 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMba-UNet: Synergizing SAM2 and Mamba in UNet with Heterogeneous Aggregation for Cardiac MRI Segmentation
May 22, 2025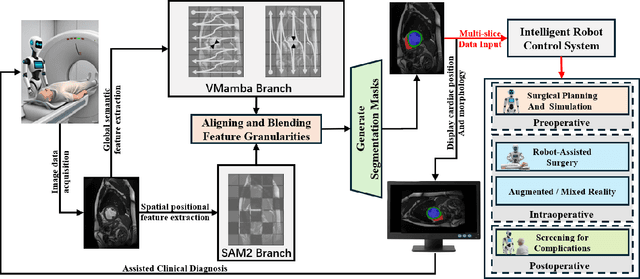



To address the challenge of complex pathological feature extraction in automated cardiac MRI segmentation, this study proposes an innovative dual-encoder architecture named SAMba-UNet. The framework achieves cross-modal feature collaborative learning by integrating the vision foundation model SAM2, the state-space model Mamba, and the classical UNet. To mitigate domain discrepancies between medical and natural images, a Dynamic Feature Fusion Refiner is designed, which enhances small lesion feature extraction through multi-scale pooling and a dual-path calibration mechanism across channel and spatial dimensions. Furthermore, a Heterogeneous Omni-Attention Convergence Module (HOACM) is introduced, combining global contextual attention with branch-selective emphasis mechanisms to effectively fuse SAM2's local positional semantics and Mamba's long-range dependency modeling capabilities. Experiments on the ACDC cardiac MRI dataset demonstrate that the proposed model achieves a Dice coefficient of 0.9103 and an HD95 boundary error of 1.0859 mm, significantly outperforming existing methods, particularly in boundary localization for complex pathological structures such as right ventricular anomalies. This work provides an efficient and reliable solution for automated cardiac disease diagnosis, and the code will be open-sourced.
DMS-Net:Dual-Modal Multi-Scale Siamese Network for Binocular Fundus Image Classification
Apr 25, 2025Ophthalmic diseases pose a significant global health challenge, yet traditional diagnosis methods and existing single-eye deep learning approaches often fail to account for binocular pathological correlations. To address this, we propose DMS-Net, a dual-modal multi-scale Siamese network for binocular fundus image classification. Our framework leverages weight-shared Siamese ResNet-152 backbones to extract deep semantic features from paired fundus images. To tackle challenges such as lesion boundary ambiguity and scattered pathological distributions, we introduce a Multi-Scale Context-Aware Module (MSCAM) that integrates adaptive pooling and attention mechanisms for multi-resolution feature aggregation. Additionally, a Dual-Modal Feature Fusion (DMFF) module enhances cross-modal interaction through spatial-semantic recalibration and bidirectional attention, effectively combining global context and local edge features. Evaluated on the ODIR-5K dataset, DMS-Net achieves state-of-the-art performance with 80.5% accuracy, 86.1% recall, and 83.8% Cohen's kappa, demonstrating superior capability in detecting symmetric pathologies and advancing clinical decision-making for ocular diseases.
FE-UNet: Frequency Domain Enhanced U-Net with Segment Anything Capability for Versatile Image Segmentation
Feb 06, 2025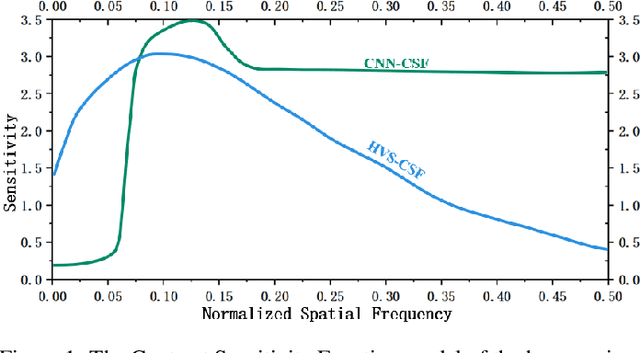

