 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpSeek: Self-Triggered Experience Seeking for Web Agents
Jan 13, 2026Experience intervention in web agents emerges as a promising technical paradigm, enhancing agent interaction capabilities by providing valuable insights from accumulated experiences. However, existing methods predominantly inject experience passively as global context before task execution, struggling to adapt to dynamically changing contextual observations during agent-environment interaction. We propose ExpSeek, which shifts experience toward step-level proactive seeking: (1) estimating step-level entropy thresholds to determine intervention timing using the model's intrinsic signals; (2) designing step-level tailor-designed experience content. Experiments on Qwen3-8B and 32B models across four challenging web agent benchmarks demonstrate that ExpSeek achieves absolute improvements of 9.3% and 7.5%, respectively. Our experiments validate the feasibility and advantages of entropy as a self-triggering signal, reveal that even a 4B small-scale experience model can significantly boost the performance of larger agent models.
EvoRoute: Experience-Driven Self-Routing LLM Agent Systems
Jan 06, 2026Complex agentic AI systems, powered by a coordinated ensemble of Large Language Models (LLMs), tool and memory modules, have demonstrated remarkable capabilities on intricate, multi-turn tasks. However, this success is shadowed by prohibitive economic costs and severe latency, exposing a critical, yet underexplored, trade-off. We formalize this challenge as the \textbf{Agent System Trilemma}: the inherent tension among achieving state-of-the-art performance, minimizing monetary cost, and ensuring rapid task completion. To dismantle this trilemma, we introduce EvoRoute, a self-evolving model routing paradigm that transcends static, pre-defined model assignments. Leveraging an ever-expanding knowledge base of prior experience, EvoRoute dynamically selects Pareto-optimal LLM backbones at each step, balancing accuracy, efficiency, and resource use, while continually refining its own selection policy through environment feedback. Experiments on challenging agentic benchmarks such as GAIA and BrowseComp+ demonstrate that EvoRoute, when integrated into off-the-shelf agentic systems, not only sustains or enhances system performance but also reduces execution cost by up to $80\%$ and latency by over $70\%$.
Think on your Feet: Adaptive Thinking via Reinforcement Learning for Social Agents
May 04, 2025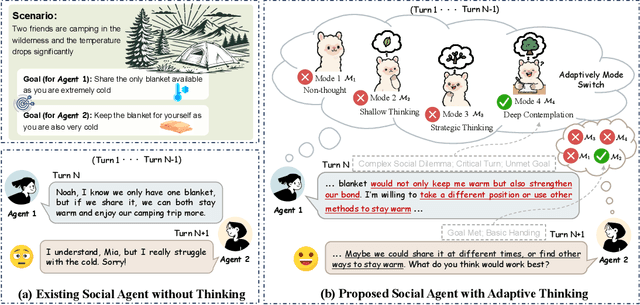
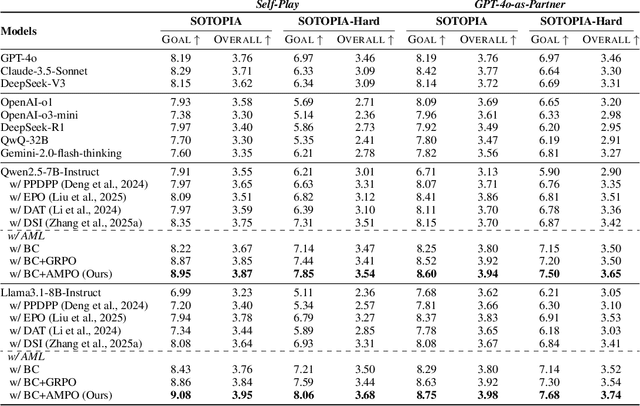
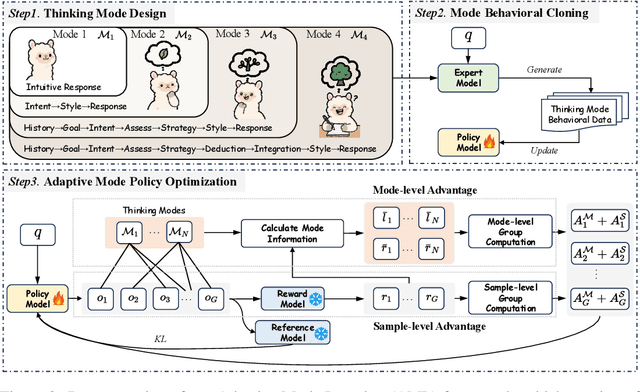
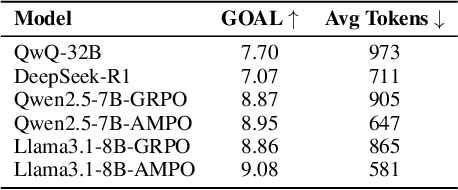
