 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies
Dec 22, 2025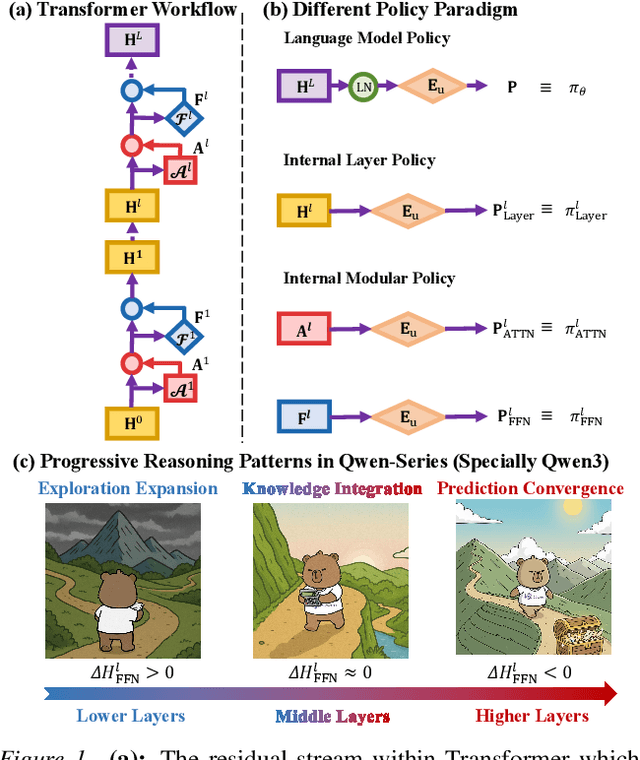
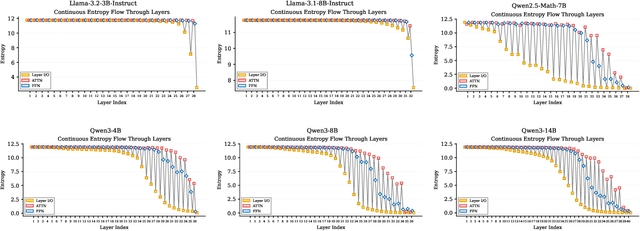
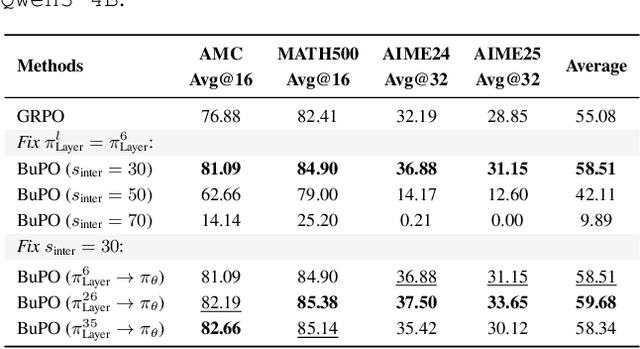
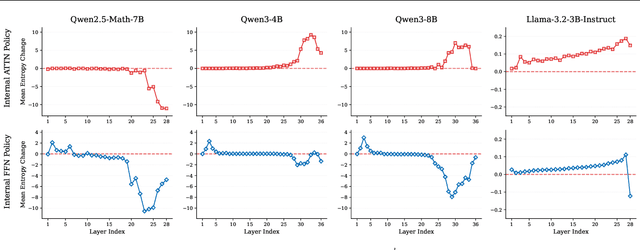
Existing reinforcement learning (RL) approaches treat large language models (LLMs) as a single unified policy, overlooking their internal mechanisms. Understanding how policy evolves across layers and modules is therefore crucial for enabling more targeted optimization and raveling out complex reasoning mechanisms. In this paper, we decompose the language model policy by leveraging the intrinsic split of the Transformer residual stream and the equivalence between the composition of hidden states with the unembedding matrix and the resulting samplable policy. This decomposition reveals Internal Layer Policies, corresponding to contributions from individual layers, and Internal Modular Policies, which align with the self-attention and feed-forward network (FFN) components within each layer. By analyzing the entropy of internal policy, we find that: (a) Early layers keep high entropy for exploration, top layers converge to near-zero entropy for refinement, with convergence patterns varying across model series. (b) LLama's prediction space rapidly converges in the final layer, whereas Qwen-series models, especially Qwen3, exhibit a more human-like, progressively structured reasoning pattern. Motivated by these findings, we propose Bottom-up Policy Optimization (BuPO), a novel RL paradigm that directly optimizes the internal layer policy during early training. By aligning training objective at lower layer, BuPO reconstructs foundational reasoning capabilities and achieves superior performance. Extensive experiments on complex reasoning benchmarks demonstrates the effectiveness of our method. Our code is available at https://github.com/Trae1ounG/BuPO.
