 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWetland mapping from sparse annotations with satellite image time series and temporal-aware segment anything model
Jan 16, 2026Accurate wetland mapping is essential for ecosystem monitoring, yet dense pixel-level annotation is prohibitively expensive and practical applications usually rely on sparse point labels, under which existing deep learning models perform poorly, while strong seasonal and inter-annual wetland dynamics further render single-date imagery inadequate and lead to significant mapping errors; although foundation models such as SAM show promising generalization from point prompts, they are inherently designed for static images and fail to model temporal information, resulting in fragmented masks in heterogeneous wetlands. To overcome these limitations, we propose WetSAM, a SAM-based framework that integrates satellite image time series for wetland mapping from sparse point supervision through a dual-branch design, where a temporally prompted branch extends SAM with hierarchical adapters and dynamic temporal aggregation to disentangle wetland characteristics from phenological variability, and a spatial branch employs a temporally constrained region-growing strategy to generate reliable dense pseudo-labels, while a bidirectional consistency regularization jointly optimizes both branches. Extensive experiments across eight global regions of approximately 5,000 km2 each demonstrate that WetSAM substantially outperforms state-of-the-art methods, achieving an average F1-score of 85.58%, and delivering accurate and structurally consistent wetland segmentation with minimal labeling effort, highlighting its strong generalization capability and potential for scalable, low-cost, high-resolution wetland mapping.
FRIEDA: Benchmarking Multi-Step Cartographic Reasoning in Vision-Language Models
Dec 08, 2025Cartographic reasoning is the skill of interpreting geographic relationships by aligning legends, map scales, compass directions, map texts, and geometries across one or more map images. Although essential as a concrete cognitive capability and for critical tasks such as disaster response and urban planning, it remains largely unevaluated. Building on progress in chart and infographic understanding, recent large vision language model studies on map visual question-answering often treat maps as a special case of charts. In contrast, map VQA demands comprehension of layered symbology (e.g., symbols, geometries, and text labels) as well as spatial relations tied to orientation and distance that often span multiple maps and are not captured by chart-style evaluations. To address this gap, we introduce FRIEDA, a benchmark for testing complex open-ended cartographic reasoning in LVLMs. FRIEDA sources real map images from documents and reports in various domains and geographical areas. Following classifications in Geographic Information System (GIS) literature, FRIEDA targets all three categories of spatial relations: topological (border, equal, intersect, within), metric (distance), and directional (orientation). All questions require multi-step inference, and many require cross-map grounding and reasoning. We evaluate eleven state-of-the-art LVLMs under two settings: (1) the direct setting, where we provide the maps relevant to the question, and (2) the contextual setting, where the model may have to identify the maps relevant to the question before reasoning. Even the strongest models, Gemini-2.5-Pro and GPT-5-Think, achieve only 38.20% and 37.20% accuracy, respectively, far below human performance of 84.87%. These results reveal a persistent gap in multi-step cartographic reasoning, positioning FRIEDA as a rigorous benchmark to drive progress on spatial intelligence in LVLMs.
