 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Visual Reasoning with Controlled Visual Inputs
Dec 19, 2025End-to-end Vision-language Models (VLMs) often answer visual questions by exploiting spurious correlations instead of causal visual evidence, and can become more shortcut-prone when fine-tuned. We introduce VISTA (Visual-Information Separation for Text-based Analysis), a modular framework that decouples perception from reasoning via an explicit information bottleneck. A frozen VLM sensor is restricted to short, objective perception queries, while a text-only LLM reasoner decomposes each question, plans queries, and aggregates visual facts in natural language. This controlled interface defines a reward-aligned environment for training unbiased visual reasoning with reinforcement learning. Instantiated with Qwen2.5-VL and Llama3.2-Vision sensors, and trained with GRPO from only 641 curated multi-step questions, VISTA significantly improves robustness to real-world spurious correlations on SpuriVerse (+16.29% with Qwen-2.5-VL-7B and +6.77% with Llama-3.2-Vision-11B), while remaining competitive on MMVP and a balanced SeedBench subset. VISTA transfers robustly across unseen VLM sensors and is able to recognize and recover from VLM perception failures. Human analysis further shows that VISTA's reasoning traces are more neutral, less reliant on spurious attributes, and more explicitly grounded in visual evidence than end-to-end VLM baselines.
ArenaBencher: Automatic Benchmark Evolution via Multi-Model Competitive Evaluation
Oct 09, 2025
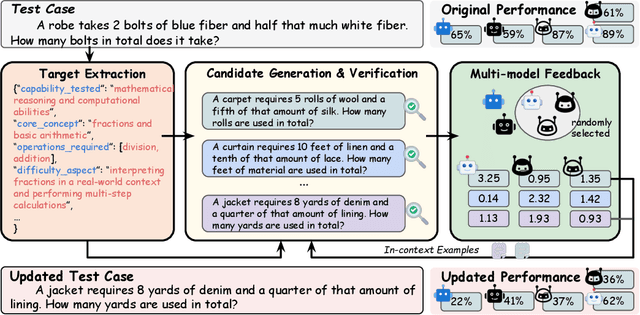
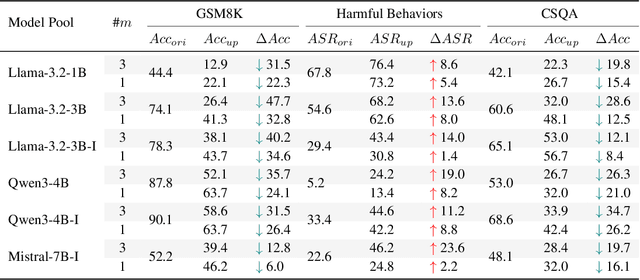
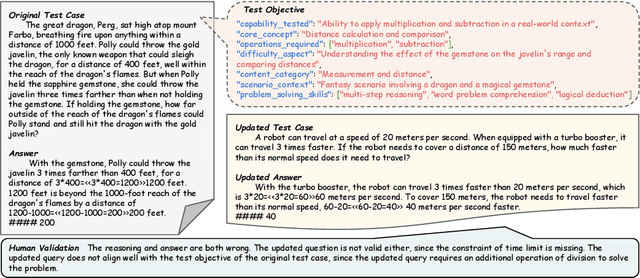
Benchmarks are central to measuring the capabilities of large language models and guiding model development, yet widespread data leakage from pretraining corpora undermines their validity. Models can match memorized content rather than demonstrate true generalization, which inflates scores, distorts cross-model comparisons, and misrepresents progress. We introduce ArenaBencher, a model-agnostic framework for automatic benchmark evolution that updates test cases while preserving comparability. Given an existing benchmark and a diverse pool of models to be evaluated, ArenaBencher infers the core ability of each test case, generates candidate question-answer pairs that preserve the original objective, verifies correctness and intent with an LLM as a judge, and aggregates feedback from multiple models to select candidates that expose shared weaknesses. The process runs iteratively with in-context demonstrations that steer generation toward more challenging and diagnostic cases. We apply ArenaBencher to math problem solving, commonsense reasoning, and safety domains and show that it produces verified, diverse, and fair updates that uncover new failure modes, increase difficulty while preserving test objective alignment, and improve model separability. The framework provides a scalable path to continuously evolve benchmarks in step with the rapid progress of foundation models.
