 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies
Dec 22, 2025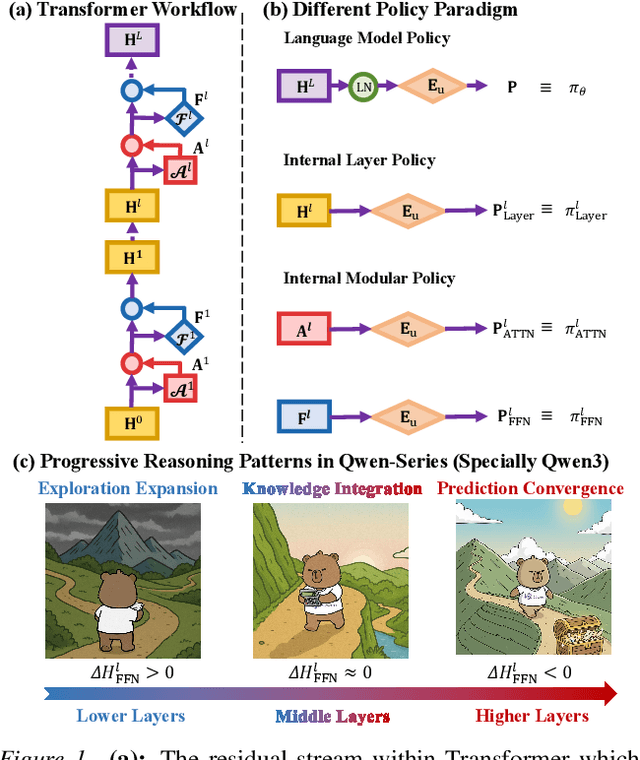
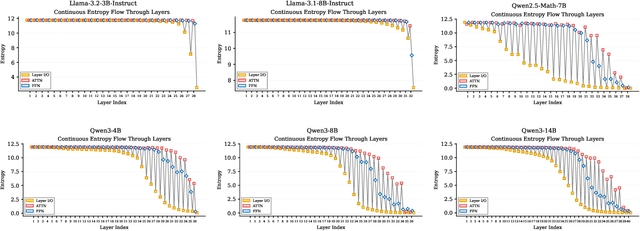
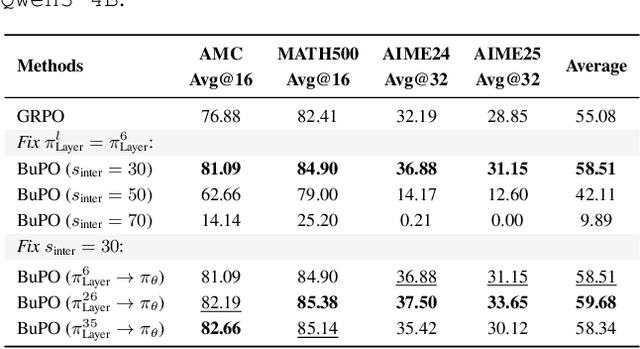
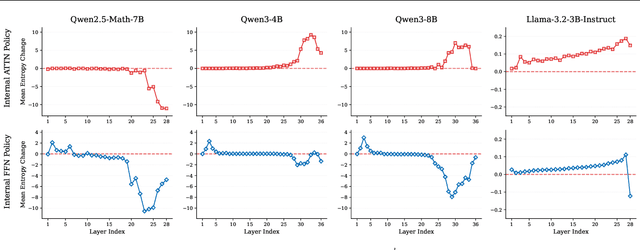
Existing reinforcement learning (RL) approaches treat large language models (LLMs) as a single unified policy, overlooking their internal mechanisms. Understanding how policy evolves across layers and modules is therefore crucial for enabling more targeted optimization and raveling out complex reasoning mechanisms. In this paper, we decompose the language model policy by leveraging the intrinsic split of the Transformer residual stream and the equivalence between the composition of hidden states with the unembedding matrix and the resulting samplable policy. This decomposition reveals Internal Layer Policies, corresponding to contributions from individual layers, and Internal Modular Policies, which align with the self-attention and feed-forward network (FFN) components within each layer. By analyzing the entropy of internal policy, we find that: (a) Early layers keep high entropy for exploration, top layers converge to near-zero entropy for refinement, with convergence patterns varying across model series. (b) LLama's prediction space rapidly converges in the final layer, whereas Qwen-series models, especially Qwen3, exhibit a more human-like, progressively structured reasoning pattern. Motivated by these findings, we propose Bottom-up Policy Optimization (BuPO), a novel RL paradigm that directly optimizes the internal layer policy during early training. By aligning training objective at lower layer, BuPO reconstructs foundational reasoning capabilities and achieves superior performance. Extensive experiments on complex reasoning benchmarks demonstrates the effectiveness of our method. Our code is available at https://github.com/Trae1ounG/BuPO.