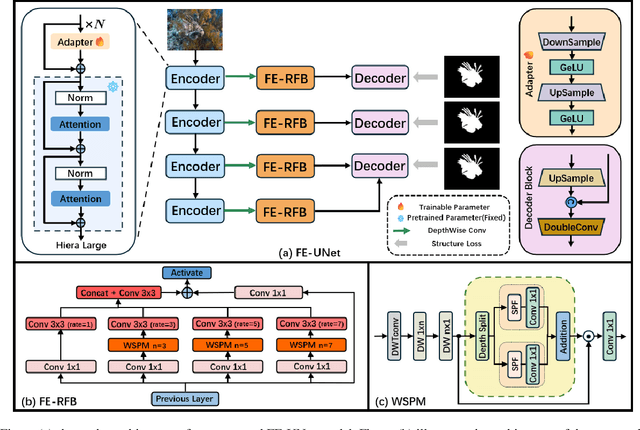

Image segmentation is a critical task in visual understanding. Convolutional Neural Networks (CNNs) are predisposed to capture high-frequency features in images, while Transformers exhibit a contrasting focus on low-frequency features. In this paper, we experimentally quantify the contrast sensitivity function of CNNs and compare it with that of the human visual system, informed by the seminal experiments of Mannos and Sakrison. Leveraging these insights, we propose the Wavelet-Guided Spectral Pooling Module (WSPM) to enhance and balance image features across the frequency domain. To further emulate the human visual system, we introduce the Frequency Domain Enhanced Receptive Field Block (FE-RFB), which integrates WSPM to extract enriched features from the frequency domain. Building on these innovations, we develop FE-UNet, a model that utilizes SAM2 as its backbone and incorporates Hiera-Large as a pre-trained block, designed to enhance generalization capabilities while ensuring high segmentation accuracy. Experimental results demonstrate that FE-UNet achieves state-of-the-art performance in diverse tasks, including marine animal and polyp segmentation, underscoring its versatility and effectiveness.
G-SAP: Graph-based Structure-Aware Prompt Learning over Heterogeneous Knowledge for Commonsense Reasoning
May 09, 2024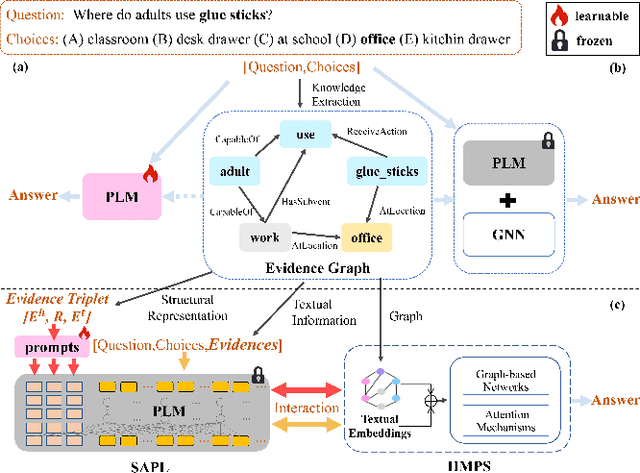
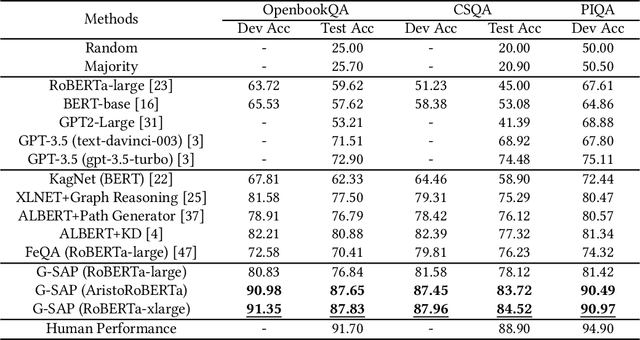
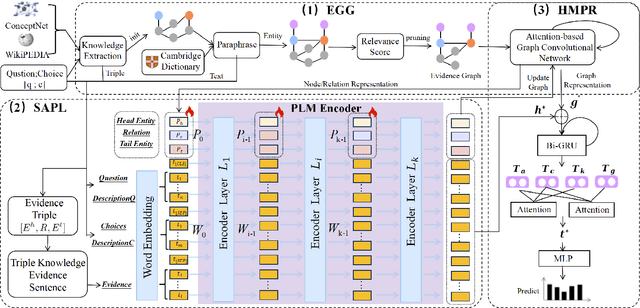
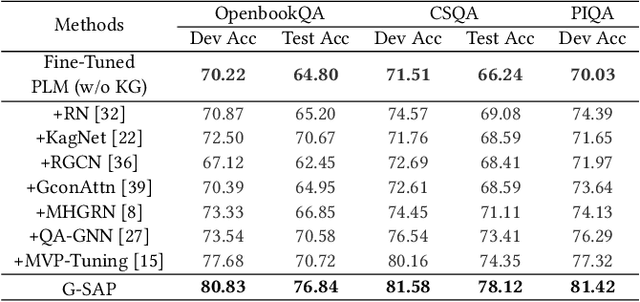
Commonsense question answering has demonstrated considerable potential across various applications like assistants and social robots. Although fully fine-tuned pre-trained Language Models(LM) have achieved remarkable performance in commonsense reasoning, their tendency to excessively prioritize textual information hampers the precise transfer of structural knowledge and undermines interpretability. Some studies have explored combining LMs with Knowledge Graphs(KGs) by coarsely fusing the two modalities to perform Graph Neural Network(GNN)-based reasoning that lacks a profound interaction between heterogeneous modalities. In this paper, we propose a novel Graph-based Structure-Aware Prompt Learning Model for commonsense reasoning, named G-SAP, aiming to maintain a balance between heterogeneous knowledge and enhance the cross-modal interaction within the LM+GNNs model. In particular, an evidence graph is constructed by integrating multiple knowledge sources, i.e. ConceptNet, Wikipedia, and Cambridge Dictionary to boost the performance. Afterward, a structure-aware frozen PLM is employed to fully incorporate the structured and textual information from the evidence graph, where the generation of prompts is driven by graph entities and relations. Finally, a heterogeneous message-passing reasoning module is used to facilitate deep interaction of knowledge between the LM and graph-based networks. Empirical validation, conducted through extensive experiments on three benchmark datasets, demonstrates the notable performance of the proposed model. The results reveal a significant advancement over the existing models, especially, with 6.12% improvement over the SoTA LM+GNNs model on the OpenbookQA dataset.