ThinkTuning: Instilling Cognitive Reflections without Distillation
Aug 11, 2025
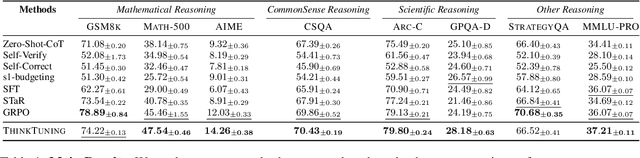
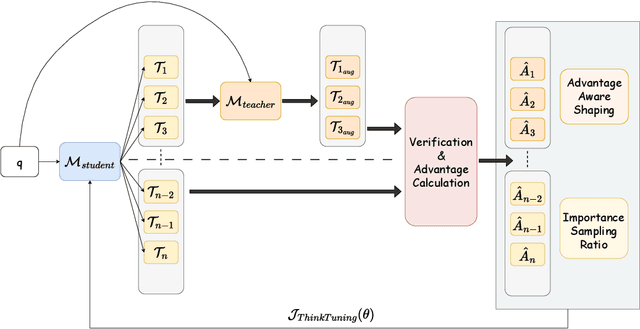
Recent advances in test-time scaling have led to the emergence of thinking LLMs that exhibit self-reflective behaviors and multi-step reasoning. While RL drives this self-improvement paradigm, a recent study (Gandhi et al., 2025) shows that RL alone does not truly instill these new reasoning abilities - it merely draws out behaviors already present in the base models. This raises a question: How can we train the models that don't exhibit such thinking behavior to develop it in the first place? To this end, we propose ThinkTuning, a GRPO-based interactive training approach where we augment the rollouts of a student model with the guidance from a teacher model. A simple idea from classroom practice inspires our method: a teacher poses a problem, lets the student try an answer, then gives corrective feedback -- enough to point the mind in the right direction and then show the solution. Each piece of feedback reshapes the student's thoughts, leading them to arrive at the correct solution. Similarly, we find that this type of implicit supervision through feedback from a teacher model of the same size improves the reasoning capabilities of the student model. In particular, on average, our method shows a 3.85% improvement over zero-shot baselines across benchmarks, and on MATH-500, AIME and GPQA-Diamond it shows 2.08%, 2.23% and 3.99% improvements over the vanilla-GRPO baseline. Source code is available at https://github.com/3rdAT/ThinkTuning.
CC-LEARN: Cohort-based Consistency Learning
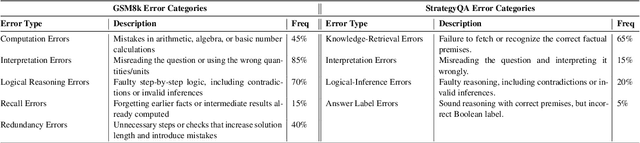
Jun 18, 2025Large language models excel at many tasks but still struggle with consistent, robust reasoning. We introduce Cohort-based Consistency Learning (CC-Learn), a reinforcement learning framework that improves the reliability of LLM reasoning by training on cohorts of similar questions derived from shared programmatic abstractions. To enforce cohort-level consistency, we define a composite objective combining cohort accuracy, a retrieval bonus for effective problem decomposition, and a rejection penalty for trivial or invalid lookups that reinforcement learning can directly optimize, unlike supervised fine-tuning. Optimizing this reward guides the model to adopt uniform reasoning patterns across all cohort members. Experiments on challenging reasoning benchmarks (including ARC-Challenge and StrategyQA) show that CC-Learn boosts both accuracy and reasoning stability over pretrained and SFT baselines. These results demonstrate that cohort-level RL effectively enhances reasoning consistency in LLMs.
BOW: Bottlenecked Next Word Exploration
Jun 16, 2025Large language models (LLMs) are typically trained via next-word prediction (NWP), which provides strong surface-level fluency but often lacks support for robust reasoning. We propose BOttlenecked next Word exploration (BOW), a novel RL framework that rethinks NWP by introducing a reasoning bottleneck where a policy model first generates a reasoning path rather than predicting the next token directly, after which a frozen judge model predicts the next token distribution based solely on this reasoning path. We train the policy model using GRPO with rewards that quantify how effectively the reasoning path facilitates next-word recovery. Compared with other continual pretraining baselines, we show that BOW improves both the general and next-word reasoning capabilities of the base model, evaluated on various benchmarks. Our findings show that BOW can serve as an effective and scalable alternative to vanilla NWP.
