 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Expert Trajectory Utilization in LLM Post-training
Dec 12, 2025While effective post-training integrates Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), the optimal mechanism for utilizing expert trajectories remains unresolved. We propose the Plasticity-Ceiling Framework to theoretically ground this landscape, decomposing performance into foundational SFT performance and the subsequent RL plasticity. Through extensive benchmarking, we establish the Sequential SFT-then-RL pipeline as the superior standard, overcoming the stability deficits of synchronized approaches. Furthermore, we derive precise scaling guidelines: (1) Transitioning to RL at the SFT Stable or Mild Overfitting Sub-phase maximizes the final ceiling by securing foundational SFT performance without compromising RL plasticity; (2) Refuting ``Less is More'' in the context of SFT-then-RL scaling, we demonstrate that Data Scale determines the primary post-training potential, while Trajectory Difficulty acts as a performance multiplier; and (3) Identifying that the Minimum SFT Validation Loss serves as a robust indicator for selecting the expert trajectories that maximize the final performance ceiling. Our findings provide actionable guidelines for maximizing the value extracted from expert trajectories.
CPathAgent: An Agent-based Foundation Model for Interpretable High-Resolution Pathology Image Analysis Mimicking Pathologists' Diagnostic Logic
May 26, 2025Recent advances in computational pathology have led to the emergence of numerous foundation models. However, these approaches fail to replicate the diagnostic process of pathologists, as they either simply rely on general-purpose encoders with multi-instance learning for classification or directly apply multimodal models to generate reports from images. A significant limitation is their inability to emulate the diagnostic logic employed by pathologists, who systematically examine slides at low magnification for overview before progressively zooming in on suspicious regions to formulate comprehensive diagnoses. To address this gap, we introduce CPathAgent, an innovative agent-based model that mimics pathologists' reasoning processes by autonomously executing zoom-in/out and navigation operations across pathology images based on observed visual features. To achieve this, we develop a multi-stage training strategy unifying patch-level, region-level, and whole-slide capabilities within a single model, which is essential for mimicking pathologists, who require understanding and reasoning capabilities across all three scales. This approach generates substantially more detailed and interpretable diagnostic reports compared to existing methods, particularly for huge region understanding. Additionally, we construct an expert-validated PathMMU-HR$^{2}$, the first benchmark for huge region analysis, a critical intermediate scale between patches and whole slides, as diagnosticians typically examine several key regions rather than entire slides at once. Extensive experiments demonstrate that CPathAgent consistently outperforms existing approaches across three scales of benchmarks, validating the effectiveness of our agent-based diagnostic approach and highlighting a promising direction for the future development of computational pathology.
Baichuan-Omni-1.5 Technical Report
Jan 26, 2025



We introduce Baichuan-Omni-1.5, an omni-modal model that not only has omni-modal understanding capabilities but also provides end-to-end audio generation capabilities. To achieve fluent and high-quality interaction across modalities without compromising the capabilities of any modality, we prioritized optimizing three key aspects. First, we establish a comprehensive data cleaning and synthesis pipeline for multimodal data, obtaining about 500B high-quality data (text, audio, and vision). Second, an audio-tokenizer (Baichuan-Audio-Tokenizer) has been designed to capture both semantic and acoustic information from audio, enabling seamless integration and enhanced compatibility with MLLM. Lastly, we designed a multi-stage training strategy that progressively integrates multimodal alignment and multitask fine-tuning, ensuring effective synergy across all modalities. Baichuan-Omni-1.5 leads contemporary models (including GPT4o-mini and MiniCPM-o 2.6) in terms of comprehensive omni-modal capabilities. Notably, it achieves results comparable to leading models such as Qwen2-VL-72B across various multimodal medical benchmarks.
Enhancing Uncertainty Modeling with Semantic Graph for Hallucination Detection
Jan 02, 2025



Large Language Models (LLMs) are prone to hallucination with non-factual or unfaithful statements, which undermines the applications in real-world scenarios. Recent researches focus on uncertainty-based hallucination detection, which utilizes the output probability of LLMs for uncertainty calculation and does not rely on external knowledge or frequent sampling from LLMs. Whereas, most approaches merely consider the uncertainty of each independent token, while the intricate semantic relations among tokens and sentences are not well studied, which limits the detection of hallucination that spans over multiple tokens and sentences in the passage. In this paper, we propose a method to enhance uncertainty modeling with semantic graph for hallucination detection. Specifically, we first construct a semantic graph that well captures the relations among entity tokens and sentences. Then, we incorporate the relations between two entities for uncertainty propagation to enhance sentence-level hallucination detection. Given that hallucination occurs due to the conflict between sentences, we further present a graph-based uncertainty calibration method that integrates the contradiction probability of the sentence with its neighbors in the semantic graph for uncertainty calculation. Extensive experiments on two datasets show the great advantages of our proposed approach. In particular, we obtain substantial improvements with 19.78% in passage-level hallucination detection.
Baichuan-Omni Technical Report
Oct 11, 2024



