 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen OpenClaw Meets Hospital: Toward an Agentic Operating System for Dynamic Clinical Workflows
Mar 12, 2026Large language model (LLM) agents extend conventional generative models by integrating reasoning, tool invocation, and persistent memory. Recent studies suggest that such agents may significantly improve clinical workflows by automating documentation, coordinating care processes, and assisting medical decision making. However, despite rapid progress, deploying autonomous agents in healthcare environments remains difficult due to reliability limitations, security risks, and insufficient long-term memory mechanisms. This work proposes an architecture that adapts LLM agents for hospital environments. The design introduces four core components: a restricted execution environment inspired by Linux multi-user systems, a document-centric interaction paradigm connecting patient and clinician agents, a page-indexed memory architecture designed for long-term clinical context management, and a curated medical skills library enabling ad-hoc composition of clinical task sequences. Rather than granting agents unrestricted system access, the architecture constrains actions through predefined skill interfaces and resource isolation. We argue that such a system forms the basis of an Agentic Operating System for Hospital, a computing layer capable of coordinating clinical workflows while maintaining safety, transparency, and auditability. This work grounds the design in OpenClaw, an open-source autonomous agent framework that structures agent capabilities as a curated library of discrete skills, and extends it with the infrastructure-level constraints required for safe clinical deployment.
ST-Align: A Multimodal Foundation Model for Image-Gene Alignment in Spatial Transcriptomics
Nov 25, 2024



Spatial transcriptomics (ST) provides high-resolution pathological images and whole-transcriptomic expression profiles at individual spots across whole-slide scales. This setting makes it an ideal data source to develop multimodal foundation models. Although recent studies attempted to fine-tune visual encoders with trainable gene encoders based on spot-level, the absence of a wider slide perspective and spatial intrinsic relationships limits their ability to capture ST-specific insights effectively. Here, we introduce ST-Align, the first foundation model designed for ST that deeply aligns image-gene pairs by incorporating spatial context, effectively bridging pathological imaging with genomic features. We design a novel pretraining framework with a three-target alignment strategy for ST-Align, enabling (1) multi-scale alignment across image-gene pairs, capturing both spot- and niche-level contexts for a comprehensive perspective, and (2) cross-level alignment of multimodal insights, connecting localized cellular characteristics and broader tissue architecture. Additionally, ST-Align employs specialized encoders tailored to distinct ST contexts, followed by an Attention-Based Fusion Network (ABFN) for enhanced multimodal fusion, effectively merging domain-shared knowledge with ST-specific insights from both pathological and genomic data. We pre-trained ST-Align on 1.3 million spot-niche pairs and evaluated its performance through two downstream tasks across six datasets, demonstrating superior zero-shot and few-shot capabilities. ST-Align highlights the potential for reducing the cost of ST and providing valuable insights into the distinction of critical compositions within human tissue.