The Zero-Step Thinking: An Empirical Study of Mode Selection as Harder Early Exit in Reasoning Models
Oct 22, 2025Reasoning models have demonstrated exceptional performance in tasks such as mathematics and logical reasoning, primarily due to their ability to engage in step-by-step thinking during the reasoning process. However, this often leads to overthinking, resulting in unnecessary computational overhead. To address this issue, Mode Selection aims to automatically decide between Long-CoT (Chain-of-Thought) or Short-CoT by utilizing either a Thinking or NoThinking mode. Simultaneously, Early Exit determines the optimal stopping point during the iterative reasoning process. Both methods seek to reduce the computational burden. In this paper, we first identify Mode Selection as a more challenging variant of the Early Exit problem, as they share similar objectives but differ in decision timing. While Early Exit focuses on determining the best stopping point for concise reasoning at inference time, Mode Selection must make this decision at the beginning of the reasoning process, relying on pre-defined fake thoughts without engaging in an explicit reasoning process, referred to as zero-step thinking. Through empirical studies on nine baselines, we observe that prompt-based approaches often fail due to their limited classification capabilities when provided with minimal hand-crafted information. In contrast, approaches that leverage internal information generally perform better across most scenarios but still exhibit issues with stability. Our findings indicate that existing methods relying solely on the information provided by models are insufficient for effectively addressing Mode Selection in scenarios with limited information, highlighting the ongoing challenges of this task. Our code is available at https://github.com/Trae1ounG/Zero_Step_Thinking.
Neural Incompatibility: The Unbridgeable Gap of Cross-Scale Parametric Knowledge Transfer in Large Language Models
May 20, 2025



Large Language Models (LLMs) offer a transparent brain with accessible parameters that encode extensive knowledge, which can be analyzed, located and transferred. Consequently, a key research challenge is to transcend traditional knowledge transfer paradigms rooted in symbolic language and achieve genuine Parametric Knowledge Transfer (PKT). Significantly, exploring effective methods for transferring knowledge across LLMs of different scales through parameters presents an intriguing and valuable research direction. In this paper, we first demonstrate $\textbf{Alignment}$ in parametric space is the fundamental prerequisite to achieve successful cross-scale PKT. We redefine the previously explored knowledge transfer as Post-Align PKT (PostPKT), which utilizes extracted parameters for LoRA initialization and requires subsequent fine-tune for alignment. Hence, to reduce cost for further fine-tuning, we introduce a novel Pre-Align PKT (PrePKT) paradigm and propose a solution called $\textbf{LaTen}$ ($\textbf{L}$oc$\textbf{a}$te-$\textbf{T}$h$\textbf{e}$n-Alig$\textbf{n}$) that aligns the parametric spaces of LLMs across scales only using several training steps without following training. Comprehensive experiments on four benchmarks demonstrate that both PostPKT and PrePKT face challenges in achieving consistently stable transfer. Through in-depth analysis, we identify $\textbf{Neural Incompatibility}$ as the ethological and parametric structural differences between LLMs of varying scales, presenting fundamental challenges to achieving effective PKT. These findings provide fresh insights into the parametric architectures of LLMs and highlight promising directions for future research on efficient PKT. Our code is available at https://github.com/Trae1ounG/Neural_Incompatibility.
Better wit than wealth: Dynamic Parametric Retrieval Augmented Generation for Test-time Knowledge Enhancement
Mar 31, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) by retrieving relevant documents from external sources and incorporating them into the context. While it improves reliability by providing factual texts, it significantly increases inference costs as context length grows and introduces challenging issue of RAG hallucination, primarily caused by the lack of corresponding parametric knowledge in LLMs. An efficient solution is to enhance the knowledge of LLMs at test-time. Parametric RAG (PRAG) addresses this by embedding document into LLMs parameters to perform test-time knowledge enhancement, effectively reducing inference costs through offline training. However, its high training and storage costs, along with limited generalization ability, significantly restrict its practical adoption. To address these challenges, we propose Dynamic Parametric RAG (DyPRAG), a novel framework that leverages a lightweight parameter translator model to efficiently convert documents into parametric knowledge. DyPRAG not only reduces inference, training, and storage costs but also dynamically generates parametric knowledge, seamlessly enhancing the knowledge of LLMs and resolving knowledge conflicts in a plug-and-play manner at test-time. Extensive experiments on multiple datasets demonstrate the effectiveness and generalization capabilities of DyPRAG, offering a powerful and practical RAG paradigm which enables superior knowledge fusion and mitigates RAG hallucination in real-world applications. Our code is available at https://github.com/Trae1ounG/DyPRAG.