EIFBENCH: Extremely Complex Instruction Following Benchmark for Large Language Models
Jun 10, 2025With the development and widespread application of large language models (LLMs), the new paradigm of "Model as Product" is rapidly evolving, and demands higher capabilities to address complex user needs, often requiring precise workflow execution which involves the accurate understanding of multiple tasks. However, existing benchmarks focusing on single-task environments with limited constraints lack the complexity required to fully reflect real-world scenarios. To bridge this gap, we present the Extremely Complex Instruction Following Benchmark (EIFBENCH), meticulously crafted to facilitate a more realistic and robust evaluation of LLMs. EIFBENCH not only includes multi-task scenarios that enable comprehensive assessment across diverse task types concurrently, but also integrates a variety of constraints, replicating complex operational environments. Furthermore, we propose the Segment Policy Optimization (SegPO) algorithm to enhance the LLM's ability to accurately fulfill multi-task workflow. Evaluations on EIFBENCH have unveiled considerable performance discrepancies in existing LLMs when challenged with these extremely complex instructions. This finding underscores the necessity for ongoing optimization to navigate the intricate challenges posed by LLM applications.
Think on your Feet: Adaptive Thinking via Reinforcement Learning for Social Agents
May 04, 2025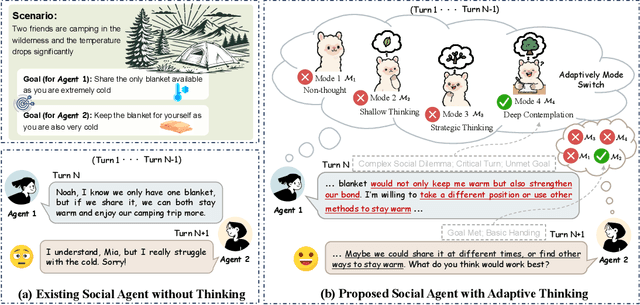
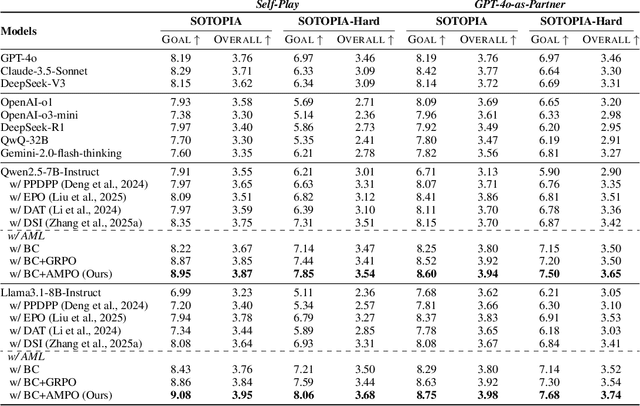
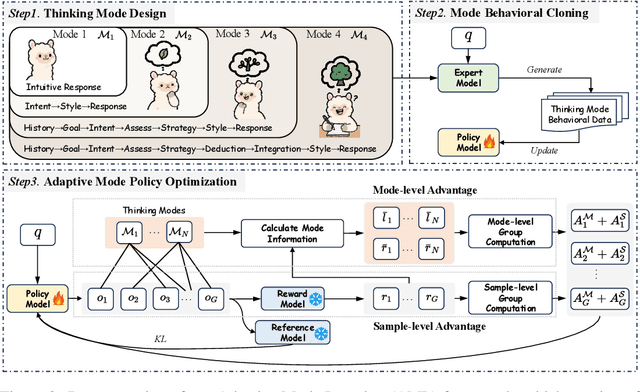
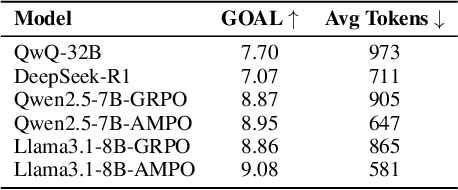
Effective social intelligence simulation requires language agents to dynamically adjust reasoning depth, a capability notably absent in current approaches. While existing methods either lack this kind of reasoning capability or enforce uniform long chain-of-thought reasoning across all scenarios, resulting in excessive token usage and inappropriate social simulation. In this paper, we propose $\textbf{A}$daptive $\textbf{M}$ode $\textbf{L}$earning ($\textbf{AML}$) that strategically selects from four thinking modes (intuitive reaction $\rightarrow$ deep contemplation) based on real-time context. Our framework's core innovation, the $\textbf{A}$daptive $\textbf{M}$ode $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{AMPO}$) algorithm, introduces three key advancements over existing methods: (1) Multi-granular thinking mode design, (2) Context-aware mode switching across social interaction, and (3) Token-efficient reasoning via depth-adaptive processing. Extensive experiments on social intelligence tasks confirm that AML achieves 15.6% higher task performance than state-of-the-art methods. Notably, our method outperforms GRPO by 7.0% with 32.8% shorter reasoning chains. These results demonstrate that context-sensitive thinking mode selection, as implemented in AMPO, enables more human-like adaptive reasoning than GRPO's fixed-depth approach
DEMO: Reframing Dialogue Interaction with Fine-grained Element Modeling