LiDAR-based End-to-end Temporal Perception for Vehicle-Infrastructure Cooperation
Nov 22, 2024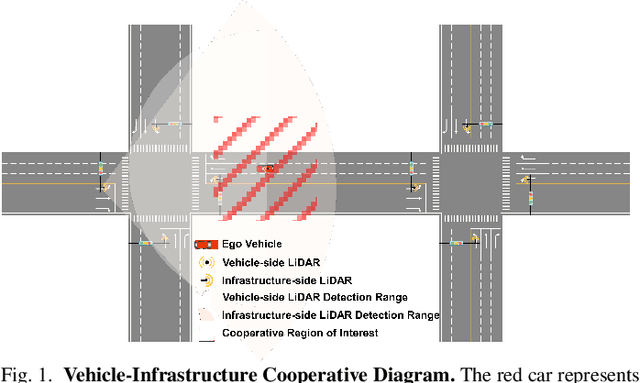
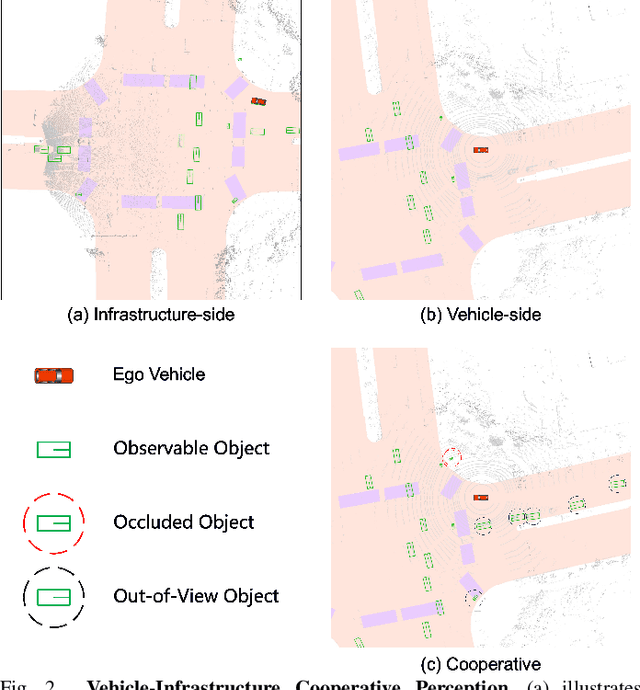
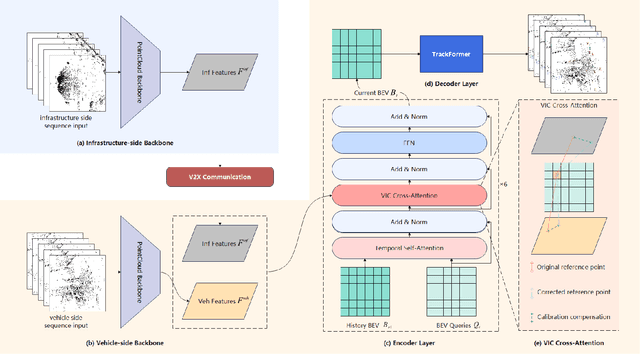
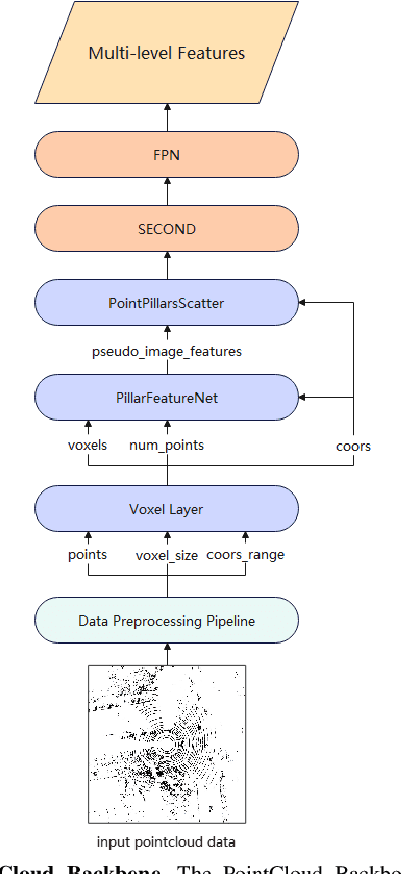
Temporal perception, the ability to detect and track objects over time, is critical in autonomous driving for maintaining a comprehensive understanding of dynamic environments. However, this task is hindered by significant challenges, including incomplete perception caused by occluded objects and observational blind spots, which are common in single-vehicle perception systems. To address these issues, we introduce LET-VIC, a LiDAR-based End-to-End Tracking framework for Vehicle-Infrastructure Cooperation (VIC). LET-VIC leverages Vehicle-to-Everything (V2X) communication to enhance temporal perception by fusing spatial and temporal data from both vehicle and infrastructure sensors. First, it spatially integrates Bird's Eye View (BEV) features from vehicle-side and infrastructure-side LiDAR data, creating a comprehensive view that mitigates occlusions and compensates for blind spots. Second, LET-VIC incorporates temporal context across frames, allowing the model to leverage historical data for enhanced tracking stability and accuracy. To further improve robustness, LET-VIC includes a Calibration Error Compensation (CEC) module to address sensor misalignments and ensure precise feature alignment. Experiments on the V2X-Seq-SPD dataset demonstrate that LET-VIC significantly outperforms baseline models, achieving at least a 13.7% improvement in mAP and a 13.1% improvement in AMOTA without considering communication delays. This work offers a practical solution and a new research direction for advancing temporal perception in autonomous driving through vehicle-infrastructure cooperation.
