 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocabulary Dropout for Curriculum Diversity in LLM Co-Evolution
Apr 03, 2026Co-evolutionary self-play, where one language model generates problems and another solves them, promises autonomous curriculum learning without human supervision. In practice, the proposer quickly converges to a narrow distribution of problems that satisfy the reward function. This diversity collapse renders the curriculum uninformative for the solver, stalling the co-evolutionary loop. We introduce vocabulary dropout, a random mask applied to the proposer's output logits during both policy training and curriculum generation, as a lightweight mechanism to sustain diversity. The mask is hard and non-stationary, preventing the proposer from locking into fixed token sequences. Training Qwen3-4B and Qwen3-8B on mathematical reasoning via R-Zero, we find that vocabulary dropout sustains proposer diversity across lexical, semantic, and functional metrics throughout training, and yields solver improvements averaging +4.4 points at 8B, with the largest gains on competition-level benchmarks. Our findings suggest that explicit action-space constraints, analogous to the structural role that game rules play in classical self-play, can help sustain productive co-evolution in language. Vocabulary dropout is one simple instantiation of this principle.
Reliable Use of Lemmas via Eligibility Reasoning and Section$-$Aware Reinforcement Learning
Feb 01, 2026Recent large language models (LLMs) perform strongly on mathematical benchmarks yet often misapply lemmas, importing conclusions without validating assumptions. We formalize lemma$-$judging as a structured prediction task: given a statement and a candidate lemma, the model must output a precondition check and a conclusion$-$utility check, from which a usefulness decision is derived. We present RULES, which encodes this specification via a two$-$section output and trains with reinforcement learning plus section$-$aware loss masking to assign penalty to the section responsible for errors. Training and evaluation draw on diverse natural language and formal proof corpora; robustness is assessed with a held$-$out perturbation suite; and end$-$to$-$end evaluation spans competition$-$style, perturbation$-$aligned, and theorem$-$based problems across various LLMs. Results show consistent in$-$domain gains over both a vanilla model and a single$-$label RL baseline, larger improvements on applicability$-$breaking perturbations, and parity or modest gains on end$-$to$-$end tasks; ablations indicate that the two$-$section outputs and section$-$aware reinforcement are both necessary for robustness.
CORE: Concept-Oriented Reinforcement for Bridging the Definition-Application Gap in Mathematical Reasoning
Dec 21, 2025

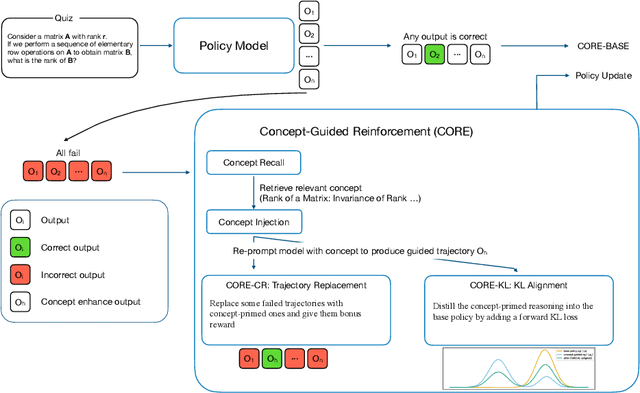
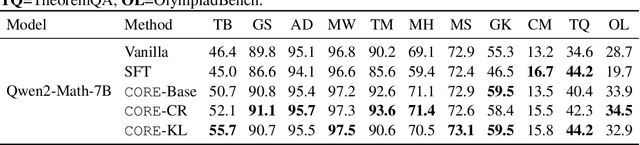
Large language models (LLMs) often solve challenging math exercises yet fail to apply the concept right when the problem requires genuine understanding. Popular Reinforcement Learning with Verifiable Rewards (RLVR) pipelines reinforce final answers but provide little fine-grained conceptual signal, so models improve at pattern reuse rather than conceptual applications. We introduce CORE (Concept-Oriented REinforcement), an RL training framework that turns explicit concepts into a controllable supervision signal. Starting from a high-quality, low-contamination textbook resource that links verifiable exercises to concise concept descriptions, we run a sanity probe showing LLMs can restate definitions but fail concept-linked quizzes, quantifying the conceptual reasoning gap. CORE then (i) synthesizes concept-aligned quizzes, (ii) injects brief concept snippets during rollouts to elicit concept-primed trajectories, and (iii) reinforces conceptual reasoning via trajectory replacement after group failures, a lightweight forward-KL constraint that aligns unguided with concept-primed policies, or standard GRPO directly on concept-aligned quizzes. Across several models, CORE delivers consistent gains over vanilla and SFT baselines on both in-domain concept-exercise suites and diverse out-of-domain math benchmarks. CORE unifies direct training on concept-aligned quizzes and concept-injected rollouts under outcome regularization. It provides fine-grained conceptual supervision that bridges problem-solving competence and genuine conceptual reasoning, while remaining algorithm- and verifier-agnostic.
