 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIC: Neural Garment Deformation Field for Real-time Clothed Character Animation
Mar 26, 2026Simulating physically realistic garment deformations is an essential task for virtual immersive experience, which is often achieved by physics simulation methods. However, these methods are typically time-consuming, computationally demanding, and require costly hardware, which is not suitable for real-time applications. Recent learning-based methods tried to resolve this problem by training graph neural networks to learn the garment deformation on vertices, which, however, fail to capture the intricate deformation of complex garment meshes with complex topologies. In this paper, we introduce a novel neural deformation field-based method, named UNIC, to animate the garments of an avatar in real time, given the motion sequences. Our key idea is to learn the instance-specific neural deformation field to animate the garment meshes. Such an instance-specific learning scheme does not require UNIC to generalize to new garments but only to new motion sequences, which greatly reduces the difficulty in training and improves the deformation quality. Moreover, neural deformation fields map the 3D points to their deformation offsets, which not only avoids handling topologies of the complex garments but also injects a natural smoothness constraint in the deformation learning. Extensive experiments have been conducted on various kinds of garment meshes to demonstrate the effectiveness and efficiency of UNIC over baseline methods, making it potentially practical and useful in real-world interactive applications like video games.
GO-Renderer: Generative Object Rendering with 3D-aware Controllable Video Diffusion Models
Mar 24, 2026Reconstructing a renderable 3D model from images is a useful but challenging task. Recent feedforward 3D reconstruction methods have demonstrated remarkable success in efficiently recovering geometry, but still cannot accurately model the complex appearances of these 3D reconstructed models. Recent diffusion-based generative models can synthesize realistic images or videos of an object using reference images without explicitly modeling its appearance, which provides a promising direction for object rendering, but lacks accurate control over the viewpoints. In this paper, we propose GO-Renderer, a unified framework integrating the reconstructed 3D proxies to guide the video generative models to achieve high-quality object rendering on arbitrary viewpoints under arbitrary lighting conditions. Our method not only enjoys the accurate viewpoint control using the reconstructed 3D proxy but also enables high-quality rendering in different lighting environments using diffusion generative models without explicitly modeling complex materials and lighting. Extensive experiments demonstrate that GO-Renderer achieves state-of-the-art performance across the object rendering tasks, including synthesizing images on new viewpoints, rendering the objects in a novel lighting environment, and inserting an object into an existing video.
Track4World: Feedforward World-centric Dense 3D Tracking of All Pixels
Mar 05, 2026Estimating the 3D trajectory of every pixel from a monocular video is crucial and promising for a comprehensive understanding of the 3D dynamics of videos. Recent monocular 3D tracking works demonstrate impressive performance, but are limited to either tracking sparse points on the first frame or a slow optimization-based framework for dense tracking. In this paper, we propose a feedforward model, called Track4World, enabling an efficient holistic 3D tracking of every pixel in the world-centric coordinate system. Built on the global 3D scene representation encoded by a VGGT-style ViT, Track4World applies a novel 3D correlation scheme to simultaneously estimate the pixel-wise 2D and 3D dense flow between arbitrary frame pairs. The estimated scene flow, along with the reconstructed 3D geometry, enables subsequent efficient 3D tracking of every pixel of this video. Extensive experiments on multiple benchmarks demonstrate that our approach consistently outperforms existing methods in 2D/3D flow estimation and 3D tracking, highlighting its robustness and scalability for real-world 4D reconstruction tasks.
CoMoVi: Co-Generation of 3D Human Motions and Realistic Videos
Jan 15, 2026In this paper, we find that the generation of 3D human motions and 2D human videos is intrinsically coupled. 3D motions provide the structural prior for plausibility and consistency in videos, while pre-trained video models offer strong generalization capabilities for motions, which necessitate coupling their generation processes. Based on this, we present CoMoVi, a co-generative framework that couples two video diffusion models (VDMs) to generate 3D human motions and videos synchronously within a single diffusion denoising loop. To achieve this, we first propose an effective 2D human motion representation that can inherit the powerful prior of pre-trained VDMs. Then, we design a dual-branch diffusion model to couple human motion and video generation process with mutual feature interaction and 3D-2D cross attentions. Moreover, we curate CoMoVi Dataset, a large-scale real-world human video dataset with text and motion annotations, covering diverse and challenging human motions. Extensive experiments demonstrate the effectiveness of our method in both 3D human motion and video generation tasks.