Leveraging Temporal Contexts to Enhance Vehicle-Infrastructure Cooperative Perception
Aug 20, 2024Infrastructure sensors installed at elevated positions offer a broader perception range and encounter fewer occlusions. Integrating both infrastructure and ego-vehicle data through V2X communication, known as vehicle-infrastructure cooperation, has shown considerable advantages in enhancing perception capabilities and addressing corner cases encountered in single-vehicle autonomous driving. However, cooperative perception still faces numerous challenges, including limited communication bandwidth and practical communication interruptions. In this paper, we propose CTCE, a novel framework for cooperative 3D object detection. This framework transmits queries with temporal contexts enhancement, effectively balancing transmission efficiency and performance to accommodate real-world communication conditions. Additionally, we propose a temporal-guided fusion module to further improve performance. The roadside temporal enhancement and vehicle-side spatial-temporal fusion together constitute a multi-level temporal contexts integration mechanism, fully leveraging temporal information to enhance performance. Furthermore, a motion-aware reconstruction module is introduced to recover lost roadside queries due to communication interruptions. Experimental results on V2X-Seq and V2X-Sim datasets demonstrate that CTCE outperforms the baseline QUEST, achieving improvements of 3.8% and 1.3% in mAP, respectively. Experiments under communication interruption conditions validate CTCE's robustness to communication interruptions.
SurvMamba: State Space Model with Multi-grained Multi-modal Interaction for Survival Prediction
Apr 11, 2024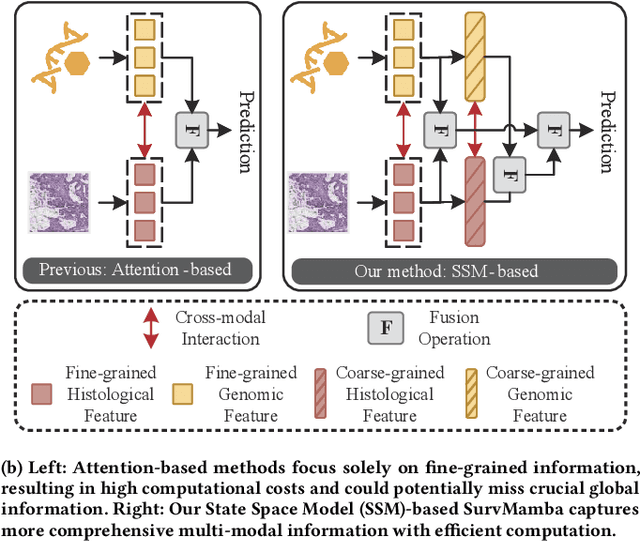
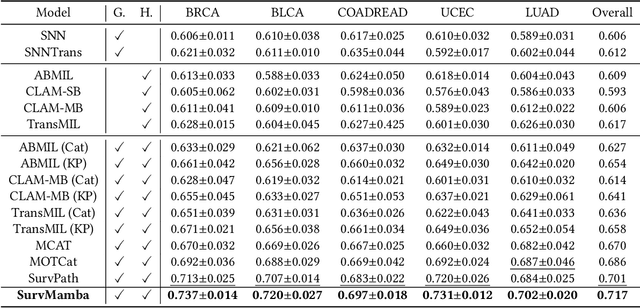
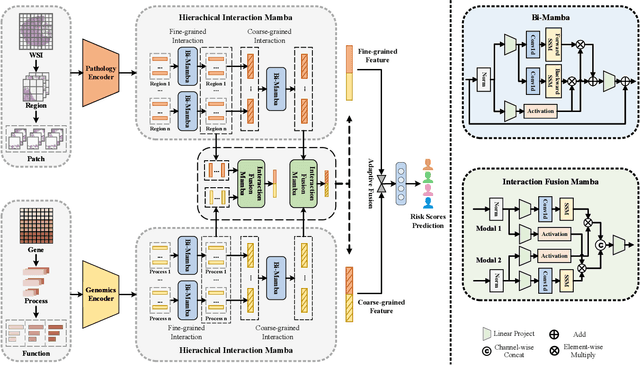
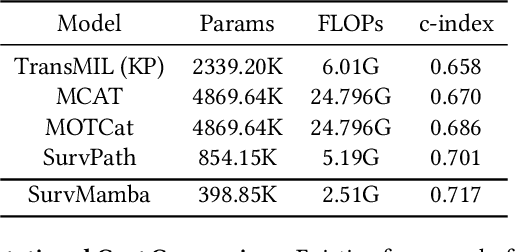
Multi-modal learning that combines pathological images with genomic data has significantly enhanced the accuracy of survival prediction. Nevertheless, existing methods have not fully utilized the inherent hierarchical structure within both whole slide images (WSIs) and transcriptomic data, from which better intra-modal representations and inter-modal integration could be derived. Moreover, many existing studies attempt to improve multi-modal representations through