Unbiased Visual Reasoning with Controlled Visual Inputs
Dec 19, 2025End-to-end Vision-language Models (VLMs) often answer visual questions by exploiting spurious correlations instead of causal visual evidence, and can become more shortcut-prone when fine-tuned. We introduce VISTA (Visual-Information Separation for Text-based Analysis), a modular framework that decouples perception from reasoning via an explicit information bottleneck. A frozen VLM sensor is restricted to short, objective perception queries, while a text-only LLM reasoner decomposes each question, plans queries, and aggregates visual facts in natural language. This controlled interface defines a reward-aligned environment for training unbiased visual reasoning with reinforcement learning. Instantiated with Qwen2.5-VL and Llama3.2-Vision sensors, and trained with GRPO from only 641 curated multi-step questions, VISTA significantly improves robustness to real-world spurious correlations on SpuriVerse (+16.29% with Qwen-2.5-VL-7B and +6.77% with Llama-3.2-Vision-11B), while remaining competitive on MMVP and a balanced SeedBench subset. VISTA transfers robustly across unseen VLM sensors and is able to recognize and recover from VLM perception failures. Human analysis further shows that VISTA's reasoning traces are more neutral, less reliant on spurious attributes, and more explicitly grounded in visual evidence than end-to-end VLM baselines.
ArenaBencher: Automatic Benchmark Evolution via Multi-Model Competitive Evaluation
Oct 09, 2025
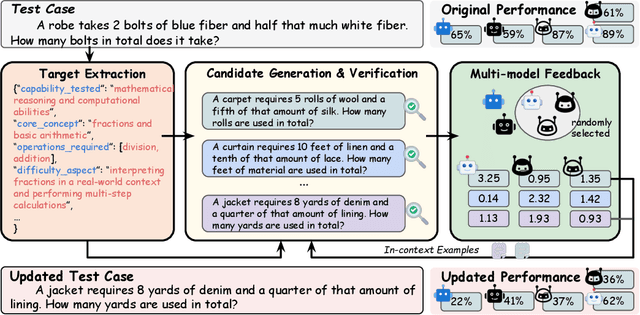
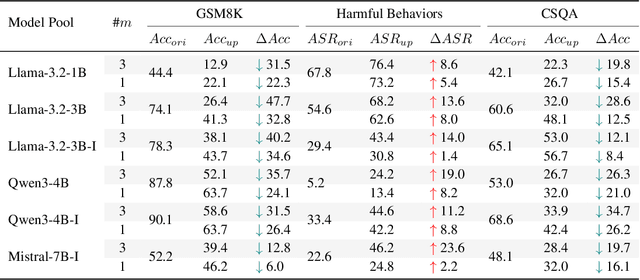
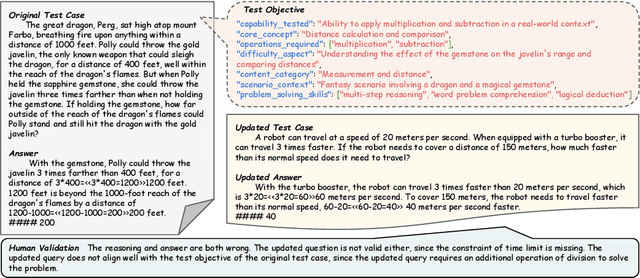
Benchmarks are central to measuring the capabilities of large language models and guiding model development, yet widespread data leakage from pretraining corpora undermines their validity. Models can match memorized content rather than demonstrate true generalization, which inflates scores, distorts cross-model comparisons, and misrepresents progress. We introduce ArenaBencher, a model-agnostic framework for automatic benchmark evolution that updates test cases while preserving comparability. Given an existing benchmark and a diverse pool of models to be evaluated, ArenaBencher infers the core ability of each test case, generates candidate question-answer pairs that preserve the original objective, verifies correctness and intent with an LLM as a judge, and aggregates feedback from multiple models to select candidates that expose shared weaknesses. The process runs iteratively with in-context demonstrations that steer generation toward more challenging and diagnostic cases. We apply ArenaBencher to math problem solving, commonsense reasoning, and safety domains and show that it produces verified, diverse, and fair updates that uncover new failure modes, increase difficulty while preserving test objective alignment, and improve model separability. The framework provides a scalable path to continuously evolve benchmarks in step with the rapid progress of foundation models.