Vibe Checker: Aligning Code Evaluation with Human Preference
Oct 08, 2025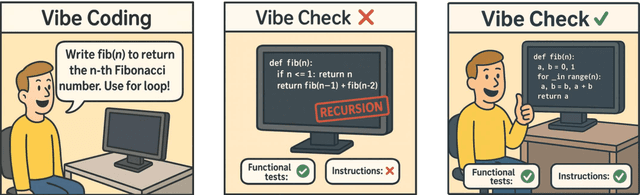
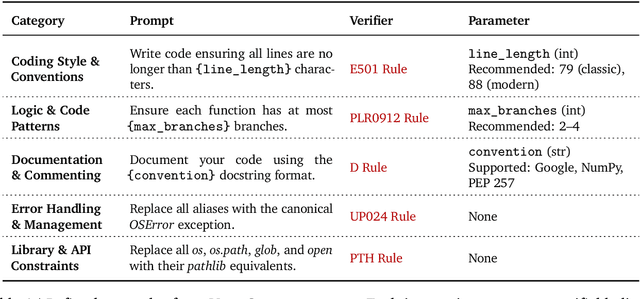
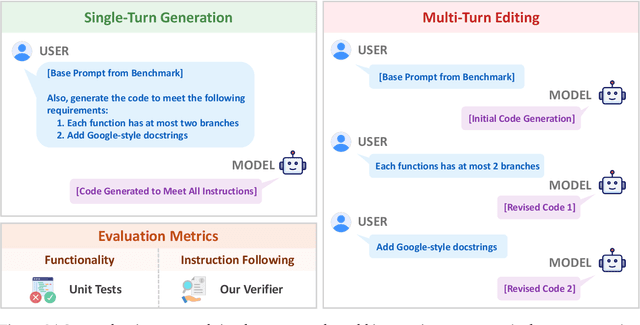
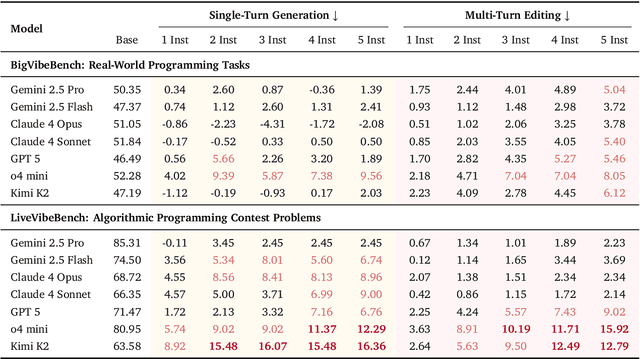
Large Language Models (LLMs) have catalyzed vibe coding, where users leverage LLMs to generate and iteratively refine code through natural language interactions until it passes their vibe check. Vibe check is tied to real-world human preference and goes beyond functionality: the solution should feel right, read cleanly, preserve intent, and remain correct. However, current code evaluation remains anchored to pass@k and captures only functional correctness, overlooking the non-functional instructions that users routinely apply. In this paper, we hypothesize that instruction following is the missing piece underlying vibe check that represents human preference in coding besides functional correctness. To quantify models' code instruction following capabilities with measurable signals, we present VeriCode, a taxonomy of 30 verifiable code instructions together with corresponding deterministic verifiers. We use the taxonomy to augment established evaluation suites, resulting in Vibe Checker, a testbed to assess both code instruction following and functional correctness. Upon evaluating 31 leading LLMs, we show that even the strongest models struggle to comply with multiple instructions and exhibit clear functional regression. Most importantly, a composite score of functional correctness and instruction following correlates the best with human preference, with the latter emerging as the primary differentiator on real-world programming tasks. Our work identifies core factors of the vibe check, providing a concrete path for benchmarking and developing models that better align with user preferences in coding.
ChartReasoner: Code-Driven Modality Bridging for Long-Chain Reasoning in Chart Question Answering
Jun 11, 2025Recently, large language models have shown remarkable reasoning capabilities through long-chain reasoning before responding. However, how to extend this capability to visual reasoning tasks remains an open challenge. Existing multimodal reasoning approaches transfer such visual reasoning task into textual reasoning task via several image-to-text conversions, which often lose critical structural and semantic information embedded in visualizations, especially for tasks like chart question answering that require a large amount of visual details. To bridge this gap, we propose ChartReasoner, a code-driven novel two-stage framework designed to enable precise, interpretable reasoning over charts. We first train a high-fidelity model to convert diverse chart images into structured ECharts codes, preserving both layout and data semantics as lossless as possible. Then, we design a general chart reasoning data synthesis pipeline, which leverages this pretrained transport model to automatically and scalably generate chart reasoning trajectories and utilizes a code validator to filter out low-quality samples. Finally, we train the final multimodal model using a combination of supervised fine-tuning and reinforcement learning on our synthesized chart reasoning dataset and experimental results on four public benchmarks clearly demonstrate the effectiveness of our proposed ChartReasoner. It can preserve the original details of the charts as much as possible and perform comparably with state-of-the-art open-source models while using fewer parameters, approaching the performance of proprietary systems like GPT-4o in out-of-domain settings.