attention mechanisms, which inevitably lead to high complexity when processing high-dimensional WSIs and transcriptomic data. Recently, a structured state space model named Mamba emerged as a promising approach for its superior performance in modeling long sequences with low complexity. In this study, we propose Mamba with multi-grained multi-modal interaction (SurvMamba) for survival prediction. SurvMamba is implemented with a Hierarchical Interaction Mamba (HIM) module that facilitates efficient intra-modal interactions at different granularities, thereby capturing more detailed local features as well as rich global representations. In addition, an Interaction Fusion Mamba (IFM) module is used for cascaded inter-modal interactive fusion, yielding more comprehensive features for survival prediction. Comprehensive evaluations on five TCGA datasets demonstrate that SurvMamba outperforms other existing methods in terms of performance and computational cost.
End-to-End Autonomous Driving through V2X Cooperation
Mar 31, 2024



Cooperatively utilizing both ego-vehicle and infrastructure sensor data via V2X communication has emerged as a promising approach for advanced autonomous driving. However, current research mainly focuses on improving individual modules, rather than taking end-to-end learning to optimize final planning performance, resulting in underutilized data potential. In this paper, we introduce UniV2X, a pioneering cooperative autonomous driving framework that seamlessly integrates all key driving modules across diverse views into a unified network. We propose a sparse-dense hybrid data transmission and fusion mechanism for effective vehicle-infrastructure cooperation, offering three advantages: 1) Effective for simultaneously enhancing agent perception, online mapping, and occupancy prediction, ultimately improving planning performance. 2) Transmission-friendly for practical and limited communication conditions. 3) Reliable data fusion with interpretability of this hybrid data. We implement UniV2X, as well as reproducing several benchmark methods, on the challenging DAIR-V2X, the real-world cooperative driving dataset. Experimental results demonstrate the effectiveness of UniV2X in significantly enhancing planning performance, as well as all intermediate output performance. Code is at https://github.com/AIR-THU/UniV2X.