ThinkTuning: Instilling Cognitive Reflections without Distillation
Aug 11, 2025
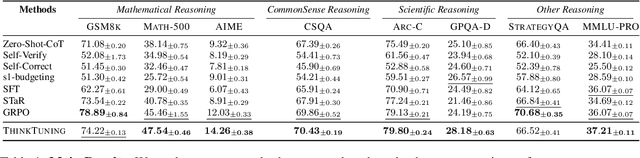
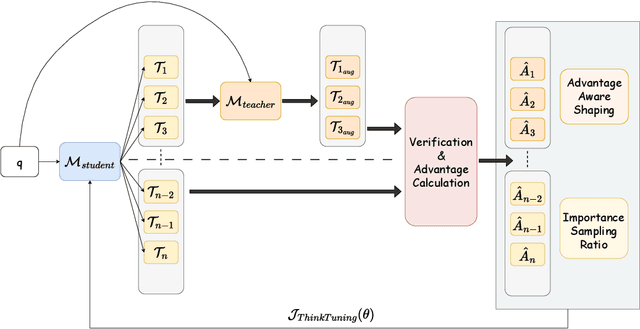
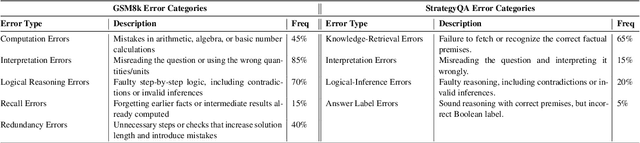
Recent advances in test-time scaling have led to the emergence of thinking LLMs that exhibit self-reflective behaviors and multi-step reasoning. While RL drives this self-improvement paradigm, a recent study (Gandhi et al., 2025) shows that RL alone does not truly instill these new reasoning abilities - it merely draws out behaviors already present in the base models. This raises a question: How can we train the models that don't exhibit such thinking behavior to develop it in the first place? To this end, we propose ThinkTuning, a GRPO-based interactive training approach where we augment the rollouts of a student model with the guidance from a teacher model. A simple idea from classroom practice inspires our method: a teacher poses a problem, lets the student try an answer, then gives corrective feedback -- enough to point the mind in the right direction and then show the solution. Each piece of feedback reshapes the student's thoughts, leading them to arrive at the correct solution. Similarly, we find that this type of implicit supervision through feedback from a teacher model of the same size improves the reasoning capabilities of the student model. In particular, on average, our method shows a 3.85% improvement over zero-shot baselines across benchmarks, and on MATH-500, AIME and GPQA-Diamond it shows 2.08%, 2.23% and 3.99% improvements over the vanilla-GRPO baseline. Source code is available at https://github.com/3rdAT/ThinkTuning.
CC-LEARN: Cohort-based Consistency Learning
Jun 18, 2025Large language models excel at many tasks but still struggle with consistent, robust reasoning. We introduce Cohort-based Consistency Learning (CC-Learn), a reinforcement learning framework that improves the reliability of LLM reasoning by training on cohorts of similar questions derived from shared programmatic abstractions. To enforce cohort-level consistency, we define a composite objective combining cohort accuracy, a retrieval bonus for effective problem decomposition, and a rejection penalty for trivial or invalid lookups that reinforcement learning can directly optimize, unlike supervised fine-tuning. Optimizing this reward guides the model to adopt uniform reasoning patterns across all cohort members. Experiments on challenging reasoning benchmarks (including ARC-Challenge and StrategyQA) show that CC-Learn boosts both accuracy and reasoning stability over pretrained and SFT baselines. These results demonstrate that cohort-level RL effectively enhances reasoning consistency in LLMs.