Dec 06, 2024



Large language models (LLMs) have made dialogue one of the central modes of human-machine interaction, leading to the accumulation of vast amounts of conversation logs and increasing demand for dialogue generation. A conversational life-cycle spans from the Prelude through the Interlocution to the Epilogue, encompassing various elements. Despite the existence of numerous dialogue-related studies, there is a lack of benchmarks that encompass comprehensive dialogue elements, hindering precise modeling and systematic evaluation. To bridge this gap, we introduce an innovative research task $\textbf{D}$ialogue $\textbf{E}$lement $\textbf{MO}$deling, including $\textit{Element Awareness}$ and $\textit{Dialogue Agent Interaction}$, and propose a novel benchmark, $\textbf{DEMO}$, designed for a comprehensive dialogue modeling and assessment. Inspired by imitation learning, we further build the agent which possesses the adept ability to model dialogue elements based on the DEMO benchmark. Extensive experiments indicate that existing LLMs still exhibit considerable potential for enhancement, and our DEMO agent has superior performance in both in-domain and out-of-domain tasks.
The Imperative of Conversation Analysis in the Era of LLMs: A Survey of Tasks, Techniques, and Trends
Sep 21, 2024



In the era of large language models (LLMs), a vast amount of conversation logs will be accumulated thanks to the rapid development trend of language UI. Conversation Analysis (CA) strives to uncover and analyze critical information from conversation data, streamlining manual processes and supporting business insights and decision-making. The need for CA to extract actionable insights and drive empowerment is becoming increasingly prominent and attracting widespread attention. However, the lack of a clear scope for CA leads to a dispersion of various techniques, making it difficult to form a systematic technical synergy to empower business applications. In this paper, we perform a thorough review and systematize CA task to summarize the existing related work. Specifically, we formally define CA task to confront the fragmented and chaotic landscape in this field, and derive four key steps of CA from conversation scene reconstruction, to in-depth attribution analysis, and then to performing targeted training, finally generating conversations based on the targeted training for achieving the specific goals. In addition, we showcase the relevant benchmarks, discuss potential challenges and point out future directions in both industry and academia. In view of current advancements, it is evident that the majority of efforts are still concentrated on the analysis of shallow conversation elements, which presents a considerable gap between the research and business, and with the assist of LLMs, recent work has shown a trend towards research on causality and strategic tasks which are sophisticated and high-level. The analyzed experiences and insights will inevitably have broader application value in business operations that target conversation logs.