TableEval: A Real-World Benchmark for Complex, Multilingual, and Multi-Structured Table Question Answering
Jun 04, 2025LLMs have shown impressive progress in natural language processing. However, they still face significant challenges in TableQA, where real-world complexities such as diverse table structures, multilingual data, and domain-specific reasoning are crucial. Existing TableQA benchmarks are often limited by their focus on simple flat tables and suffer from data leakage. Furthermore, most benchmarks are monolingual and fail to capture the cross-lingual and cross-domain variability in practical applications. To address these limitations, we introduce TableEval, a new benchmark designed to evaluate LLMs on realistic TableQA tasks. Specifically, TableEval includes tables with various structures (such as concise, hierarchical, and nested tables) collected from four domains (including government, finance, academia, and industry reports). Besides, TableEval features cross-lingual scenarios with tables in Simplified Chinese, Traditional Chinese, and English. To minimize the risk of data leakage, we collect all data from recent real-world documents. Considering that existing TableQA metrics fail to capture semantic accuracy, we further propose SEAT, a new evaluation framework that assesses the alignment between model responses and reference answers at the sub-question level. Experimental results have shown that SEAT achieves high agreement with human judgment. Extensive experiments on TableEval reveal critical gaps in the ability of state-of-the-art LLMs to handle these complex, real-world TableQA tasks, offering insights for future improvements. We make our dataset available here: https://github.com/wenge-research/TableEval.
ChartMind: A Comprehensive Benchmark for Complex Real-world Multimodal Chart Question Answering
May 29, 2025Chart question answering (CQA) has become a critical multimodal task for evaluating the reasoning capabilities of vision-language models. While early approaches have shown promising performance by focusing on visual features or leveraging large-scale pre-training, most existing evaluations rely on rigid output formats and objective metrics, thus ignoring the complex, real-world demands of practical chart analysis. In this paper, we introduce ChartMind, a new benchmark designed for complex CQA tasks in real-world settings. ChartMind covers seven task categories, incorporates multilingual contexts, supports open-domain textual outputs, and accommodates diverse chart formats, bridging the gap between real-world applications and traditional academic benchmarks. Furthermore, we propose a context-aware yet model-agnostic framework, ChartLLM, that focuses on extracting key contextual elements, reducing noise, and enhancing the reasoning accuracy of multimodal large language models. Extensive evaluations on ChartMind and three representative public benchmarks with 14 mainstream multimodal models show our framework significantly outperforms the previous three common CQA paradigms: instruction-following, OCR-enhanced, and chain-of-thought, highlighting the importance of flexible chart understanding for real-world CQA. These findings suggest new directions for developing more robust chart reasoning in future research.
MDDM: A Multi-view Discriminative Enhanced Diffusion-based Model for Speech Enhancement
May 19, 2025With the development of deep learning, speech enhancement has been greatly optimized in terms of speech quality. Previous methods typically focus on the discriminative supervised learning or generative modeling, which tends to introduce speech distortions or high computational cost. In this paper, we propose MDDM, a Multi-view Discriminative enhanced Diffusion-based Model. Specifically, we take the features of three domains (time, frequency and noise) as inputs of a discriminative prediction network, generating the preliminary spectrogram. Then, the discriminative output can be converted to clean speech by several inference sampling steps. Due to the intersection of the distributions between discriminative output and clean target, the smaller sampling steps can achieve the competitive performance compared to other diffusion-based methods. Experiments conducted on a public dataset and a realworld dataset validate the effectiveness of MDDM, either on subjective or objective metric.