UniSH: Unifying Scene and Human Reconstruction in a Feed-Forward Pass
Jan 03, 2026We present UniSH, a unified, feed-forward framework for joint metric-scale 3D scene and human reconstruction. A key challenge in this domain is the scarcity of large-scale, annotated real-world data, forcing a reliance on synthetic datasets. This reliance introduces a significant sim-to-real domain gap, leading to poor generalization, low-fidelity human geometry, and poor alignment on in-the-wild videos. To address this, we propose an innovative training paradigm that effectively leverages unlabeled in-the-wild data. Our framework bridges strong, disparate priors from scene reconstruction and HMR, and is trained with two core components: (1) a robust distillation strategy to refine human surface details by distilling high-frequency details from an expert depth model, and (2) a two-stage supervision scheme, which first learns coarse localization on synthetic data, then fine-tunes on real data by directly optimizing the geometric correspondence between the SMPL mesh and the human point cloud. This approach enables our feed-forward model to jointly recover high-fidelity scene geometry, human point clouds, camera parameters, and coherent, metric-scale SMPL bodies, all in a single forward pass. Extensive experiments demonstrate that our model achieves state-of-the-art performance on human-centric scene reconstruction and delivers highly competitive results on global human motion estimation, comparing favorably against both optimization-based frameworks and HMR-only methods. Project page: https://murphylmf.github.io/UniSH/
Bottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies
Dec 22, 2025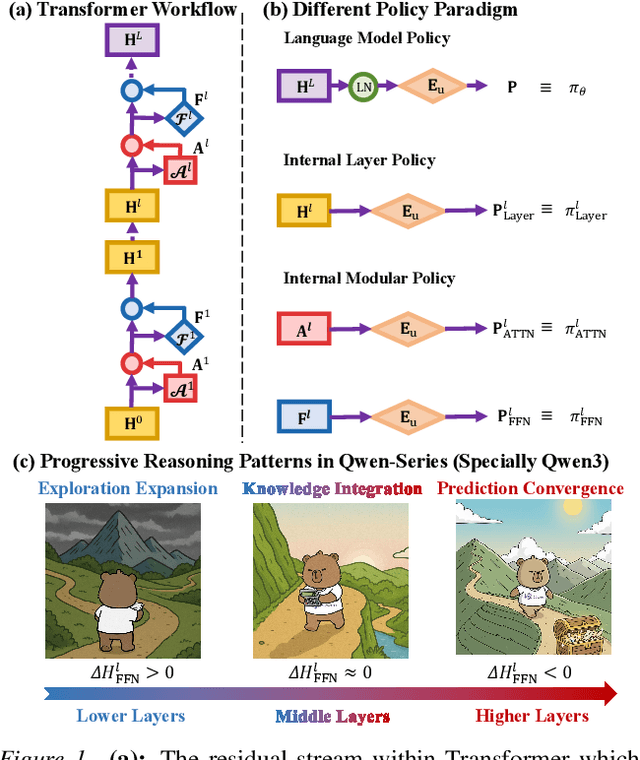
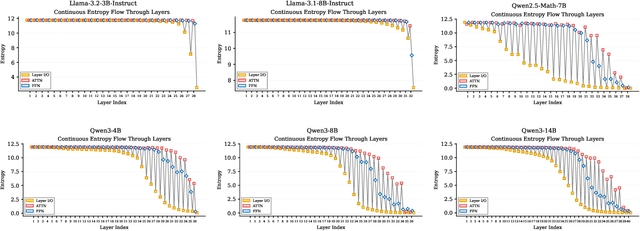
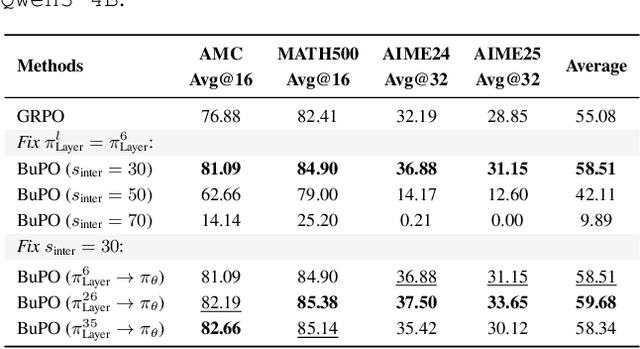
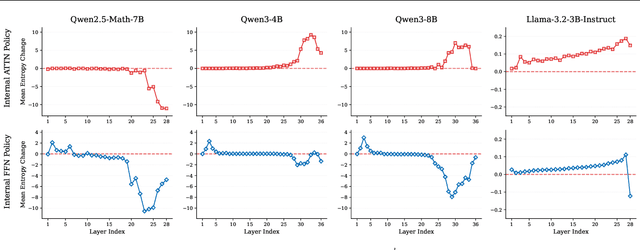
Existing reinforcement learning (RL) approaches treat large language models (LLMs) as a single unified policy, overlooking their internal mechanisms. Understanding how policy evolves across layers and modules is therefore crucial for enabling more targeted optimization and raveling out complex reasoning mechanisms. In this paper, we decompose the language model policy by leveraging the intrinsic split of the Transformer residual stream and the equivalence between the composition of hidden states with the unembedding matrix and the resulting samplable policy. This decomposition reveals Internal Layer Policies, corresponding to contributions from individual layers, and Internal Modular Policies, which align with the self-attention and feed-forward network (FFN) components within each layer. By analyzing the entropy of internal policy, we find that: (a) Early layers keep high entropy for exploration, top layers converge to near-zero entropy for refinement, with convergence patterns varying across model series. (b) LLama's prediction space rapidly converges in the final layer, whereas Qwen-series models, especially Qwen3, exhibit a more human-like, progressively structured reasoning pattern. Motivated by these findings, we propose Bottom-up Policy Optimization (BuPO), a novel RL paradigm that directly optimizes the internal layer policy during early training. By aligning training objective at lower layer, BuPO reconstructs foundational reasoning capabilities and achieves superior performance. Extensive experiments on complex reasoning benchmarks demonstrates the effectiveness of our method. Our code is available at https://github.com/Trae1ounG/BuPO.
