 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Use of Lemmas via Eligibility Reasoning and Section$-$Aware Reinforcement Learning
Feb 01, 2026Recent large language models (LLMs) perform strongly on mathematical benchmarks yet often misapply lemmas, importing conclusions without validating assumptions. We formalize lemma$-$judging as a structured prediction task: given a statement and a candidate lemma, the model must output a precondition check and a conclusion$-$utility check, from which a usefulness decision is derived. We present RULES, which encodes this specification via a two$-$section output and trains with reinforcement learning plus section$-$aware loss masking to assign penalty to the section responsible for errors. Training and evaluation draw on diverse natural language and formal proof corpora; robustness is assessed with a held$-$out perturbation suite; and end$-$to$-$end evaluation spans competition$-$style, perturbation$-$aligned, and theorem$-$based problems across various LLMs. Results show consistent in$-$domain gains over both a vanilla model and a single$-$label RL baseline, larger improvements on applicability$-$breaking perturbations, and parity or modest gains on end$-$to$-$end tasks; ablations indicate that the two$-$section outputs and section$-$aware reinforcement are both necessary for robustness.
CORE: Concept-Oriented Reinforcement for Bridging the Definition-Application Gap in Mathematical Reasoning
Dec 21, 2025

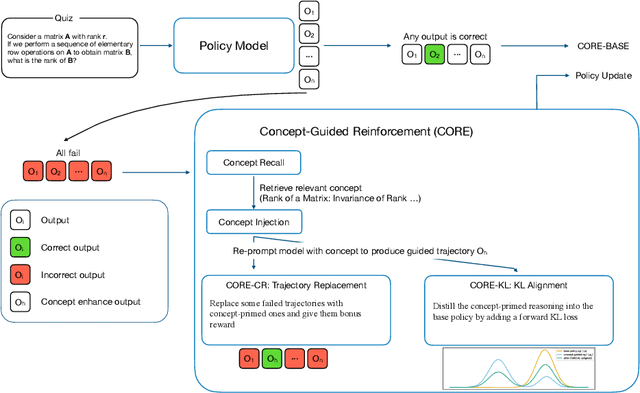
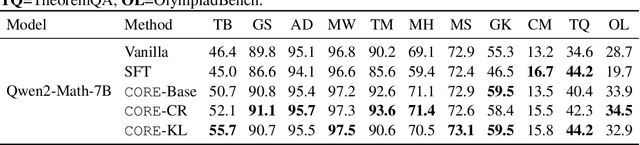
Large language models (LLMs) often solve challenging math exercises yet fail to apply the concept right when the problem requires genuine understanding. Popular Reinforcement Learning with Verifiable Rewards (RLVR) pipelines reinforce final answers but provide little fine-grained conceptual signal, so models improve at pattern reuse rather than conceptual applications. We introduce CORE (Concept-Oriented REinforcement), an RL training framework that turns explicit concepts into a controllable supervision signal. Starting from a high-quality, low-contamination textbook resource that links verifiable exercises to concise concept descriptions, we run a sanity probe showing LLMs can restate definitions but fail concept-linked quizzes, quantifying the conceptual reasoning gap. CORE then (i) synthesizes concept-aligned quizzes, (ii) injects brief concept snippets during rollouts to elicit concept-primed trajectories, and (iii) reinforces conceptual reasoning via trajectory replacement after group failures, a lightweight forward-KL constraint that aligns unguided with concept-primed policies, or standard GRPO directly on concept-aligned quizzes. Across several models, CORE delivers consistent gains over vanilla and SFT baselines on both in-domain concept-exercise suites and diverse out-of-domain math benchmarks. CORE unifies direct training on concept-aligned quizzes and concept-injected rollouts under outcome regularization. It provides fine-grained conceptual supervision that bridges problem-solving competence and genuine conceptual reasoning, while remaining algorithm- and verifier-agnostic.
Unbiased Visual Reasoning with Controlled Visual Inputs
Dec 19, 2025End-to-end Vision-language Models (VLMs) often answer visual questions by exploiting spurious correlations instead of causal visual evidence, and can become more shortcut-prone when fine-tuned. We introduce VISTA (Visual-Information Separation for Text-based Analysis), a modular framework that decouples perception from reasoning via an explicit information bottleneck. A frozen VLM sensor is restricted to short, objective perception queries, while a text-only LLM reasoner decomposes each question, plans queries, and aggregates visual facts in natural language. This controlled interface defines a reward-aligned environment for training unbiased visual reasoning with reinforcement learning. Instantiated with Qwen2.5-VL and Llama3.2-Vision sensors, and trained with GRPO from only 641 curated multi-step questions, VISTA significantly improves robustness to real-world spurious correlations on SpuriVerse (+16.29% with Qwen-2.5-VL-7B and +6.77% with Llama-3.2-Vision-11B), while remaining competitive on MMVP and a balanced SeedBench subset. VISTA transfers robustly across unseen VLM sensors and is able to recognize and recover from VLM perception failures. Human analysis further shows that VISTA's reasoning traces are more neutral, less reliant on spurious attributes, and more explicitly grounded in visual evidence than end-to-end VLM baselines.
