 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2CDR: Smoothing-Sharpening Process Model for Cross-Domain Recommendation
Mar 03, 2026User cold-start problem is a long-standing challenge in recommendation systems. Fortunately, cross-domain recommendation (CDR) has emerged as a highly effective remedy for the user cold-start challenge, with recently developed diffusion models (DMs) demonstrating exceptional performance. However, these DMs-based CDR methods focus on dealing with user-item interactions, overlooking correlations between items across the source and target domains. Meanwhile, the Gaussian noise added in the forward process of diffusion models would hurt user's personalized preference, leading to the difficulty in transferring user preference across domains. To this end, we propose a novel paradigm of Smoothing-Sharpening Process Model for CDR to cold-start users, termed as S2CDR which features a corruption-recovery architecture and is solved with respect to ordinary differential equations (ODEs). Specifically, the smoothing process gradually corrupts the original user-item/item-item interaction matrices derived from both domains into smoothed preference signals in a noise-free manner, and the sharpening process iteratively sharpens the preference signals to recover the unknown interactions for cold-start users. Wherein, for the smoothing process, we introduce the heat equation on the item-item similarity graph to better capture the correlations between items across domains, and further build the tailor-designed low-pass filter to filter out the high-frequency noise information for capturing user's intrinsic preference, in accordance with the graph signal processing (GSP) theory. Extensive experiments on three real-world CDR scenarios confirm that our S2CDR significantly outperforms previous SOTA methods in a training-free manner.
MemPO: Self-Memory Policy Optimization for Long-Horizon Agents
Feb 28, 2026Long-horizon agents face the challenge of growing context size during interaction with environment, which degrades the performance and stability. Existing methods typically introduce the external memory module and look up the relevant information from the stored memory, which prevents the model itself from proactively managing its memory content and aligning with the agent's overarching task objectives. To address these limitations, we propose the self-memory policy optimization algorithm (MemPO), which enables the agent (policy model) to autonomously summarize and manage their memory during interaction with environment. By improving the credit assignment mechanism based on memory effectiveness, the policy model can selectively retain crucial information, significantly reducing token consumption while preserving task performance. Extensive experiments and analyses confirm that MemPO achieves absolute F1 score gains of 25.98% over the base model and 7.1% over the previous SOTA baseline, while reducing token usage by 67.58% and 73.12%.
ExpSeek: Self-Triggered Experience Seeking for Web Agents
Jan 13, 2026Experience intervention in web agents emerges as a promising technical paradigm, enhancing agent interaction capabilities by providing valuable insights from accumulated experiences. However, existing methods predominantly inject experience passively as global context before task execution, struggling to adapt to dynamically changing contextual observations during agent-environment interaction. We propose ExpSeek, which shifts experience toward step-level proactive seeking: (1) estimating step-level entropy thresholds to determine intervention timing using the model's intrinsic signals; (2) designing step-level tailor-designed experience content. Experiments on Qwen3-8B and 32B models across four challenging web agent benchmarks demonstrate that ExpSeek achieves absolute improvements of 9.3% and 7.5%, respectively. Our experiments validate the feasibility and advantages of entropy as a self-triggering signal, reveal that even a 4B small-scale experience model can significantly boost the performance of larger agent models.
Towards Comprehensible Recommendation with Large Language Model Fine-tuning
Aug 11, 2025Recommender systems have become increasingly ubiquitous in daily life. While traditional recommendation approaches primarily rely on ID-based representations or item-side content features, they often fall short in capturing the underlying semantics aligned with user preferences (e.g., recommendation reasons for items), leading to a semantic-collaborative gap. Recently emerged LLM-based feature extraction approaches also face a key challenge: how to ensure that LLMs possess recommendation-aligned reasoning capabilities and can generate accurate, personalized reasons to mitigate the semantic-collaborative gap. To address these issues, we propose a novel Content Understanding from a Collaborative Perspective framework (CURec), which generates collaborative-aligned content features for more comprehensive recommendations. \method first aligns the LLM with recommendation objectives through pretraining, equipping it with instruction-following and chain-of-thought reasoning capabilities. Next, we design a reward model inspired by traditional recommendation architectures to evaluate the quality of the recommendation reasons generated by the LLM. Finally, using the reward signals, CURec fine-tunes the LLM through RL and corrects the generated reasons to ensure their accuracy. The corrected reasons are then integrated into a downstream recommender model to enhance comprehensibility and recommendation performance. Extensive experiments on public benchmarks demonstrate the superiority of CURec over existing methods.