RCooper: A Real-world Large-scale Dataset for Roadside Cooperative Perception
Mar 31, 2024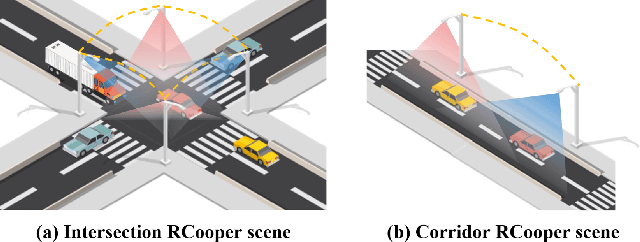
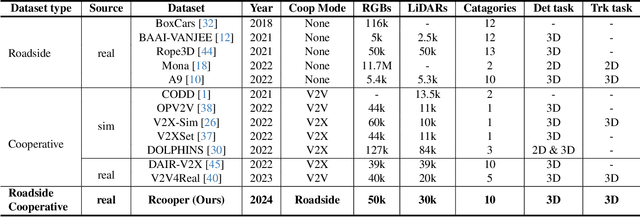
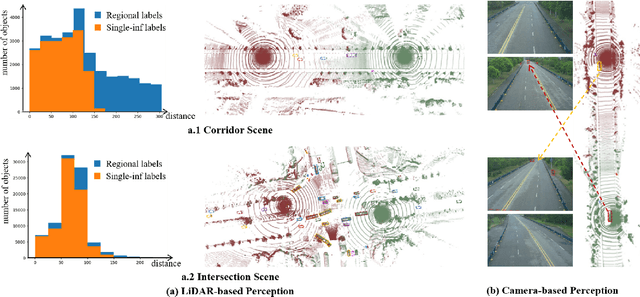

The value of roadside perception, which could extend the boundaries of autonomous driving and traffic management, has gradually become more prominent and acknowledged in recent years. However, existing roadside perception approaches only focus on the single-infrastructure sensor system, which cannot realize a comprehensive understanding of a traffic area because of the limited sensing range and blind spots. Orienting high-quality roadside perception, we need Roadside Cooperative Perception (RCooper) to achieve practical area-coverage roadside perception for restricted traffic areas. Rcooper has its own domain-specific challenges, but further exploration is hindered due to the lack of datasets. We hence release the first real-world, large-scale RCooper dataset to bloom the research on practical roadside cooperative perception, including detection and tracking. The manually annotated dataset comprises 50k images and 30k point clouds, including two representative traffic scenes (i.e., intersection and corridor). The constructed benchmarks prove the effectiveness of roadside cooperation perception and demonstrate the direction of further research. Codes and dataset can be accessed at: https://github.com/AIR-THU/DAIR-RCooper.
Generalizable Whole Slide Image Classification with Fine-Grained Visual-Semantic Interaction
Feb 29, 2024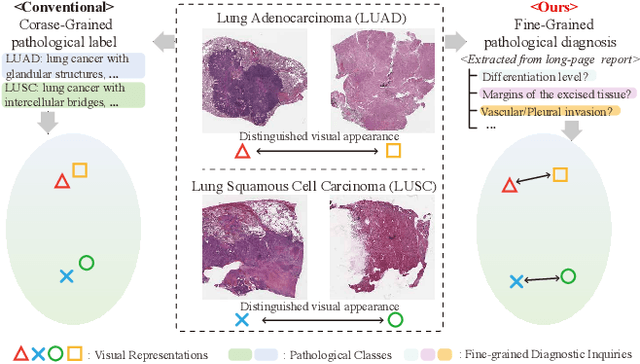

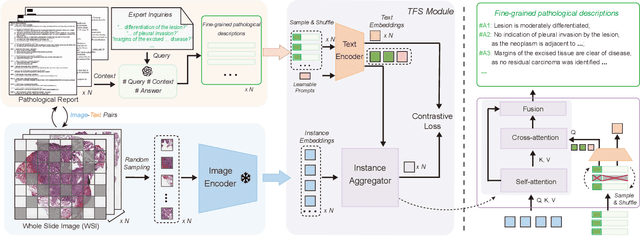
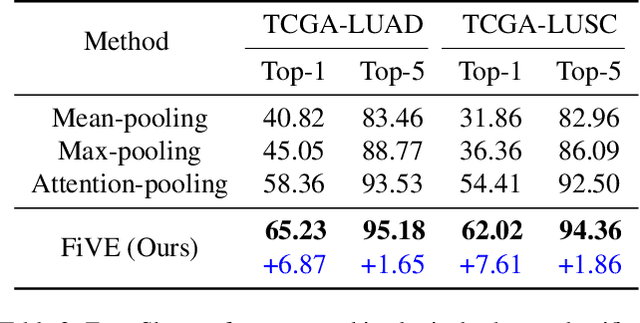
Whole Slide Image (WSI) classification is often formulated as a Multiple Instance Learning (MIL) problem. Recently, Vision-Language Models (VLMs) have demonstrated remarkable performance in WSI classification. However, existing methods leverage coarse-grained pathogenetic descriptions for visual representation supervision, which are insufficient to capture the complex visual appearance of pathogenetic images, hindering the