 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP4GCN: Vertical Federated Social Recommendation with Privacy-Preserving Two-Party Graph Convolution Networks
Oct 16, 2024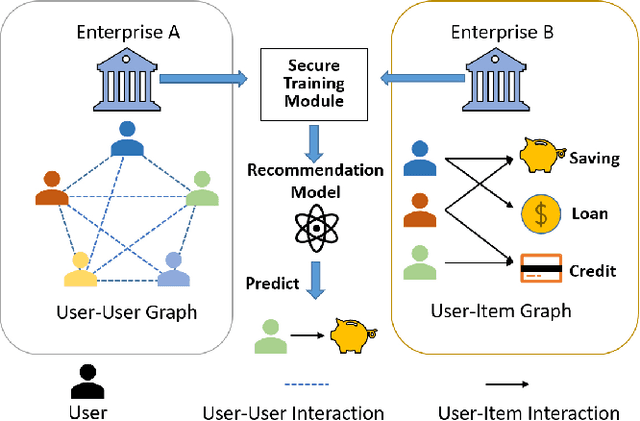
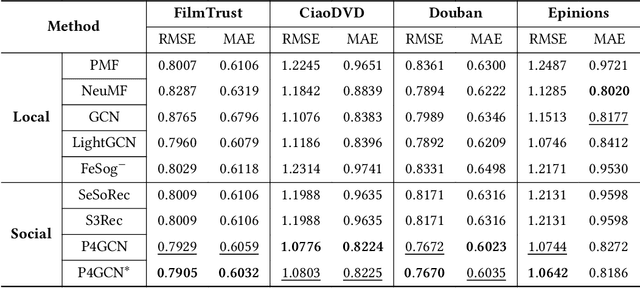

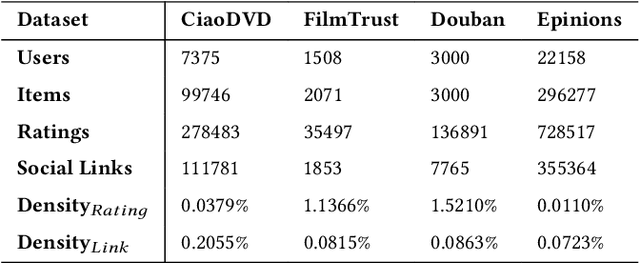
In recent years, graph neural networks (GNNs) have been commonly utilized for social recommendation systems. However, real-world scenarios often present challenges related to user privacy and business constraints, inhibiting direct access to valuable social information from other platforms. While many existing methods have tackled matrix factorization-based social recommendations without direct social data access, developing GNN-based federated social recommendation models under similar conditions remains largely unexplored. To address this issue, we propose a novel vertical federated social recommendation method leveraging privacy-preserving two-party graph convolution networks (P4GCN) to enhance recommendation accuracy without requiring direct access to sensitive social information. First, we introduce a Sandwich-Encryption module to ensure comprehensive data privacy during the collaborative computing process. Second, we provide a thorough theoretical analysis of the privacy guarantees, considering the participation of both curious and honest parties. Extensive experiments on four real-world datasets demonstrate that P4GCN outperforms state-of-the-art methods in terms of recommendation accuracy. The code is available at https://github.com/WwZzz/P4GCN.
