 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Domain Shift Eraser
Mar 17, 2025Federated learning (FL) is emerging as a promising technique for collaborative learning without local data leaving their devices. However, clients' data originating from diverse domains may degrade model performance due to domain shifts, preventing the model from learning consistent representation space. In this paper, we propose a novel FL framework, Federated Domain Shift Eraser (FDSE), to improve model performance by differently erasing each client's domain skew and enhancing their consensus. First, we formulate the model forward passing as an iterative deskewing process that extracts and then deskews features alternatively. This is efficiently achieved by decomposing each original layer in the neural network into a Domain-agnostic Feature Extractor (DFE) and a Domain-specific Skew Eraser (DSE). Then, a regularization term is applied to promise the effectiveness of feature deskewing by pulling local statistics of DSE's outputs close to the globally consistent ones. Finally, DFE modules are fairly aggregated and broadcast to all the clients to maximize their consensus, and DSE modules are personalized for each client via similarity-aware aggregation to erase their domain skew differently. Comprehensive experiments were conducted on three datasets to confirm the advantages of our method in terms of accuracy, efficiency, and generalizability.
ST-Align: A Multimodal Foundation Model for Image-Gene Alignment in Spatial Transcriptomics
Nov 25, 2024



Spatial transcriptomics (ST) provides high-resolution pathological images and whole-transcriptomic expression profiles at individual spots across whole-slide scales. This setting makes it an ideal data source to develop multimodal foundation models. Although recent studies attempted to fine-tune visual encoders with trainable gene encoders based on spot-level, the absence of a wider slide perspective and spatial intrinsic relationships limits their ability to capture ST-specific insights effectively. Here, we introduce ST-Align, the first foundation model designed for ST that deeply aligns image-gene pairs by incorporating spatial context, effectively bridging pathological imaging with genomic features. We design a novel pretraining framework with a three-target alignment strategy for ST-Align, enabling (1) multi-scale alignment across image-gene pairs, capturing both spot- and niche-level contexts for a comprehensive perspective, and (2) cross-level alignment of multimodal insights, connecting localized cellular characteristics and broader tissue architecture. Additionally, ST-Align employs specialized encoders tailored to distinct ST contexts, followed by an Attention-Based Fusion Network (ABFN) for enhanced multimodal fusion, effectively merging domain-shared knowledge with ST-specific insights from both pathological and genomic data. We pre-trained ST-Align on 1.3 million spot-niche pairs and evaluated its performance through two downstream tasks across six datasets, demonstrating superior zero-shot and few-shot capabilities. ST-Align highlights the potential for reducing the cost of ST and providing valuable insights into the distinction of critical compositions within human tissue.
Federated Graph Learning for Cross-Domain Recommendation
Oct 10, 2024
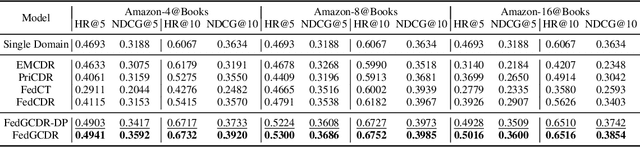
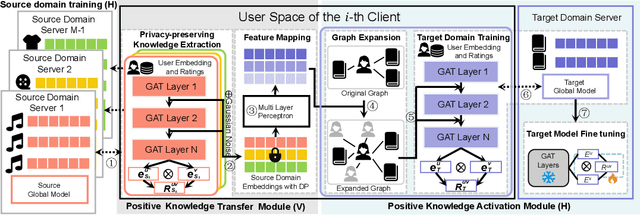
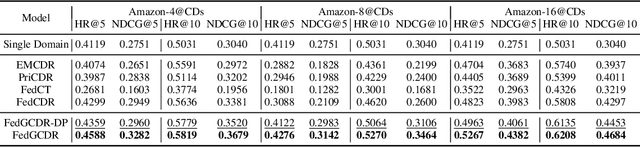
Cross-domain recommendation (CDR) offers a promising solution to the data sparsity problem by enabling knowledge transfer across source and target domains. However, many recent CDR models overlook crucial issues such as privacy as well as the risk of negative transfer (which negatively impact model performance), especially in multi-domain settings. To address these challenges, we propose FedGCDR, a novel federated graph learning framework that securely and effectively leverages positive knowledge from multiple source domains. First, we design a positive knowledge transfer module that ensures privacy during inter-domain knowledge transmission. This module employs differential privacy-based knowledge extraction combined with a feature mapping mechanism, transforming source domain embeddings from federated graph attention networks into reliable domain knowledge. Second, we design a knowledge activation module to filter out potential harmful or conflicting knowledge from source domains, addressing the issues of negative transfer. This module enhances target domain training by expanding the graph of the target domain to generate reliable domain attentions and fine-tunes the target model for improved negative knowledge filtering and more accurate predictions. We conduct extensive experiments on 16 popular domains of the Amazon dataset, demonstrating that FedGCDR significantly outperforms state-of-the-art methods.