generalizability of models on diverse downstream tasks. Additionally, processing high-resolution WSIs can be computationally expensive. In this paper, we propose a novel "Fine-grained Visual-Semantic Interaction" (FiVE) framework for WSI classification. It is designed to enhance the model's generalizability by leveraging the interplay between localized visual patterns and fine-grained pathological semantics. Specifically, with meticulously designed queries, we start by utilizing a large language model to extract fine-grained pathological descriptions from various non-standardized raw reports. The output descriptions are then reconstructed into fine-grained labels used for training. By introducing a Task-specific Fine-grained Semantics (TFS) module, we enable prompts to capture crucial visual information in WSIs, which enhances representation learning and augments generalization capabilities significantly. Furthermore, given that pathological visual patterns are redundantly distributed across tissue slices, we sample a subset of visual instances during training. Our method demonstrates robust generalizability and strong transferability, dominantly outperforming the counterparts on the TCGA Lung Cancer dataset with at least 9.19% higher accuracy in few-shot experiments.
Learning Cooperative Trajectory Representations for Motion Forecasting
Nov 01, 2023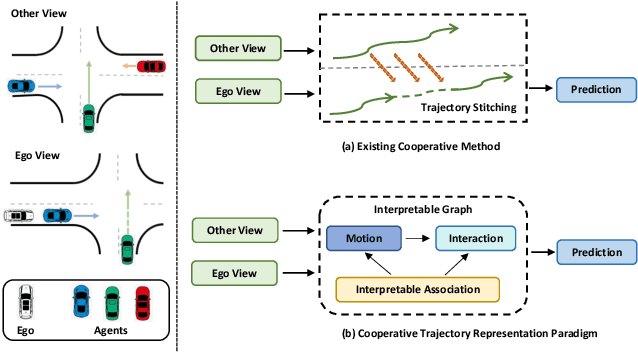
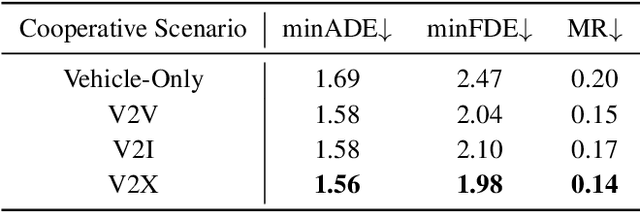
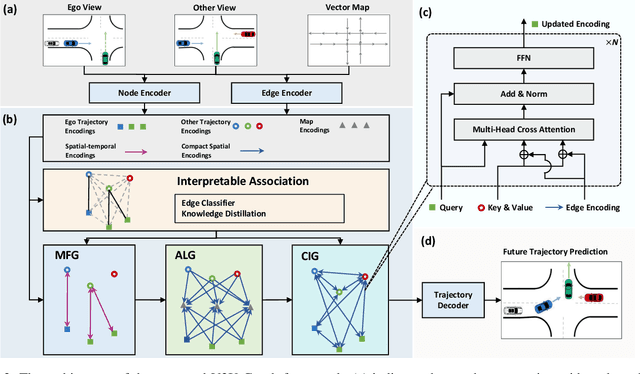
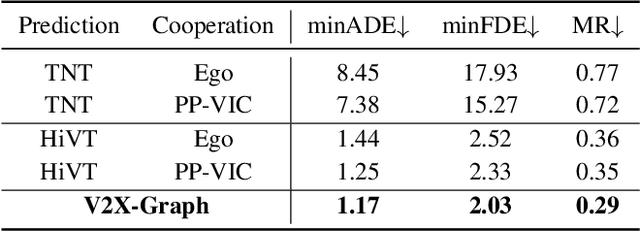
Motion forecasting is an essential task for autonomous driving, and the effective information utilization from infrastructure and other vehicles can enhance motion forecasting capabilities. Existing research have primarily focused on leveraging single-frame cooperative information to enhance the limited perception capability of the ego vehicle, while underutilizing the motion and interaction information of traffic participants observed from cooperative devices. In this paper, we first propose the cooperative trajectory representations learning paradigm. Specifically, we present