 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Graph Condensation via Classification Complexity Mitigation
Oct 30, 2025Graph condensation (GC) has gained significant attention for its ability to synthesize smaller yet informative graphs. However, existing studies often overlook the robustness of GC in scenarios where the original graph is corrupted. In such cases, we observe that the performance of GC deteriorates significantly, while existing robust graph learning technologies offer only limited effectiveness. Through both empirical investigation and theoretical analysis, we reveal that GC is inherently an intrinsic-dimension-reducing process, synthesizing a condensed graph with lower classification complexity. Although this property is critical for effective GC performance, it remains highly vulnerable to adversarial perturbations. To tackle this vulnerability and improve GC robustness, we adopt the geometry perspective of graph data manifold and propose a novel Manifold-constrained Robust Graph Condensation framework named MRGC. Specifically, we introduce three graph data manifold learning modules that guide the condensed graph to lie within a smooth, low-dimensional manifold with minimal class ambiguity, thereby preserving the classification complexity reduction capability of GC and ensuring robust performance under universal adversarial attacks. Extensive experiments demonstrate the robustness of \ModelName\ across diverse attack scenarios.
Robust Graph Learning Against Adversarial Evasion Attacks via Prior-Free Diffusion-Based Structure Purification
Feb 07, 2025Adversarial evasion attacks pose significant threats to graph learning, with lines of studies that have improved the robustness of Graph Neural Networks (GNNs). However, existing works rely on priors about clean graphs or attacking strategies, which are often heuristic and inconsistent. To achieve robust graph learning over different types of evasion attacks and diverse datasets, we investigate this problem from a prior-free structure purification perspective. Specifically, we propose a novel Diffusion-based Structure Purification framework named DiffSP, which creatively incorporates the graph diffusion model to learn intrinsic distributions of clean graphs and purify the perturbed structures by removing adversaries under the direction of the captured predictive patterns without relying on priors. DiffSP is divided into the forward diffusion process and the reverse denoising process, during which structure purification is achieved. To avoid valuable information loss during the forward process, we propose an LID-driven nonisotropic diffusion mechanism to selectively inject noise anisotropically. To promote semantic alignment between the clean graph and the purified graph generated during the reverse process, we reduce the generation uncertainty by the proposed graph transfer entropy guided denoising mechanism. Extensive experiments demonstrate the superior robustness of DiffSP against evasion attacks.
G-SAP: Graph-based Structure-Aware Prompt Learning over Heterogeneous Knowledge for Commonsense Reasoning
May 09, 2024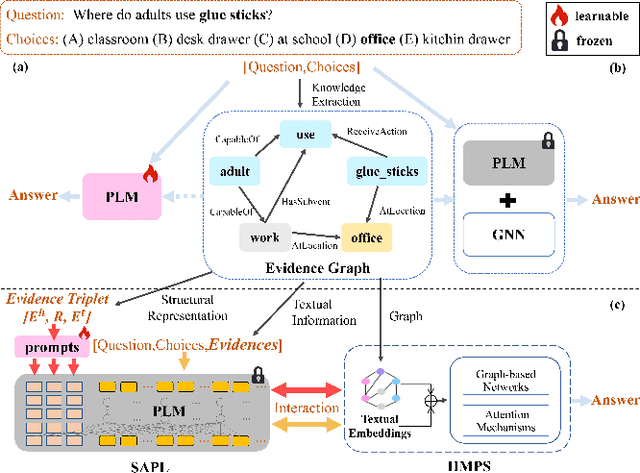
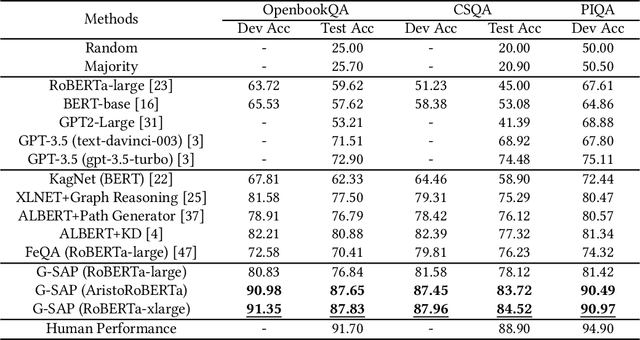