Selective Knowledge Sharing for Personalized Federated Learning Under Capacity Heterogeneity
May 31, 2024Federated Learning (FL) stands to gain significant advantages from collaboratively training capacity-heterogeneous models, enabling the utilization of private data and computing power from low-capacity devices. However, the focus on personalizing capacity-heterogeneous models based on client-specific data has been limited, resulting in suboptimal local model utility, particularly for low-capacity clients. The heterogeneity in both data and device capacity poses two key challenges for model personalization: 1) accurately retaining necessary knowledge embedded within reduced submodels for each client, and 2) effectively sharing knowledge through aggregating size-varying parameters. To this end, we introduce Pa3dFL, a novel framework designed to enhance local model performance by decoupling and selectively sharing knowledge among capacity-heterogeneous models. First, we decompose each layer of the model into general and personal parameters. Then, we maintain uniform sizes for the general parameters across clients and aggregate them through direct averaging. Subsequently, we employ a hyper-network to generate size-varying personal parameters for clients using learnable embeddings. Finally, we facilitate the implicit aggregation of personal parameters by aggregating client embeddings through a self-attention module. We conducted extensive experiments on three datasets to evaluate the effectiveness of Pa3dFL. Our findings indicate that Pa3dFL consistently outperforms baseline methods across various heterogeneity settings. Moreover, Pa3dFL demonstrates competitive communication and computation efficiency compared to baseline approaches, highlighting its practicality and adaptability in adverse system conditions.
FedSAC: Dynamic Submodel Allocation for Collaborative Fairness in Federated Learning
May 28, 2024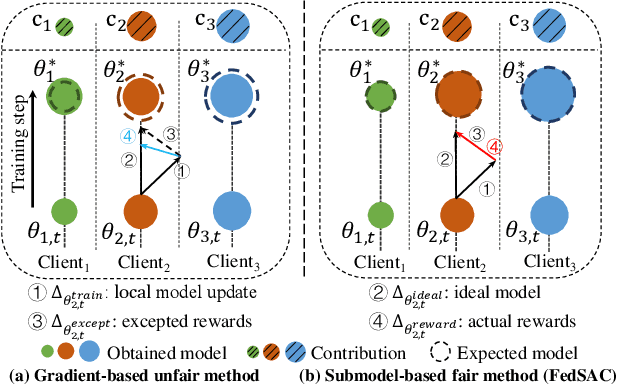



Collaborative fairness stands as an essential element in federated learning to encourage client participation by equitably distributing rewards based on individual contributions. Existing methods primarily focus on adjusting gradient allocations among clients to achieve collaborative fairness. However, they frequently overlook crucial factors such as maintaining consistency across local models and catering to the diverse requirements of high-contributing clients. This oversight inevitably decreases both fairness and model accuracy in practice. To address these issues, we propose FedSAC, a novel Federated learning framework with dynamic Submodel Allocation for Collaborative fairness, backed by a theoretical convergence guarantee. First, we present the concept of "bounded collaborative fairness (BCF)", which ensures fairness by tailoring rewards to individual clients based on their contributions. Second, to implement the BCF, we design a submodel allocation module with a theoretical guarantee of fairness. This module incentivizes high-contributing clients with high-performance submodels containing a diverse range of crucial neurons, thereby preserving consistency across local models. Third, we further develop a dynamic aggregation module to adaptively aggregate submodels, ensuring the equitable treatment of low-frequency neurons and consequently enhancing overall model accuracy. Extensive experiments conducted on three public benchmarks demonstrate that FedSAC outperforms all baseline methods in both fairness and model accuracy. We see this work as a significant step towards incentivizing broader client participation in federated learning. The source code is available at https://github.com/wangzihuixmu/FedSAC.