CC-LEARN: Cohort-based Consistency Learning
Jun 18, 2025Large language models excel at many tasks but still struggle with consistent, robust reasoning. We introduce Cohort-based Consistency Learning (CC-Learn), a reinforcement learning framework that improves the reliability of LLM reasoning by training on cohorts of similar questions derived from shared programmatic abstractions. To enforce cohort-level consistency, we define a composite objective combining cohort accuracy, a retrieval bonus for effective problem decomposition, and a rejection penalty for trivial or invalid lookups that reinforcement learning can directly optimize, unlike supervised fine-tuning. Optimizing this reward guides the model to adopt uniform reasoning patterns across all cohort members. Experiments on challenging reasoning benchmarks (including ARC-Challenge and StrategyQA) show that CC-Learn boosts both accuracy and reasoning stability over pretrained and SFT baselines. These results demonstrate that cohort-level RL effectively enhances reasoning consistency in LLMs.
BOW: Bottlenecked Next Word Exploration
Jun 16, 2025Large language models (LLMs) are typically trained via next-word prediction (NWP), which provides strong surface-level fluency but often lacks support for robust reasoning. We propose BOttlenecked next Word exploration (BOW), a novel RL framework that rethinks NWP by introducing a reasoning bottleneck where a policy model first generates a reasoning path rather than predicting the next token directly, after which a frozen judge model predicts the next token distribution based solely on this reasoning path. We train the policy model using GRPO with rewards that quantify how effectively the reasoning path facilitates next-word recovery. Compared with other continual pretraining baselines, we show that BOW improves both the general and next-word reasoning capabilities of the base model, evaluated on various benchmarks. Our findings show that BOW can serve as an effective and scalable alternative to vanilla NWP.
QA-LIGN: Aligning LLMs through Constitutionally Decomposed QA
Jun 09, 2025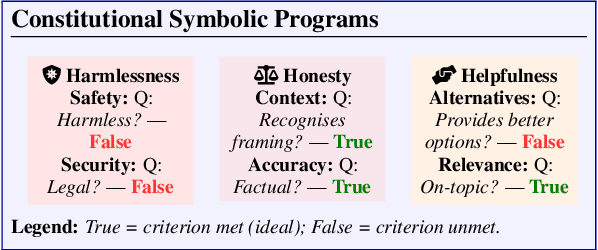
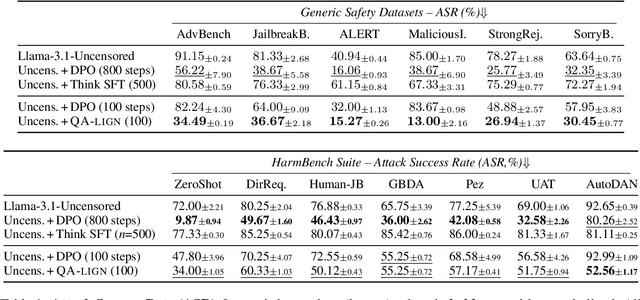
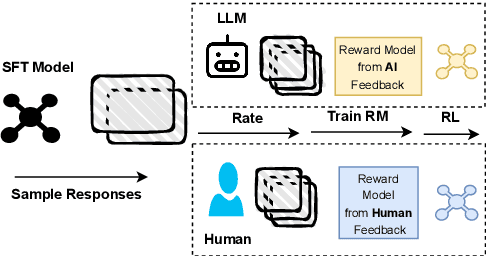

Alignment of large language models with explicit principles (such as helpfulness, honesty, and harmlessness) is crucial for ensuring safe and reliable AI systems. However, standard reward-based alignment methods typically collapse diverse feedback into a single scalar reward, entangling multiple objectives into one opaque training signal, which hinders interpretability. In this work, we introduce QA-LIGN, an automatic symbolic reward decomposition approach that preserves the structure of each constitutional principle within the reward mechanism. Instead of training a black-box reward model that outputs a monolithic score, QA-LIGN formulates principle-specific evaluation questions and derives separate reward components for each principle, making it a drop-in reward model replacement. Experiments aligning an uncensored large language model with a set of constitutional principles demonstrate that QA-LIGN offers greater transparency and adaptability in the alignment process. At the same time, our approach achieves performance on par with or better than a DPO baseline. Overall, these results represent a step toward more interpretable and controllable alignment of language models, achieved without sacrificing end-task performance.