QA-LIGN: Aligning LLMs through Constitutionally Decomposed QA
Jun 09, 2025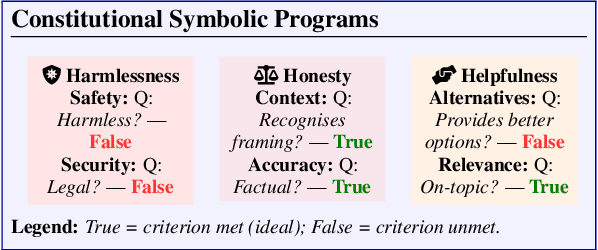
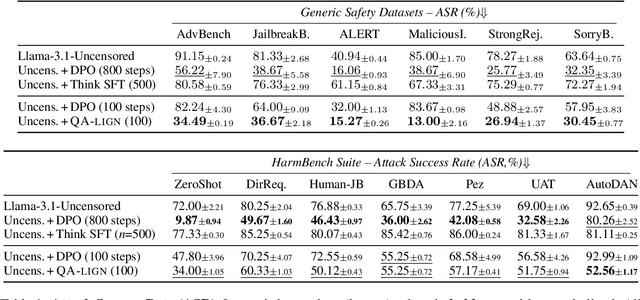
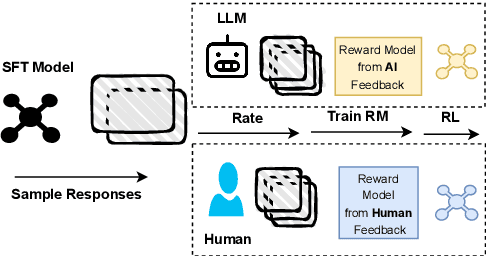

Alignment of large language models with explicit principles (such as helpfulness, honesty, and harmlessness) is crucial for ensuring safe and reliable AI systems. However, standard reward-based alignment methods typically collapse diverse feedback into a single scalar reward, entangling multiple objectives into one opaque training signal, which hinders interpretability. In this work, we introduce QA-LIGN, an automatic symbolic reward decomposition approach that preserves the structure of each constitutional principle within the reward mechanism. Instead of training a black-box reward model that outputs a monolithic score, QA-LIGN formulates principle-specific evaluation questions and derives separate reward components for each principle, making it a drop-in reward model replacement. Experiments aligning an uncensored large language model with a set of constitutional principles demonstrate that QA-LIGN offers greater transparency and adaptability in the alignment process. At the same time, our approach achieves performance on par with or better than a DPO baseline. Overall, these results represent a step toward more interpretable and controllable alignment of language models, achieved without sacrificing end-task performance.
ToW: Thoughts of Words Improve Reasoning in Large Language Models
Oct 21, 2024

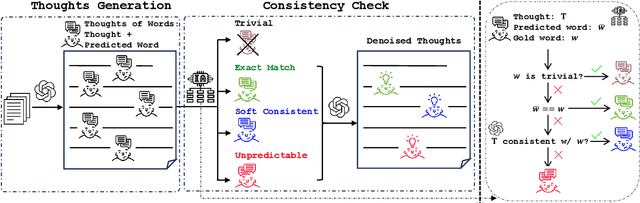
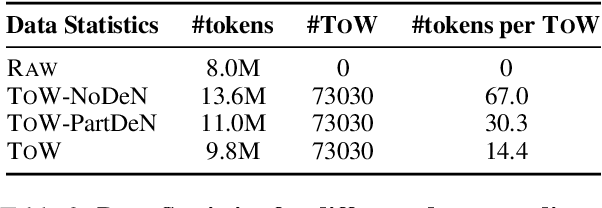
We introduce thoughts of words (ToW), a novel training-time data-augmentation method for next-word prediction. ToW views next-word prediction as a core reasoning task and injects fine-grained thoughts explaining what the next word should be and how it is related to the previous contexts in pre-training texts. Our formulation addresses two fundamental drawbacks of existing next-word prediction learning schemes: they induce factual hallucination and are inefficient for models to learn the implicit reasoning processes in raw texts. While there are many ways to acquire such thoughts of words, we explore the first step of acquiring ToW annotations through distilling from larger models. After continual pre-training with only 70K ToW annotations, we effectively improve models' reasoning performances by 7% to 9% on average and reduce model hallucination by up to 10%. At the same time, ToW is entirely agnostic to tasks and applications, introducing no additional biases on labels or semantics.
Model Interpretation and Explainability: Towards Creating Transparency in Prediction Models
May 31, 2024Explainable AI (XAI) has a counterpart in analytical modeling which we refer to as model explainability. We tackle the issue of model explainability in the context of prediction models. We analyze a dataset of loans from a credit card company and apply three stages: execute and compare four different prediction methods, apply the best known explainability techniques in the current literature to the model training sets to identify feature importance (FI) (static case), and finally to cross-check whether the FI set holds up under what if prediction scenarios for continuous and categorical variables (dynamic case). We found inconsistency in FI identification between the static and dynamic cases. We summarize the state of the art in model explainability and suggest further research to advance the field.