MMEvol: Empowering Multimodal Large Language Models with Evol-Instruct
Sep 09, 2024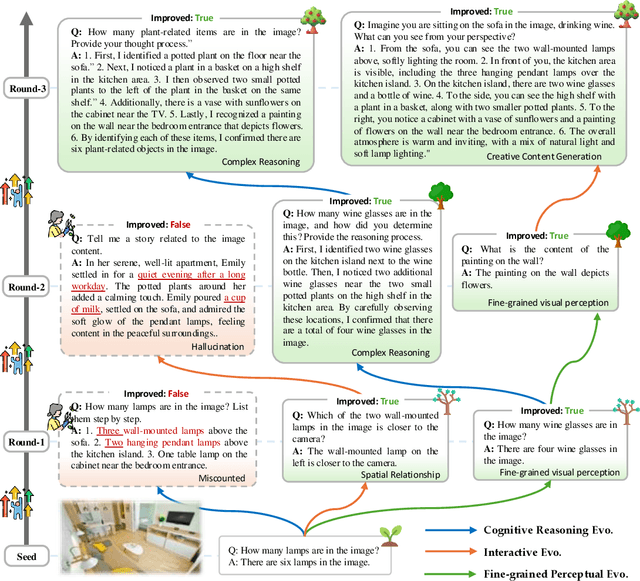
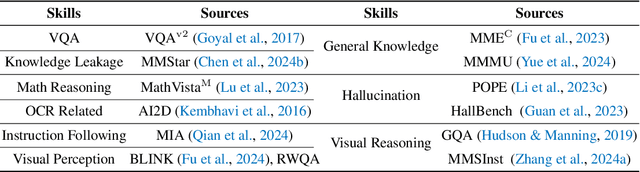

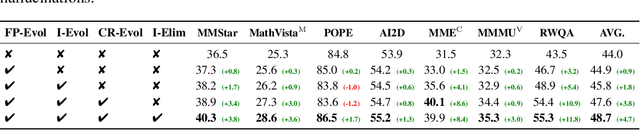
The development of Multimodal Large Language Models (MLLMs) has seen significant advancements. However, the quantity and quality of multimodal instruction data have emerged as significant bottlenecks in their progress. Manually creating multimodal instruction data is both time-consuming and inefficient, posing challenges in producing instructions of high complexity. Moreover, distilling instruction data from black-box commercial models (e.g., GPT-4o, GPT-4V) often results in simplistic instruction data, which constrains performance to that of these models. The challenge of curating diverse and complex instruction data remains substantial. We propose MMEvol, a novel multimodal instruction data evolution framework that combines fine-grained perception evolution, cognitive reasoning evolution, and interaction evolution. This iterative approach breaks through data quality bottlenecks to generate a complex and diverse image-text instruction dataset, thereby empowering MLLMs with enhanced capabilities. Beginning with an initial set of instructions, SEED-163K, we utilize MMEvol to systematically broadens the diversity of instruction types, integrates reasoning steps to enhance cognitive capabilities, and extracts detailed information from images to improve visual understanding and robustness. To comprehensively evaluate the effectiveness of our data, we train LLaVA-NeXT using the evolved data and conduct experiments across 13 vision-language tasks. Compared to the baseline trained with seed data, our approach achieves an average accuracy improvement of 3.1 points and reaches state-of-the-art (SOTA) performance on 9 of these tasks.
Hierarchical Context Pruning: Optimizing Real-World Code Completion with Repository-Level Pretrained Code LLMs
Jun 27, 2024



Some recently developed code large language models (Code LLMs) have been pre-trained on repository-level code data (Repo-Code LLMs), enabling these models to recognize repository structures and utilize cross-file information for code completion. However, in real-world development scenarios, simply concatenating the entire code repository often exceeds the context window limits of these Repo-Code LLMs, leading to significant performance degradation. In this study, we conducted extensive preliminary experiments and analyses on six Repo-Code LLMs. The results indicate that maintaining the topological dependencies of files and increasing the code file content in the completion prompts can improve completion accuracy; pruning the specific implementations of functions in all dependent files does not significantly reduce the accuracy of completions. Based on these findings, we proposed a strategy named Hierarchical Context Pruning (HCP) to construct completion prompts with high informational code content. The HCP models the code repository at the function level, maintaining the topological dependencies between code files while removing a large amount of irrelevant code content, significantly reduces the input length for repository-level code completion. We applied the HCP strategy in experiments with six Repo-Code LLMs, and the results demonstrate that our proposed method can significantly enhance completion accuracy while substantially reducing the length of input. Our code and data are available at https://github.com/Hambaobao/HCP-Coder.