LearnAlign: Reasoning Data Selection for Reinforcement Learning in Large Language Models Based on Improved Gradient Alignment
Jun 13, 2025Reinforcement learning (RL) has become a key technique for enhancing LLMs' reasoning abilities, yet its data inefficiency remains a major bottleneck. To address this critical yet challenging issue, we present a novel gradient-alignment-based method, named LearnAlign, which intelligently selects the learnable and representative training reasoning data for RL post-training. To overcome the well-known issue of response-length bias in gradient norms, we introduce the data learnability based on the success rate, which can indicate the learning potential of each data point. Experiments across three mathematical reasoning benchmarks demonstrate that our method significantly reduces training data requirements while achieving minor performance degradation or even improving performance compared to full-data training. For example, it reduces data requirements by up to 1,000 data points with better performance (77.53%) than that on the full dataset on GSM8K benchmark (77.04%). Furthermore, we show its effectiveness in the staged RL setting. This work provides valuable insights into data-efficient RL post-training and establishes a foundation for future research in optimizing reasoning data selection.To facilitate future work, we will release code.
EIFBENCH: Extremely Complex Instruction Following Benchmark for Large Language Models
Jun 10, 2025With the development and widespread application of large language models (LLMs), the new paradigm of "Model as Product" is rapidly evolving, and demands higher capabilities to address complex user needs, often requiring precise workflow execution which involves the accurate understanding of multiple tasks. However, existing benchmarks focusing on single-task environments with limited constraints lack the complexity required to fully reflect real-world scenarios. To bridge this gap, we present the Extremely Complex Instruction Following Benchmark (EIFBENCH), meticulously crafted to facilitate a more realistic and robust evaluation of LLMs. EIFBENCH not only includes multi-task scenarios that enable comprehensive assessment across diverse task types concurrently, but also integrates a variety of constraints, replicating complex operational environments. Furthermore, we propose the Segment Policy Optimization (SegPO) algorithm to enhance the LLM's ability to accurately fulfill multi-task workflow. Evaluations on EIFBENCH have unveiled considerable performance discrepancies in existing LLMs when challenged with these extremely complex instructions. This finding underscores the necessity for ongoing optimization to navigate the intricate challenges posed by LLM applications.
Socratic-PRMBench: Benchmarking Process Reward Models with Systematic Reasoning Patterns
May 29, 2025Process Reward Models (PRMs) are crucial in complex reasoning and problem-solving tasks (e.g., LLM agents with long-horizon decision-making) by verifying the correctness of each intermediate reasoning step. In real-world scenarios, LLMs may apply various reasoning patterns (e.g., decomposition) to solve a problem, potentially suffering from errors under various reasoning patterns. Therefore, PRMs are required to identify errors under various reasoning patterns during the reasoning process. However, existing benchmarks mainly focus on evaluating PRMs with stepwise correctness, ignoring a systematic evaluation of PRMs under various reasoning patterns. To mitigate this gap, we introduce Socratic-PRMBench, a new benchmark to evaluate PRMs systematically under six reasoning patterns, including Transformation, Decomposition, Regather, Deduction, Verification, and Integration. Socratic-PRMBench}comprises 2995 reasoning paths with flaws within the aforementioned six reasoning patterns. Through our experiments on both PRMs and LLMs prompted as critic models, we identify notable deficiencies in existing PRMs. These observations underscore the significant weakness of current PRMs in conducting evaluations on reasoning steps under various reasoning patterns. We hope Socratic-PRMBench can serve as a comprehensive testbed for systematic evaluation of PRMs under diverse reasoning patterns and pave the way for future development of PRMs.