Federated Graph Learning for Cross-Domain Recommendation
Oct 10, 2024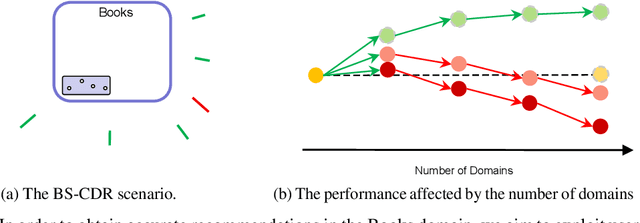
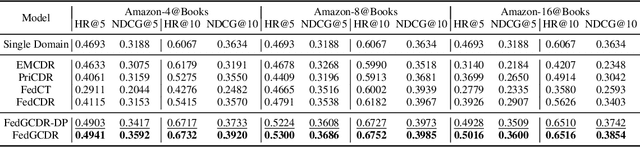
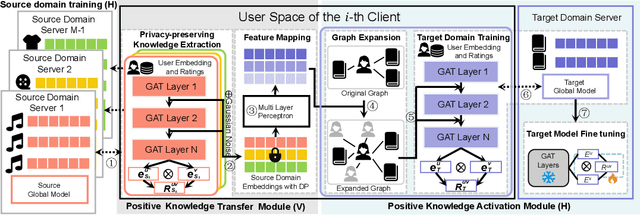
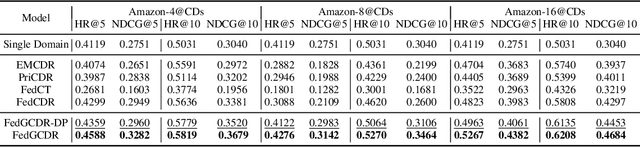
Cross-domain recommendation (CDR) offers a promising solution to the data sparsity problem by enabling knowledge transfer across source and target domains. However, many recent CDR models overlook crucial issues such as privacy as well as the risk of negative transfer (which negatively impact model performance), especially in multi-domain settings. To address these challenges, we propose FedGCDR, a novel federated graph learning framework that securely and effectively leverages positive knowledge from multiple source domains. First, we design a positive knowledge transfer module that ensures privacy during inter-domain knowledge transmission. This module employs differential privacy-based knowledge extraction combined with a feature mapping mechanism, transforming source domain embeddings from federated graph attention networks into reliable domain knowledge. Second, we design a knowledge activation module to filter out potential harmful or conflicting knowledge from source domains, addressing the issues of negative transfer. This module enhances target domain training by expanding the graph of the target domain to generate reliable domain attentions and fine-tunes the target model for improved negative knowledge filtering and more accurate predictions. We conduct extensive experiments on 16 popular domains of the Amazon dataset, demonstrating that FedGCDR significantly outperforms state-of-the-art methods.
Selective Knowledge Sharing for Personalized Federated Learning Under Capacity Heterogeneity
May 31, 2024Federated Learning (FL) stands to gain significant advantages from collaboratively training capacity-heterogeneous models, enabling the utilization of private data and computing power from low-capacity devices. However, the focus on personalizing capacity-heterogeneous models based on client-specific data has been limited, resulting in suboptimal local model utility, particularly for low-capacity clients. The heterogeneity in both data and device capacity poses two key challenges for model personalization: 1) accurately retaining necessary knowledge embedded within reduced submodels for each client, and 2) effectively sharing knowledge through aggregating size-varying parameters. To this end, we introduce Pa3dFL, a novel framework designed to enhance local model performance by decoupling and selectively sharing knowledge among capacity-heterogeneous models. First, we decompose each layer of the model into general and personal parameters. Then, we maintain uniform sizes for the general parameters across clients and aggregate them through direct averaging. Subsequently, we employ a hyper-network to generate size-varying personal parameters for clients using learnable embeddings. Finally, we facilitate the implicit aggregation of personal parameters by aggregating client embeddings through a self-attention module. We conducted extensive experiments on three datasets to evaluate the effectiveness of Pa3dFL. Our findings indicate that Pa3dFL consistently outperforms baseline methods across various heterogeneity settings. Moreover, Pa3dFL demonstrates competitive communication and computation efficiency compared to baseline approaches, highlighting its practicality and adaptability in adverse system conditions.