MuAP: Multi-step Adaptive Prompt Learning for Vision-Language Model with Missing Modality
Sep 07, 2024



Recently, prompt learning has garnered considerable attention for its success in various Vision-Language (VL) tasks. However, existing prompt-based models are primarily focused on studying prompt generation and prompt strategies with complete modality settings, which does not accurately reflect real-world scenarios where partial modality information may be missing. In this paper, we present the first comprehensive investigation into prompt learning behavior when modalities are incomplete, revealing the high sensitivity of prompt-based models to missing modalities. To this end, we propose a novel Multi-step Adaptive Prompt Learning (MuAP) framework, aiming to generate multimodal prompts and perform multi-step prompt tuning, which adaptively learns knowledge by iteratively aligning modalities. Specifically, we generate multimodal prompts for each modality and devise prompt strategies to integrate them into the Transformer model. Subsequently, we sequentially perform prompt tuning from single-stage and alignment-stage, allowing each modality-prompt to be autonomously and adaptively learned, thereby mitigating the imbalance issue caused by only textual prompts that are learnable in previous works. Extensive experiments demonstrate the effectiveness of our MuAP and this model achieves significant improvements compared to the state-of-the-art on all benchmark datasets
G-SAP: Graph-based Structure-Aware Prompt Learning over Heterogeneous Knowledge for Commonsense Reasoning
May 09, 2024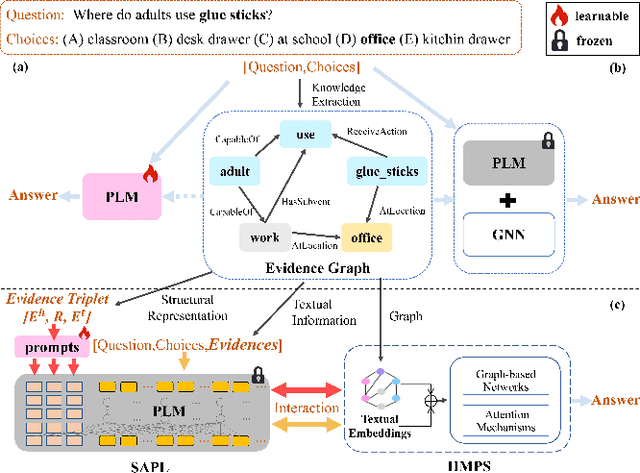
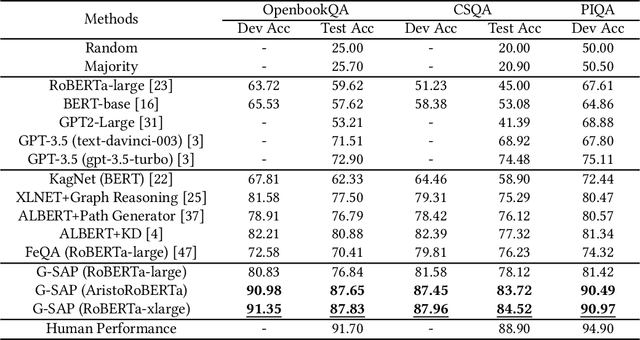
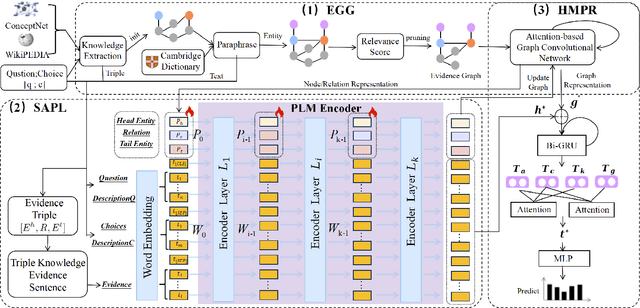
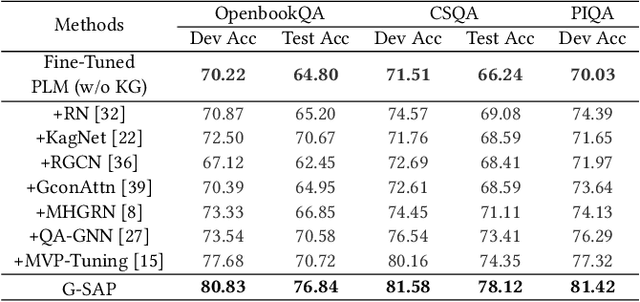
Commonsense question answering has demonstrated considerable potential across various applications like assistants and social robots. Although fully fine-tuned pre-trained Language Models(LM) have achieved remarkable performance in commonsense reasoning, their tendency to excessively prioritize textual information hampers the precise transfer of structural knowledge and undermines interpretability. Some studies have explored combining LMs with Knowledge Graphs(KGs) by coarsely fusing the two modalities to perform Graph Neural Network(GNN)-based reasoning that lacks a profound interaction between heterogeneous modalities. In this paper, we propose a novel Graph-based Structure-Aware Prompt Learning Model for commonsense reasoning, named G-SAP, aiming to maintain a balance between heterogeneous knowledge and enhance the cross-modal interaction within the LM+GNNs model. In particular, an evidence graph is constructed by integrating multiple knowledge sources, i.e. ConceptNet, Wikipedia, and Cambridge Dictionary to boost the performance. Afterward, a structure-aware frozen PLM is employed to fully incorporate the structured and textual information from the evidence graph, where the generation of prompts is driven by graph entities and relations. Finally, a heterogeneous message-passing reasoning module is used to facilitate deep interaction of knowledge between the LM and graph-based networks. Empirical validation, conducted through extensive experiments on three benchmark datasets, demonstrates the notable performance of the proposed model. The results reveal a significant advancement over the existing models, especially, with 6.12% improvement over the SoTA LM+GNNs model on the OpenbookQA dataset.