The salient multimodal capabilities and interactive experience of GPT-4o highlight its critical role in practical applications, yet it lacks a high-performing open-source counterpart. In this paper, we introduce Baichuan-Omni, the first open-source 7B Multimodal Large Language Model (MLLM) adept at concurrently processing and analyzing modalities of image, video, audio, and text, while delivering an advanced multimodal interactive experience and strong performance. We propose an effective multimodal training schema starting with 7B model and proceeding through two stages of multimodal alignment and multitask fine-tuning across audio, image, video, and text modal. This approach equips the language model with the ability to handle visual and audio data effectively. Demonstrating strong performance across various omni-modal and multimodal benchmarks, we aim for this contribution to serve as a competitive baseline for the open-source community in advancing multimodal understanding and real-time interaction.
A Rationale-centric Counterfactual Data Augmentation Method for Cross-Document Event Coreference Resolution
Apr 02, 2024



Based on Pre-trained Language Models (PLMs), event coreference resolution (ECR) systems have demonstrated outstanding performance in clustering coreferential events across documents. However, the existing system exhibits an excessive reliance on the `triggers lexical matching' spurious pattern in the input mention pair text. We formalize the decision-making process of the baseline ECR system using a Structural Causal Model (SCM), aiming to identify spurious and causal associations (i.e., rationales) within the ECR task. Leveraging the debiasing capability of counterfactual data augmentation, we develop a rationale-centric counterfactual data augmentation method with LLM-in-the-loop. This method is specialized for pairwise input in the ECR system, where we conduct direct interventions on triggers and context to mitigate the spurious association while emphasizing the causation. Our approach achieves state-of-the-art performance on three popular cross-document ECR benchmarks and demonstrates robustness in out-of-domain scenarios.
Generalizable Whole Slide Image Classification with Fine-Grained Visual-Semantic Interaction
Feb 29, 2024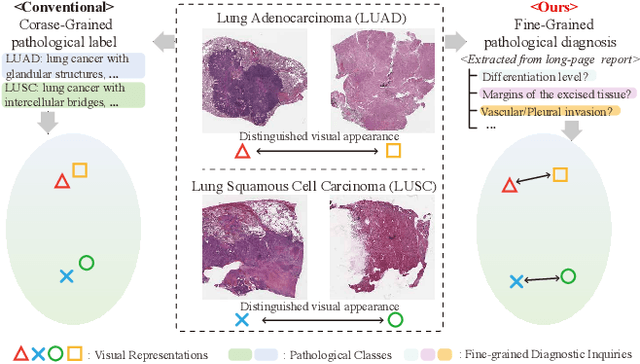