FedSAC: Dynamic Submodel Allocation for Collaborative Fairness in Federated Learning
May 28, 2024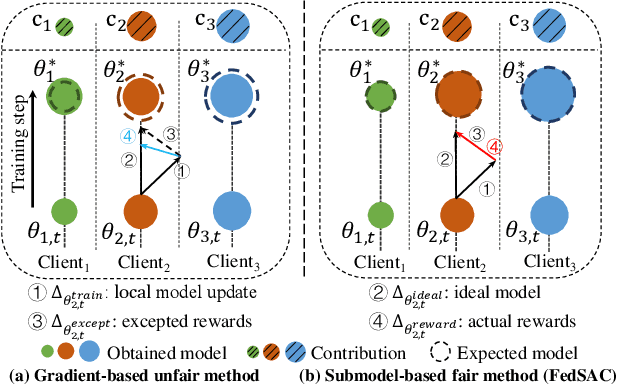



Collaborative fairness stands as an essential element in federated learning to encourage client participation by equitably distributing rewards based on individual contributions. Existing methods primarily focus on adjusting gradient allocations among clients to achieve collaborative fairness. However, they frequently overlook crucial factors such as maintaining consistency across local models and catering to the diverse requirements of high-contributing clients. This oversight inevitably decreases both fairness and model accuracy in practice. To address these issues, we propose FedSAC, a novel Federated learning framework with dynamic Submodel Allocation for Collaborative fairness, backed by a theoretical convergence guarantee. First, we present the concept of "bounded collaborative fairness (BCF)", which ensures fairness by tailoring rewards to individual clients based on their contributions. Second, to implement the BCF, we design a submodel allocation module with a theoretical guarantee of fairness. This module incentivizes high-contributing clients with high-performance submodels containing a diverse range of crucial neurons, thereby preserving consistency across local models. Third, we further develop a dynamic aggregation module to adaptively aggregate submodels, ensuring the equitable treatment of low-frequency neurons and consequently enhancing overall model accuracy. Extensive experiments conducted on three public benchmarks demonstrate that FedSAC outperforms all baseline methods in both fairness and model accuracy. We see this work as a significant step towards incentivizing broader client participation in federated learning. The source code is available at https://github.com/wangzihuixmu/FedSAC.
FedPFT: Federated Proxy Fine-Tuning of Foundation Models
Apr 17, 2024Adapting Foundation Models (FMs) for downstream tasks through Federated Learning (FL) emerges a promising strategy for protecting data privacy and valuable FMs. Existing methods fine-tune FM by allocating sub-FM to clients in FL, however, leading to suboptimal performance due to insufficient tuning and inevitable error accumulations of gradients. In this paper, we propose Federated Proxy Fine-Tuning (FedPFT), a novel method enhancing FMs adaptation in downstream tasks through FL by two key modules. First, the sub-FM construction module employs a layer-wise compression approach, facilitating comprehensive FM fine-tuning across all layers by emphasizing those crucial neurons. Second, the sub-FM alignment module conducts a two-step distillations-layer-level and neuron-level-before and during FL fine-tuning respectively, to reduce error of gradient by accurately aligning sub-FM with FM under theoretical guarantees. Experimental results on seven commonly used datasets (i.e., four text and three vision) demonstrate the superiority of FedPFT.
FLGo: A Fully Customizable Federated Learning Platform
Jun 21, 2023Federated learning (FL) has found numerous applications in healthcare, finance, and IoT scenarios. Many existing FL frameworks offer a range of benchmarks to evaluate the performance of FL under realistic conditions. However, the process of customizing simulations to accommodate application-specific settings, data heterogeneity, and system heterogeneity typically remains unnecessarily complicated. This creates significant hurdles for traditional ML researchers in exploring the usage of FL, while also compromising the shareability of codes across FL frameworks. To address this issue, we propose a novel lightweight FL platform called FLGo, to facilitate cross-application FL studies with a high degree of shareability. Our platform offers 40+ benchmarks, 20+ algorithms, and 2 system simulators as out-of-the-box plugins. We also provide user-friendly APIs for quickly customizing new plugins that can be readily shared and reused for improved reproducibility. Finally, we develop a range of experimental tools, including parallel acceleration, experiment tracker and analyzer, and parameters auto-tuning. FLGo is maintained at \url{flgo-xmu.github.io}.