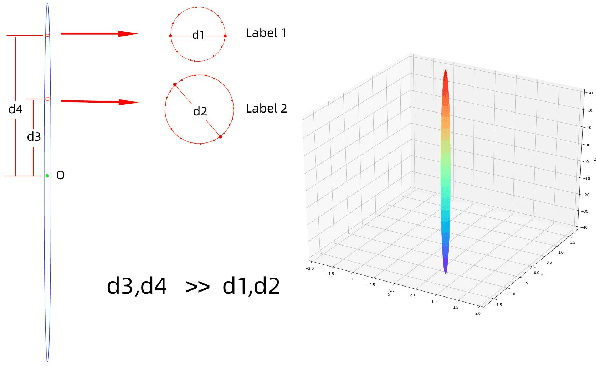
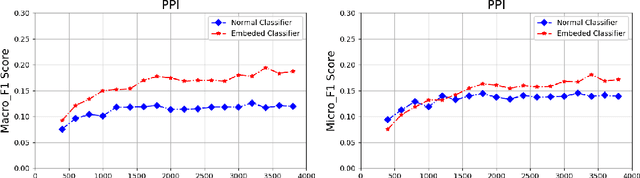
The recently occurred representation learning make an attractive performance in NLP and complex network, it is becoming a fundamental technology in machine learning and data mining. How to use representation learning to improve the performance of classifiers is a very significance research direction. We using representation learning technology to map raw data(node of graph) to a low-dimensional feature space. In this space, each raw data obtained a lower dimensional vector representation, we do some simple linear operations for those vectors to produce some virtual data, using those vectors and virtual data to training multi-tag classifier. After that we measured the performance of classifier by F1 score(Macro% F1 and Micro% F1). Our method make Macro F1 rise from 28 % - 450% and make average F1 score rise from 12 % - 224%. By contrast, we trained the classifier directly with the lower dimensional vector, and measured the performance of classifiers. We validate our algorithm on three public data sets, we found that the virtual data helped the classifier greatly improve the F1 score. Therefore, our algorithm is a effective way to improve the performance of classifier. These result suggest that the virtual data generated by simple linear operation, in representation space, still retains the information of the raw data. It's also have great significance to the learning of small sample data sets.
Global Optimal Path-Based Clustering Algorithm
Sep 17, 2019
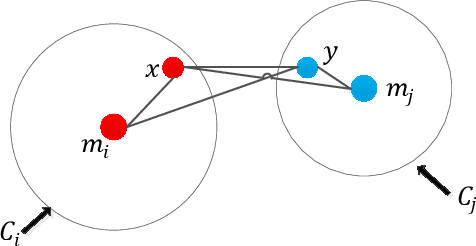
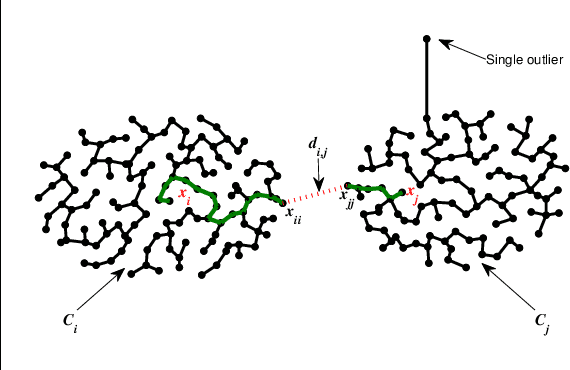
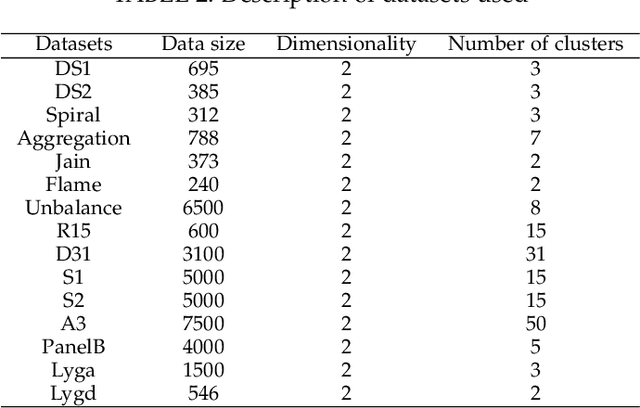
Combinatorial optimization problems for clustering are known to be NP-hard. Most optimization methods are not able to find the global optimum solution for all datasets. To solve this problem, we propose a global optimal path-based clustering (GOPC) algorithm in this paper. The GOPC algorithm is based on two facts: (1) medoids have the minimum degree in their clusters; (2) the minimax distance between two objects in one cluster is smaller than the minimax distance between objects in different clusters. Extensive experiments are conducted on synthetic and real-world datasets to evaluate the performance of the GOPC algorithm. The results on synthetic datasets show that the GOPC algorithm can recognize all kinds of clusters regardless of their shapes, sizes, or densities. Experimental results on real-world datasets demonstrate the effectiveness and efficiency of the GOPC algorithm. In addition, the GOPC algorithm needs only one parameter, i.e., the number of clusters, which can be estimated by the decision graph. The advantages mentioned above make GOPC a good candidate as a general clustering algorithm. Codes are available at https://github.com/Qidong-Liu/Clustering.