V2X-Graph, the first interpretable and end-to-end learning framework for cooperative motion forecasting. V2X-Graph employs an interpretable graph to fully leverage the cooperative motion and interaction contexts. Experimental results on the vehicle-to-infrastructure (V2I) motion forecasting dataset, V2X-Seq, demonstrate the effectiveness of V2X-Graph. To further evaluate on V2X scenario, we construct the first real-world vehicle-to-everything (V2X) motion forecasting dataset V2X-Traj, and the performance shows the advantage of our method. We hope both V2X-Graph and V2X-Traj can facilitate the further development of cooperative motion forecasting. Find project at https://github.com/AIR-THU/V2X-Graph, find data at https://github.com/AIR-THU/DAIR-V2X-Seq.
QUEST: Query Stream for Vehicle-Infrastructure Cooperative Perception
Aug 03, 2023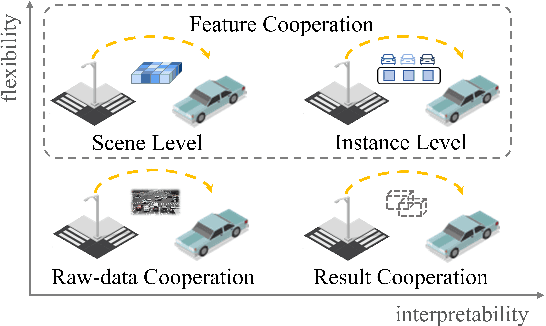
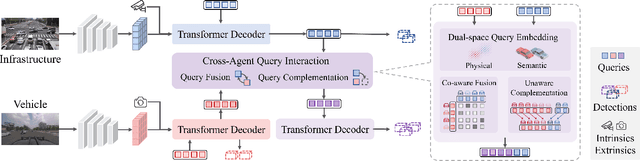
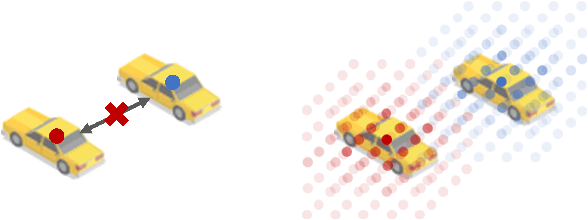
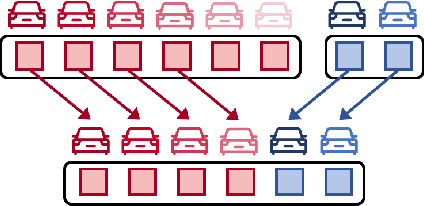
Cooperative perception can effectively enhance individual perception performance by providing additional viewpoint and expanding the sensing field. Existing cooperation paradigms are either interpretable (result cooperation) or flexible (feature cooperation). In this paper, we propose the concept of query cooperation to enable interpretable instance-level flexible feature interaction. To specifically explain the concept, we propose a cooperative perception framework, termed QUEST, which let query stream flow among agents. The cross-agent queries are interacted via fusion for co-aware instances and complementation for individual unaware instances. Taking camera-based vehicle-infrastructure perception as a typical practical application scene, the experimental results on the real-world dataset, DAIR-V2X-Seq, demonstrate the effectiveness of QUEST and further reveal the advantage of the query cooperation paradigm on transmission flexibility and robustness to packet dropout. We hope our work can further facilitate the cross-agent representation interaction for better cooperative perception in practice.