Effective social intelligence simulation requires language agents to dynamically adjust reasoning depth, a capability notably absent in current approaches. While existing methods either lack this kind of reasoning capability or enforce uniform long chain-of-thought reasoning across all scenarios, resulting in excessive token usage and inappropriate social simulation. In this paper, we propose $\textbf{A}$daptive $\textbf{M}$ode $\textbf{L}$earning ($\textbf{AML}$) that strategically selects from four thinking modes (intuitive reaction $\rightarrow$ deep contemplation) based on real-time context. Our framework's core innovation, the $\textbf{A}$daptive $\textbf{M}$ode $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{AMPO}$) algorithm, introduces three key advancements over existing methods: (1) Multi-granular thinking mode design, (2) Context-aware mode switching across social interaction, and (3) Token-efficient reasoning via depth-adaptive processing. Extensive experiments on social intelligence tasks confirm that AML achieves 15.6% higher task performance than state-of-the-art methods. Notably, our method outperforms GRPO by 7.0% with 32.8% shorter reasoning chains. These results demonstrate that context-sensitive thinking mode selection, as implemented in AMPO, enables more human-like adaptive reasoning than GRPO's fixed-depth approach
Leave No Document Behind: Benchmarking Long-Context LLMs with Extended Multi-Doc QA
Jun 25, 2024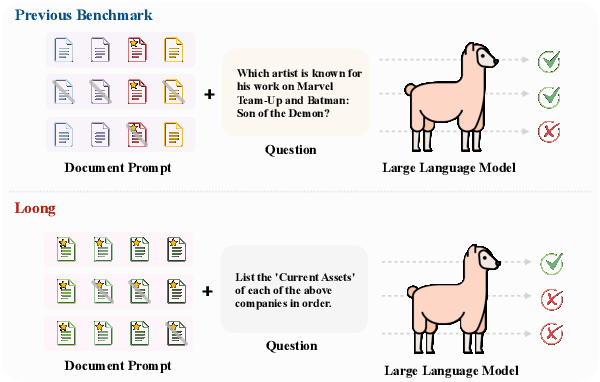
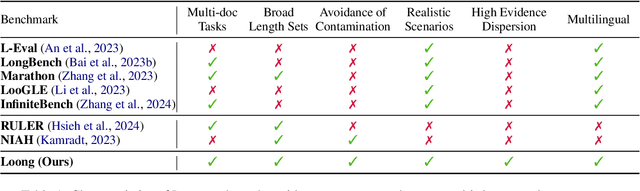
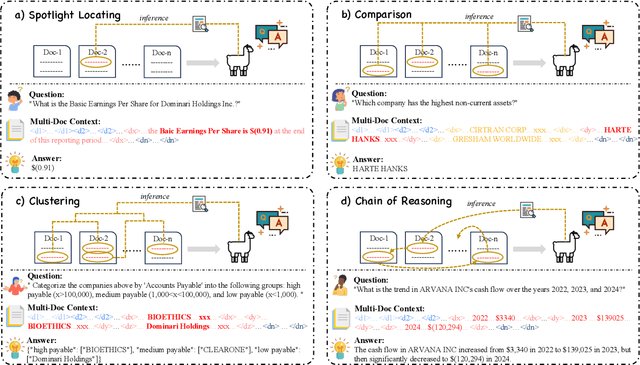

Long-context modeling capabilities have garnered widespread attention, leading to the emergence of Large Language Models (LLMs) with ultra-context windows. Meanwhile, benchmarks for evaluating long-context LLMs are gradually catching up. However, existing benchmarks employ irrelevant noise texts to artificially extend the length of test cases, diverging from the real-world scenarios of long-context applications. To bridge this gap, we propose a novel long-context benchmark, Loong, aligning with realistic scenarios through extended multi-document question answering (QA). Unlike typical document QA, in Loong's test cases, each document is relevant to the final answer, ignoring any document will lead to the failure of the answer. Furthermore, Loong introduces four types of tasks with a range of context lengths: Spotlight Locating, Comparison, Clustering, and Chain of Reasoning, to facilitate a more realistic and comprehensive evaluation of long-context understanding. Extensive experiments indicate that existing long-context language models still exhibit considerable potential for enhancement. Retrieval augmented generation (RAG) achieves poor performance, demonstrating that Loong can reliably assess the model's long-context modeling capabilities.