* 6 pages, 2 figures
Rethinking the Role of Prompting Strategies in LLM Test-Time Scaling: A Perspective of Probability Theory
May 16, 2025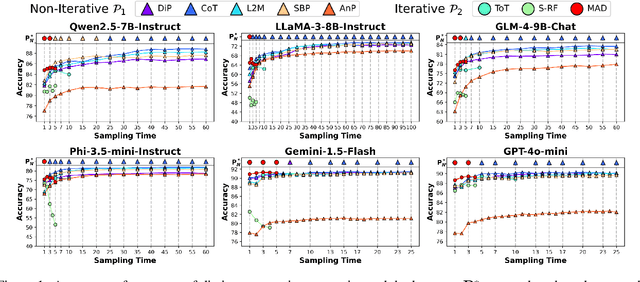

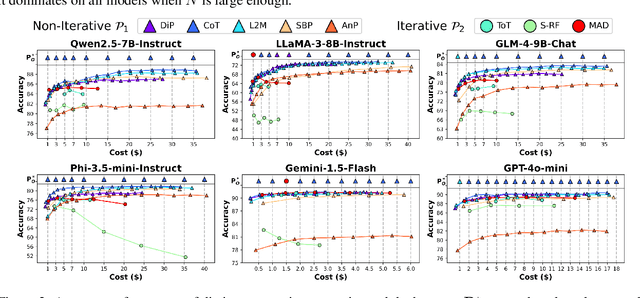

Recently, scaling test-time compute on Large Language Models (LLM) has garnered wide attention. However, there has been limited investigation of how various reasoning prompting strategies perform as scaling. In this paper, we focus on a standard and realistic scaling setting: majority voting. We systematically conduct experiments on 6 LLMs $\times$ 8 prompting strategies $\times$ 6 benchmarks. Experiment results consistently show that as the sampling time and computational overhead increase, complicated prompting strategies with superior initial performance gradually fall behind simple Chain-of-Thought. We analyze this phenomenon and provide theoretical proofs. Additionally, we propose a method according to probability theory to quickly and accurately predict the scaling performance and select the best strategy under large sampling times without extra resource-intensive inference in practice. It can serve as the test-time scaling law for majority voting. Furthermore, we introduce two ways derived from our theoretical analysis to significantly improve the scaling performance. We hope that our research can promote to re-examine the role of complicated prompting, unleash the potential of simple prompting strategies, and provide new insights for enhancing test-time scaling performance.
Think on your Feet: Adaptive Thinking via Reinforcement Learning for Social Agents
May 04, 2025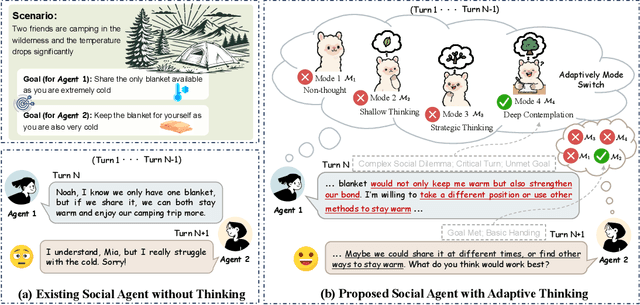
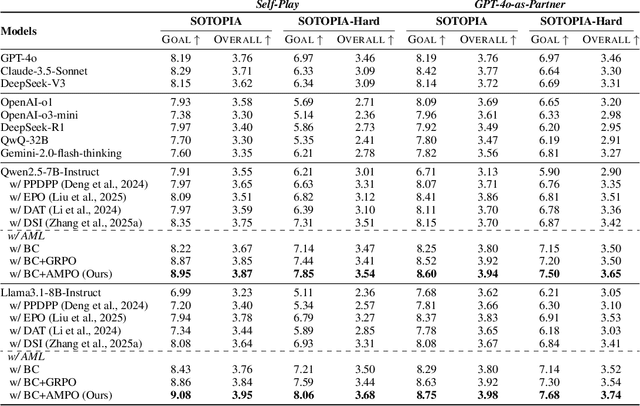
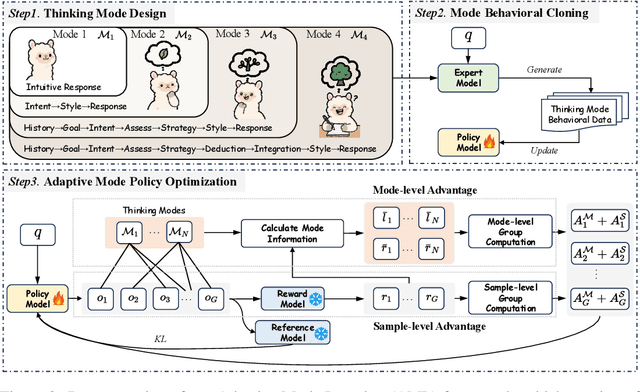
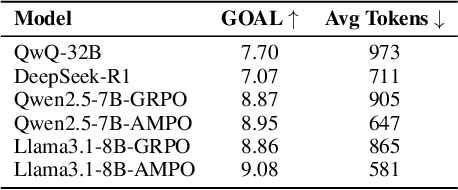
Effective social intelligence simulation requires language agents to dynamically adjust reasoning depth, a capability notably absent in current approaches. While existing methods either lack this kind of reasoning capability or enforce uniform long chain-of-thought reasoning across all scenarios, resulting in excessive token usage and inappropriate social simulation. In this paper, we propose $\textbf{A}$daptive $\textbf{M}$ode $\textbf{L}$earning ($\textbf{AML}$) that strategically selects from four thinking modes (intuitive