BOW: Bottlenecked Next Word Exploration
Jun 16, 2025Large language models (LLMs) are typically trained via next-word prediction (NWP), which provides strong surface-level fluency but often lacks support for robust reasoning. We propose BOttlenecked next Word exploration (BOW), a novel RL framework that rethinks NWP by introducing a reasoning bottleneck where a policy model first generates a reasoning path rather than predicting the next token directly, after which a frozen judge model predicts the next token distribution based solely on this reasoning path. We train the policy model using GRPO with rewards that quantify how effectively the reasoning path facilitates next-word recovery. Compared with other continual pretraining baselines, we show that BOW improves both the general and next-word reasoning capabilities of the base model, evaluated on various benchmarks. Our findings show that BOW can serve as an effective and scalable alternative to vanilla NWP.
QA-LIGN: Aligning LLMs through Constitutionally Decomposed QA
Jun 09, 2025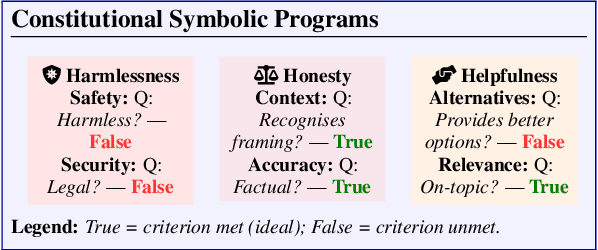
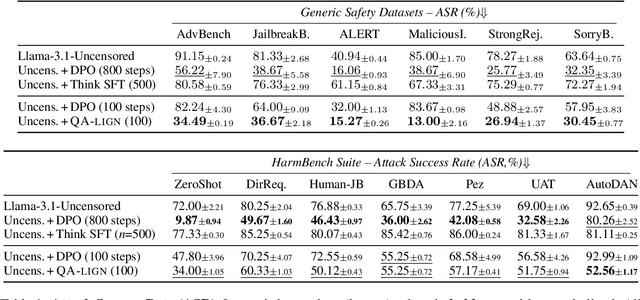
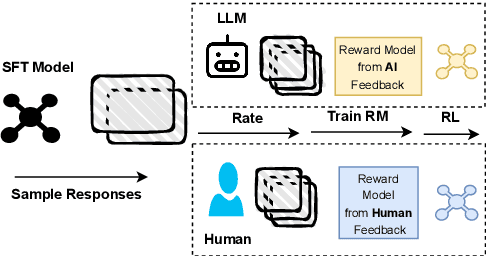

Alignment of large language models with explicit principles (such as helpfulness, honesty, and harmlessness) is crucial for ensuring safe and reliable AI systems. However, standard reward-based alignment methods typically collapse diverse feedback into a single scalar reward, entangling multiple objectives into one opaque training signal, which hinders interpretability. In this work, we introduce QA-LIGN, an automatic symbolic reward decomposition approach that preserves the structure of each constitutional principle within the reward mechanism. Instead of training a black-box reward model that outputs a monolithic score, QA-LIGN formulates principle-specific evaluation questions and derives separate reward components for each principle, making it a drop-in reward model replacement. Experiments aligning an uncensored large language model with a set of constitutional principles demonstrate that QA-LIGN offers greater transparency and adaptability in the alignment process. At the same time, our approach achieves performance on par with or better than a DPO baseline. Overall, these results represent a step toward more interpretable and controllable alignment of language models, achieved without sacrificing end-task performance.
Semantic-Clipping: Efficient Vision-Language Modeling with Semantic-Guidedd Visual Selection
Mar 14, 2025Vision-Language Models (VLMs) leverage aligned visual encoders to transform images into visual tokens, allowing them to be processed similarly to text by the backbone large language model (LLM). This unified input paradigm enables VLMs to excel in vision-language tasks such as visual question answering (VQA). To improve fine-grained visual reasoning, recent advancements in vision-language modeling introduce image cropping techniques that feed all encoded sub-images into the model. However, this approach significantly increases the number of visual tokens, leading to inefficiency and potential distractions for the LLM. To address the generalization challenges of image representation in VLMs, we propose a lightweight, universal framework that seamlessly integrates with existing VLMs to enhance their ability to process finegrained details. Our method leverages textual semantics to identify key visual areas, improving VQA performance without requiring any retraining of the VLM. Additionally, it incorporates textual signals into the visual encoding process, enhancing both efficiency and effectiveness. The proposed method, SEMCLIP, strengthens the visual understanding of a 7B VLM, LLaVA-1.5 by 3.3% on average across 7 benchmarks, and particularly by 5.3% on the challenging detailed understanding benchmark V*.