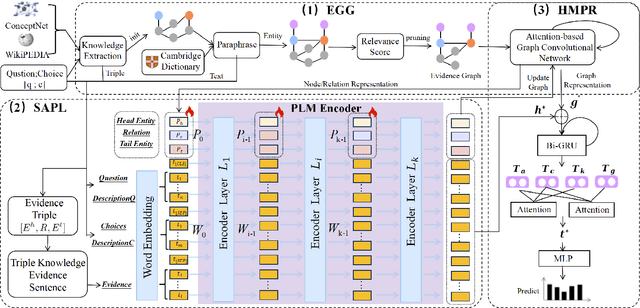
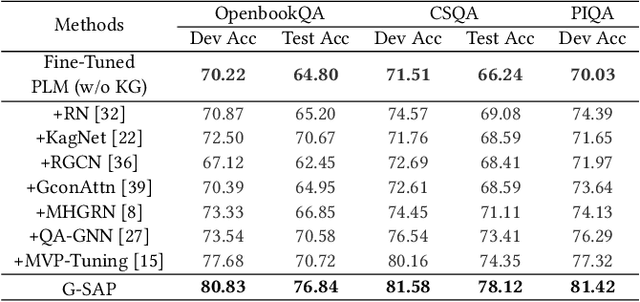
Commonsense question answering has demonstrated considerable potential across various applications like assistants and social robots. Although fully fine-tuned pre-trained Language Models(LM) have achieved remarkable performance in commonsense reasoning, their tendency to excessively prioritize textual information hampers the precise transfer of structural knowledge and undermines interpretability. Some studies have explored combining LMs with Knowledge Graphs(KGs) by coarsely fusing the two modalities to perform Graph Neural Network(GNN)-based reasoning that lacks a profound interaction between heterogeneous modalities. In this paper, we propose a novel Graph-based Structure-Aware Prompt Learning Model for commonsense reasoning, named G-SAP, aiming to maintain a balance between heterogeneous knowledge and enhance the cross-modal interaction within the LM+GNNs model. In particular, an evidence graph is constructed by integrating multiple knowledge sources, i.e. ConceptNet, Wikipedia, and Cambridge Dictionary to boost the performance. Afterward, a structure-aware frozen PLM is employed to fully incorporate the structured and textual information from the evidence graph, where the generation of prompts is driven by graph entities and relations. Finally, a heterogeneous message-passing reasoning module is used to facilitate deep interaction of knowledge between the LM and graph-based networks. Empirical validation, conducted through extensive experiments on three benchmark datasets, demonstrates the notable performance of the proposed model. The results reveal a significant advancement over the existing models, especially, with 6.12% improvement over the SoTA LM+GNNs model on the OpenbookQA dataset.
Multi-modal Representation Learning for Social Post Location Inference
Jun 11, 2023Inferring geographic locations via social posts is essential for many practical location-based applications such as product marketing, point-of-interest recommendation, and infector tracking for COVID-19. Unlike image-based location retrieval or social-post text embedding-based location inference, the combined effect of multi-modal information (i.e., post images, text, and hashtags) for social post positioning receives less attention. In this work, we collect real datasets of social posts with images, texts, and hashtags from Instagram and propose a novel Multi-modal Representation Learning Framework (MRLF) capable of fusing different modalities of social posts for location inference. MRLF integrates a multi-head attention mechanism to enhance location-salient information extraction while significantly improving location inference compared with single domain-based methods. To overcome the noisy user-generated textual content, we introduce a novel attention-based character-aware module that considers the relative dependencies between characters of social post texts and hashtags for flexible multi-model information fusion. The experimental results show that MRLF can make accurate location predictions and open a new door to understanding the multi-modal data of social posts for online inference tasks.