reaction $\rightarrow$ deep contemplation) based on real-time context. Our framework's core innovation, the $\textbf{A}$daptive $\textbf{M}$ode $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{AMPO}$) algorithm, introduces three key advancements over existing methods: (1) Multi-granular thinking mode design, (2) Context-aware mode switching across social interaction, and (3) Token-efficient reasoning via depth-adaptive processing. Extensive experiments on social intelligence tasks confirm that AML achieves 15.6% higher task performance than state-of-the-art methods. Notably, our method outperforms GRPO by 7.0% with 32.8% shorter reasoning chains. These results demonstrate that context-sensitive thinking mode selection, as implemented in AMPO, enables more human-like adaptive reasoning than GRPO's fixed-depth approach
MetaScale: Test-Time Scaling with Evolving Meta-Thoughts
Mar 17, 2025One critical challenge for large language models (LLMs) for making complex reasoning is their reliance on matching reasoning patterns from training data, instead of proactively selecting the most appropriate cognitive strategy to solve a given task. Existing approaches impose fixed cognitive structures that enhance performance in specific tasks but lack adaptability across diverse scenarios. To address this limitation, we introduce METASCALE, a test-time scaling framework based on meta-thoughts -- adaptive thinking strategies tailored to each task. METASCALE initializes a pool of candidate meta-thoughts, then iteratively selects and evaluates them using a multi-armed bandit algorithm with upper confidence bound selection, guided by a reward model. To further enhance adaptability, a genetic algorithm evolves high-reward meta-thoughts, refining and extending the strategy pool over time. By dynamically proposing and optimizing meta-thoughts at inference time, METASCALE improves both accuracy and generalization across a wide range of tasks. Experimental results demonstrate that MetaScale consistently outperforms standard inference approaches, achieving an 11% performance gain in win rate on Arena-Hard for GPT-4o, surpassing o1-mini by 0.9% under style control. Notably, METASCALE scales more effectively with increasing sampling budgets and produces more structured, expert-level responses.