SyncHuman: Synchronizing 2D and 3D Generative Models for Single-view Human Reconstruction
Oct 09, 2025Photorealistic 3D full-body human reconstruction from a single image is a critical yet challenging task for applications in films and video games due to inherent ambiguities and severe self-occlusions. While recent approaches leverage SMPL estimation and SMPL-conditioned image generative models to hallucinate novel views, they suffer from inaccurate 3D priors estimated from SMPL meshes and have difficulty in handling difficult human poses and reconstructing fine details. In this paper, we propose SyncHuman, a novel framework that combines 2D multiview generative model and 3D native generative model for the first time, enabling high-quality clothed human mesh reconstruction from single-view images even under challenging human poses. Multiview generative model excels at capturing fine 2D details but struggles with structural consistency, whereas 3D native generative model generates coarse yet structurally consistent 3D shapes. By integrating the complementary strengths of these two approaches, we develop a more effective generation framework. Specifically, we first jointly fine-tune the multiview generative model and the 3D native generative model with proposed pixel-aligned 2D-3D synchronization attention to produce geometrically aligned 3D shapes and 2D multiview images. To further improve details, we introduce a feature injection mechanism that lifts fine details from 2D multiview images onto the aligned 3D shapes, enabling accurate and high-fidelity reconstruction. Extensive experiments demonstrate that SyncHuman achieves robust and photo-realistic 3D human reconstruction, even for images with challenging poses. Our method outperforms baseline methods in geometric accuracy and visual fidelity, demonstrating a promising direction for future 3D generation models.
Reconstructing 4D Spatial Intelligence: A Survey
Jul 28, 2025



Reconstructing 4D spatial intelligence from visual observations has long been a central yet challenging task in computer vision, with broad real-world applications. These range from entertainment domains like movies, where the focus is often on reconstructing fundamental visual elements, to embodied AI, which emphasizes interaction modeling and physical realism. Fueled by rapid advances in 3D representations and deep learning architectures, the field has evolved quickly, outpacing the scope of previous surveys. Additionally, existing surveys rarely offer a comprehensive analysis of the hierarchical structure of 4D scene reconstruction. To address this gap, we present a new perspective that organizes existing methods into five progressive levels of 4D spatial intelligence: (1) Level 1 -- reconstruction of low-level 3D attributes (e.g., depth, pose, and point maps); (2) Level 2 -- reconstruction of 3D scene components (e.g., objects, humans, structures); (3) Level 3 -- reconstruction of 4D dynamic scenes; (4) Level 4 -- modeling of interactions among scene components; and (5) Level 5 -- incorporation of physical laws and constraints. We conclude the survey by discussing the key challenges at each level and highlighting promising directions for advancing toward even richer levels of 4D spatial intelligence. To track ongoing developments, we maintain an up-to-date project page: https://github.com/yukangcao/Awesome-4D-Spatial-Intelligence.
Mojito: LLM-Aided Motion Instructor with Jitter-Reduced Inertial Tokens
Feb 22, 2025Human bodily movements convey critical insights into action intentions and cognitive processes, yet existing multimodal systems primarily focused on understanding human motion via language, vision, and audio, which struggle to capture the dynamic forces and torques inherent in 3D motion. Inertial measurement units (IMUs) present a promising alternative, offering lightweight, wearable, and privacy-conscious motion sensing. However, processing of streaming IMU data faces challenges such as wireless transmission instability, sensor noise, and drift, limiting their utility for long-term real-time motion capture (MoCap), and more importantly, online motion analysis. To address these challenges, we introduce Mojito, an intelligent motion agent that integrates inertial sensing with large language models (LLMs) for interactive motion capture and behavioral analysis.
HOI-M3:Capture Multiple Humans and Objects Interaction within Contextual Environment
Apr 02, 2024



Humans naturally interact with both others and the surrounding multiple objects, engaging in various social activities. However, recent advances in modeling human-object interactions mostly focus on perceiving isolated individuals and objects, due to fundamental data scarcity. In this paper, we introduce HOI-M3, a novel large-scale dataset for modeling the interactions of Multiple huMans and Multiple objects. Notably, it provides accurate 3D tracking for both humans and objects from dense RGB and object-mounted IMU inputs, covering 199 sequences and 181M frames of diverse humans and objects under rich activities. With the unique HOI-M3 dataset, we introduce two novel data-driven tasks with companion strong baselines: monocular capture and unstructured generation of multiple human-object interactions. Extensive experiments demonstrate that our dataset is challenging and worthy of further research about multiple human-object interactions and behavior analysis. Our HOI-M3 dataset, corresponding codes, and pre-trained models will be disseminated to the community for future research.