ToW: Thoughts of Words Improve Reasoning in Large Language Models
Oct 21, 2024

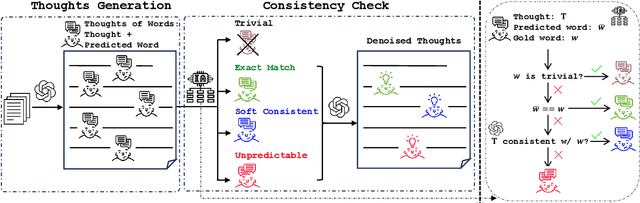
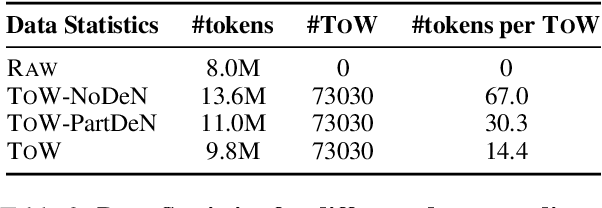
We introduce thoughts of words (ToW), a novel training-time data-augmentation method for next-word prediction. ToW views next-word prediction as a core reasoning task and injects fine-grained thoughts explaining what the next word should be and how it is related to the previous contexts in pre-training texts. Our formulation addresses two fundamental drawbacks of existing next-word prediction learning schemes: they induce factual hallucination and are inefficient for models to learn the implicit reasoning processes in raw texts. While there are many ways to acquire such thoughts of words, we explore the first step of acquiring ToW annotations through distilling from larger models. After continual pre-training with only 70K ToW annotations, we effectively improve models' reasoning performances by 7% to 9% on average and reduce model hallucination by up to 10%. At the same time, ToW is entirely agnostic to tasks and applications, introducing no additional biases on labels or semantics.
Let LLMs Take on the Latest Challenges! A Chinese Dynamic Question Answering Benchmark
Mar 02, 2024

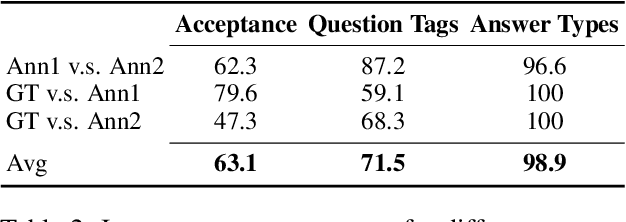
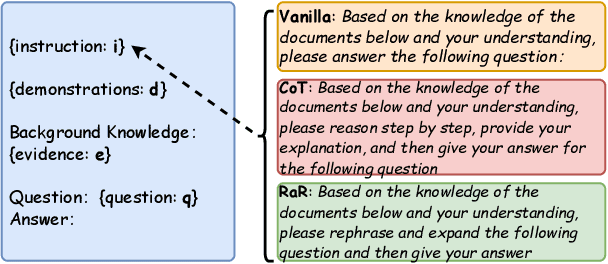
How to better evaluate the capabilities of Large Language Models (LLMs) is the focal point and hot topic in current LLMs research. Previous work has noted that due to the extremely high cost of iterative updates of LLMs, they are often unable to answer the latest dynamic questions well. To promote the improvement of Chinese LLMs' ability to answer dynamic questions, in this paper, we introduce CDQA, a Chinese Dynamic QA benchmark containing question-answer pairs related to the latest news on the Chinese Internet. We obtain high-quality data through a pipeline that combines humans and models, and carefully classify the samples according to the frequency of answer changes to facilitate a more fine-grained observation of LLMs' capabilities. We have also evaluated and analyzed mainstream and advanced Chinese LLMs on CDQA. Extensive experiments and valuable insights suggest that our proposed CDQA is challenging and worthy of more further study. We believe that the benchmark we provide will become one of the key data resources for improving LLMs' Chinese question-answering ability in the future.
Exploiting Abstract Meaning Representation for Open-Domain Question Answering
May 26, 2023The Open-Domain Question Answering (ODQA) task involves retrieving and subsequently generating answers from fine-grained relevant passages within a database. Current systems leverage Pretrained Language Models (PLMs) to model the relationship between questions and passages. However, the diversity in surface form expressions can hinder the model's ability to capture accurate correlations, especially within complex contexts. Therefore, we utilize Abstract Meaning Representation (AMR) graphs to assist the model in understanding complex semantic information. We introduce a method known as Graph-as-Token (GST) to incorporate AMRs into PLMs. Results from Natural Questions (NQ) and TriviaQA (TQ) demonstrate that our GST method can significantly improve performance, resulting in up to 2.44/3.17 Exact Match score improvements on NQ/TQ respectively. Furthermore, our method enhances robustness and outperforms alternative Graph Neural Network (GNN) methods for integrating AMRs. To the best of our knowledge, we are the first to employ semantic graphs in ODQA.
Evaluating Open Question Answering Evaluation
May 21, 2023This study focuses on the evaluation of Open Question Answering (Open-QA) tasks, which have become vital in the realm of artificial intelligence. Current automatic evaluation methods have shown limitations, indicating that human evaluation still remains the most reliable approach. We introduce a new task, QA Evaluation (QA-Eval), designed to assess the accuracy of AI-generated answers in relation to standard answers within Open-QA. Our evaluation of these methods utilizes human-annotated results, and we employ accuracy and F1 score to measure their performance. Specifically, the work investigates methods that show high correlation with human evaluations, deeming them more reliable. We also discuss the pitfalls of current methods, such as their inability to accurately judge responses that contain excessive information. The dataset generated from this work is expected to facilitate the development of more effective automatic evaluation tools. We believe this new QA-Eval task and corresponding dataset will prove valuable for future research in this area.