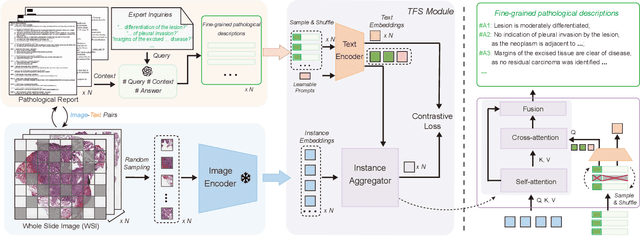
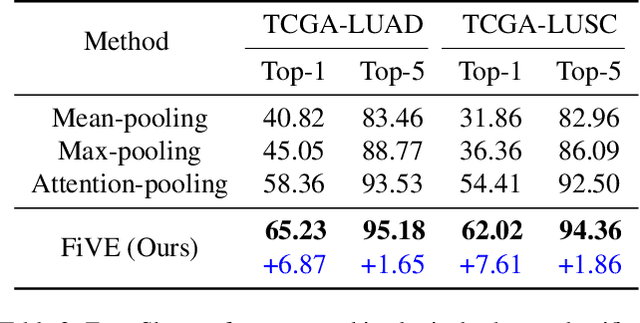
Whole Slide Image (WSI) classification is often formulated as a Multiple Instance Learning (MIL) problem. Recently, Vision-Language Models (VLMs) have demonstrated remarkable performance in WSI classification. However, existing methods leverage coarse-grained pathogenetic descriptions for visual representation supervision, which are insufficient to capture the complex visual appearance of pathogenetic images, hindering the generalizability of models on diverse downstream tasks. Additionally, processing high-resolution WSIs can be computationally expensive. In this paper, we propose a novel "Fine-grained Visual-Semantic Interaction" (FiVE) framework for WSI classification. It is designed to enhance the model's generalizability by leveraging the interplay between localized visual patterns and fine-grained pathological semantics. Specifically, with meticulously designed queries, we start by utilizing a large language model to extract fine-grained pathological descriptions from various non-standardized raw reports. The output descriptions are then reconstructed into fine-grained labels used for training. By introducing a Task-specific Fine-grained Semantics (TFS) module, we enable prompts to capture crucial visual information in WSIs, which enhances representation learning and augments generalization capabilities significantly. Furthermore, given that pathological visual patterns are redundantly distributed across tissue slices, we sample a subset of visual instances during training. Our method demonstrates robust generalizability and strong transferability, dominantly outperforming the counterparts on the TCGA Lung Cancer dataset with at least 9.19% higher accuracy in few-shot experiments.
YOLO-OB: An improved anchor-free real-time multiscale colon polyp detector in colonoscopy
Dec 14, 2023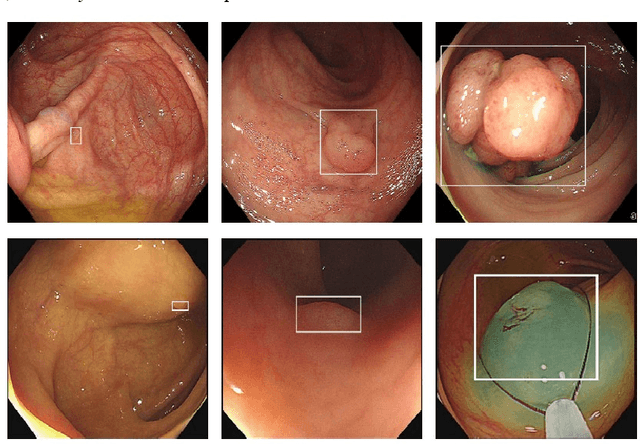



Colon cancer is expected to become the second leading cause of cancer death in the United States in 2023. Although colonoscopy is one of the most effective methods for early prevention of colon cancer, up to 30% of polyps may be missed by endoscopists, thereby increasing patients' risk of developing colon cancer. Though deep neural networks have been proven to be an effective means of enhancing the detection rate of polyps. However, the variation of polyp size brings the following problems: (1) it is difficult to design an efficient and sufficient multi-scale feature fusion structure; (2) matching polyps of different sizes with fixed-size anchor boxes is a hard challenge. These problems reduce the performance of polyp detection and also lower the model's training and detection efficiency. To address these challenges, this paper proposes a new model called YOLO-OB. Specifically, we developed a bidirectional multiscale feature fusion structure, BiSPFPN, which could enhance the feature fusion capability across different depths of a CNN. We employed the ObjectBox detection head, which used a center-based anchor-free box regression strategy that could detect polyps of different sizes on feature maps of any scale. Experiments on the public dataset SUN and the self-collected colon polyp dataset Union demonstrated that the proposed model significantly improved various performance metrics of polyp detection, especially the recall rate. Compared to the state-of-the-art results on the public dataset SUN, the proposed method achieved a 6.73% increase on recall rate from 91.5% to 98.23%. Furthermore, our YOLO-OB was able to achieve real-time polyp detection at a speed of 39 frames per second using a RTX3090 graphics card. The implementation of this paper can be found here: https://github.com/seanyan62/YOLO-OB.
Evaluating Open Question Answering Evaluation
May 21, 2023This study focuses on the evaluation of Open Question Answering (Open-QA) tasks, which have become vital in the realm of artificial intelligence. Current automatic evaluation methods have shown limitations, indicating that human evaluation still remains the most reliable approach. We introduce a new task, QA Evaluation (QA-Eval), designed to assess the accuracy of AI-generated answers in relation to standard answers within Open-QA. Our evaluation of these methods utilizes human-annotated results, and we employ accuracy and F1 score to measure their performance. Specifically, the work investigates methods that show high correlation with human evaluations, deeming them more reliable. We also discuss the pitfalls of current methods, such as their inability to accurately judge responses that contain excessive information. The dataset generated from this work is expected to facilitate the development of more effective automatic evaluation tools. We believe this new QA-Eval task and corresponding dataset will prove valuable for future research in this area.