Unified Explanations in Machine Learning Models: A Perturbation Approach
May 30, 2024


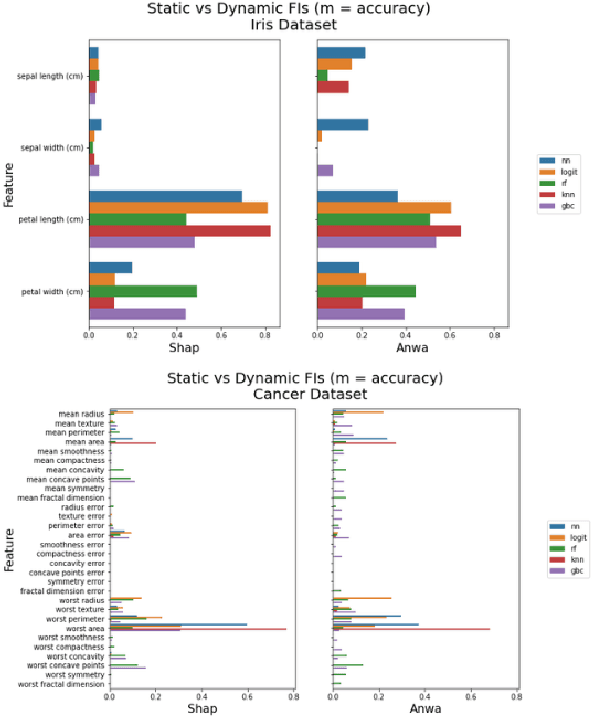
A high-velocity paradigm shift towards Explainable Artificial Intelligence (XAI) has emerged in recent years. Highly complex Machine Learning (ML) models have flourished in many tasks of intelligence, and the questions have started to shift away from traditional metrics of validity towards something deeper: What is this model telling me about my data, and how is it arriving at these conclusions? Inconsistencies between XAI and modeling techniques can have the undesirable effect of casting doubt upon the efficacy of these explainability approaches. To address these problems, we propose a systematic, perturbation-based analysis against a popular, model-agnostic method in XAI, SHapley Additive exPlanations (Shap). We devise algorithms to generate relative feature importance in settings of dynamic inference amongst a suite of popular machine learning and deep learning methods, and metrics that allow us to quantify how well explanations generated under the static case hold. We propose a taxonomy for feature importance methodology, measure alignment, and observe quantifiable similarity amongst explanation models across several datasets.
Reinforcement Learning For Data Poisoning on Graph Neural Networks
Feb 12, 2021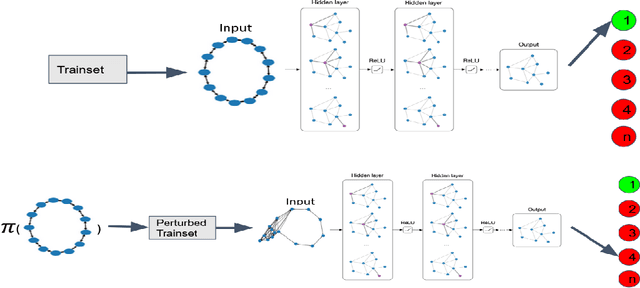
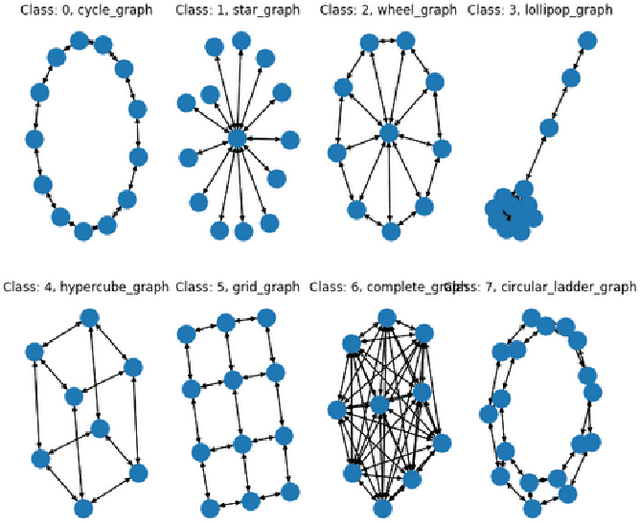

Adversarial Machine Learning has emerged as a substantial subfield of Computer Science due to a lack of robustness in the models we train along with crowdsourcing practices that enable attackers to tamper with data. In the last two years, interest has surged in adversarial attacks on graphs yet the Graph Classification setting remains nearly untouched. Since a Graph Classification dataset consists of discrete graphs with class labels, related work has forgone direct gradient optimization in favor of an indirect Reinforcement Learning approach. We will study the novel problem of Data Poisoning (training time) attack on Neural Networks for Graph Classification using Reinforcement Learning Agents.