Graph Wave Networks
May 26, 2025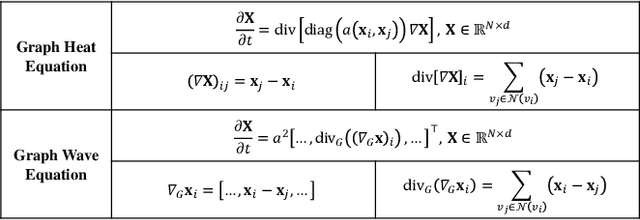
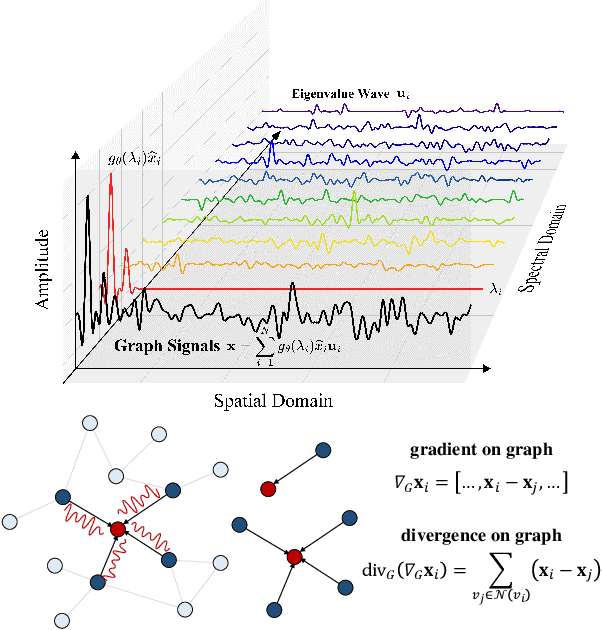
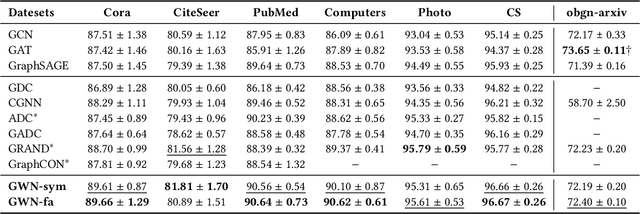
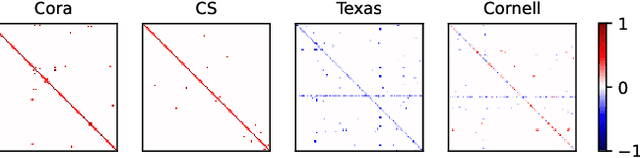
Dynamics modeling has been introduced as a novel paradigm in message passing (MP) of graph neural networks (GNNs). Existing methods consider MP between nodes as a heat diffusion process, and leverage heat equation to model the temporal evolution of nodes in the embedding space. However, heat equation can hardly depict the wave nature of graph signals in graph signal processing. Besides, heat equation is essentially a partial differential equation (PDE) involving a first partial derivative of time, whose numerical solution usually has low stability, and leads to inefficient model training. In this paper, we would like to depict more wave details in MP, since graph signals are essentially wave signals that can be seen as a superposition of a series of waves in the form of eigenvector. This motivates us to consider MP as a wave propagation process to capture the temporal evolution of wave signals in the space. Based on wave equation in physics, we innovatively develop a graph wave equation to leverage the wave propagation on graphs. In details, we demonstrate that the graph wave equation can be connected to traditional spectral GNNs, facilitating the design of graph wave networks based on various Laplacians and enhancing the performance of the spectral GNNs. Besides, the graph wave equation is particularly a PDE involving a second partial derivative of time, which has stronger stability on graphs than the heat equation that involves a first partial derivative of time. Additionally, we theoretically prove that the numerical solution derived from the graph wave equation are constantly stable, enabling to significantly enhance model efficiency while ensuring its performance. Extensive experiments show that GWNs achieve SOTA and efficient performance on benchmark datasets, and exhibit outstanding performance in addressing challenging graph problems, such as over-smoothing and heterophily.