Leave No Document Behind: Benchmarking Long-Context LLMs with Extended Multi-Doc QA
Jun 25, 2024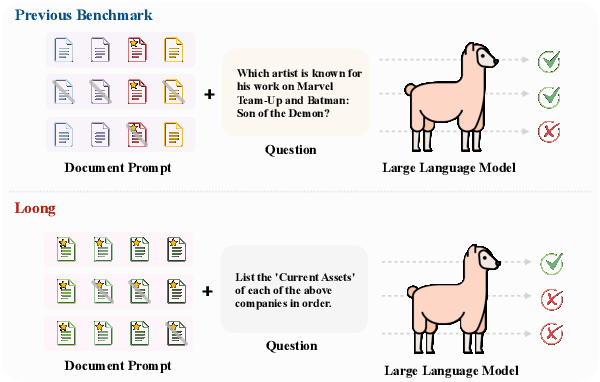
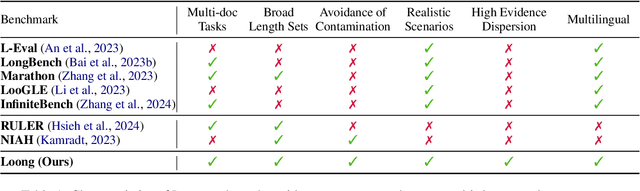
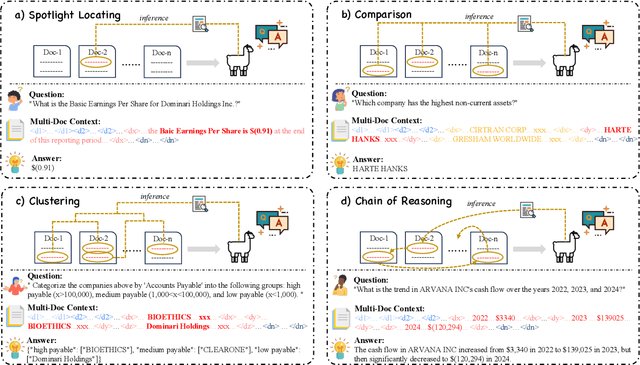

Long-context modeling capabilities have garnered widespread attention, leading to the emergence of Large Language Models (LLMs) with ultra-context windows. Meanwhile, benchmarks for evaluating long-context LLMs are gradually catching up. However, existing benchmarks employ irrelevant noise texts to artificially extend the length of test cases, diverging from the real-world scenarios of long-context applications. To bridge this gap, we propose a novel long-context benchmark, Loong, aligning with realistic scenarios through extended multi-document question answering (QA). Unlike typical document QA, in Loong's test cases, each document is relevant to the final answer, ignoring any document will lead to the failure of the answer. Furthermore, Loong introduces four types of tasks with a range of context lengths: Spotlight Locating, Comparison, Clustering, and Chain of Reasoning, to facilitate a more realistic and comprehensive evaluation of long-context understanding. Extensive experiments indicate that existing long-context language models still exhibit considerable potential for enhancement. Retrieval augmented generation (RAG) achieves poor performance, demonstrating that Loong can reliably assess the model's long-context modeling capabilities.
YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction
Jan 08, 2024The difficulty of the information extraction task lies in dealing with the task-specific label schemas and heterogeneous data structures. Recent work has proposed methods based on large language models to uniformly model different information extraction tasks. However, these existing methods are deficient in their information extraction capabilities for Chinese languages other than English. In this paper, we propose an end-to-end chat-enhanced instruction tuning framework for universal information extraction (YAYI-UIE), which supports both Chinese and English. Specifically, we utilize dialogue data and information extraction data to enhance the information extraction performance jointly. Experimental results show that our proposed framework achieves state-of-the-art performance on Chinese datasets while also achieving comparable performance on English datasets under both supervised settings and zero-shot settings.
YAYI 2: Multilingual Open-Source Large Language Models
Dec 22, 2023As the latest advancements in natural language processing, large language models (LLMs) have achieved human-level language understanding and generation abilities in many real-world tasks, and even have been regarded as a potential path to the artificial general intelligence. To better facilitate research on LLMs, many open-source LLMs, such as Llama 2 and Falcon, have recently been proposed and gained comparable performances to proprietary models. However, these models are primarily designed for English scenarios and exhibit poor performances in Chinese contexts. In this technical report, we propose YAYI 2, including both base and chat models, with 30 billion parameters. YAYI 2 is pre-trained from scratch on a multilingual corpus which contains 2.65 trillion tokens filtered by our pre-training data processing pipeline. The base model is aligned with human values through supervised fine-tuning with millions of instructions and reinforcement learning from human feedback. Extensive experiments on multiple benchmarks, such as MMLU and CMMLU, consistently demonstrate that the proposed YAYI 2 outperforms other similar sized open-source models.