* 15 pages, 8 figures, published to WWW 2025
Think on your Feet: Adaptive Thinking via Reinforcement Learning for Social Agents
May 04, 2025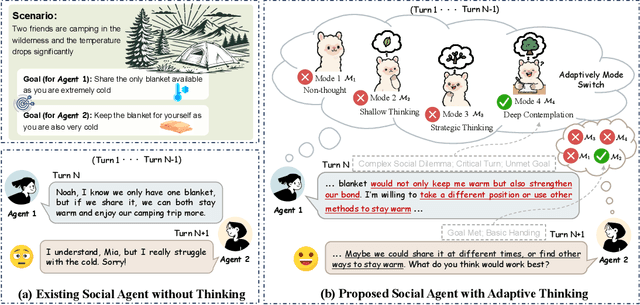
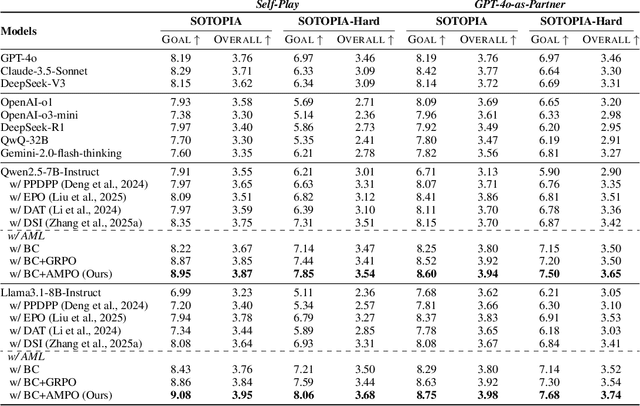
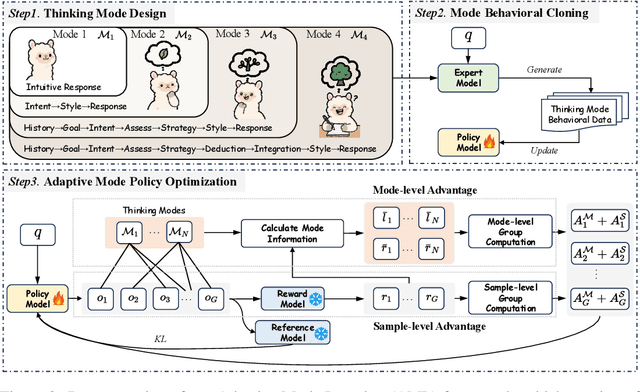
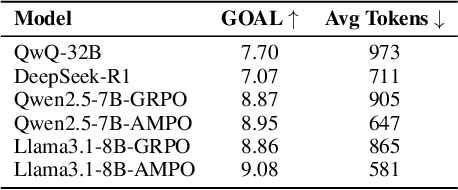
Effective social intelligence simulation requires language agents to dynamically adjust reasoning depth, a capability notably absent in current approaches. While existing methods either lack this kind of reasoning capability or enforce uniform long chain-of-thought reasoning across all scenarios, resulting in excessive token usage and inappropriate social simulation. In this paper, we propose $\textbf{A}$daptive $\textbf{M}$ode $\textbf{L}$earning ($\textbf{AML}$) that strategically selects from four thinking modes (intuitive reaction $\rightarrow$ deep contemplation) based on real-time context. Our framework's core innovation, the $\textbf{A}$daptive $\textbf{M}$ode $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{AMPO}$) algorithm, introduces three key advancements over existing methods: (1) Multi-granular thinking mode design, (2) Context-aware mode switching across social interaction, and (3) Token-efficient reasoning via depth-adaptive processing. Extensive experiments on social intelligence tasks confirm that AML achieves 15.6% higher task performance than state-of-the-art methods. Notably, our method outperforms GRPO by 7.0% with 32.8% shorter reasoning chains. These results demonstrate that context-sensitive thinking mode selection, as implemented in AMPO, enables more human-like adaptive reasoning than GRPO's fixed-depth approach
S1-Bench: A Simple Benchmark for Evaluating System 1 Thinking Capability of Large Reasoning Models
Apr 14, 2025



We introduce S1-Bench, a novel benchmark designed to evaluate Large Reasoning Models' (LRMs) performance on simple tasks that favor intuitive system 1 thinking rather than deliberative system 2 reasoning. While LRMs have achieved significant breakthroughs in complex reasoning tasks through explicit chains of thought, their reliance on deep analytical thinking may limit their system 1 thinking capabilities. Moreover, a lack of benchmark currently exists to evaluate LRMs' performance in tasks that require such capabilities. To fill this gap, S1-Bench presents a set of simple, diverse, and naturally clear questions across multiple domains and languages, specifically designed to assess LRMs' performance in such tasks. Our comprehensive evaluation of 22 LRMs reveals significant lower efficiency tendencies, with outputs averaging 15.5 times longer than those of traditional small LLMs. Additionally, LRMs often identify correct answers early but continue unnecessary deliberation, with some models even producing numerous errors. These findings highlight the rigid reasoning patterns of current LRMs and underscore the substantial development needed to achieve balanced dual-system thinking capabilities that can adapt appropriately to task complexity.