 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Representation Learning for Social Post Location Inference
Jun 11, 2023Inferring geographic locations via social posts is essential for many practical location-based applications such as product marketing, point-of-interest recommendation, and infector tracking for COVID-19. Unlike image-based location retrieval or social-post text embedding-based location inference, the combined effect of multi-modal information (i.e., post images, text, and hashtags) for social post positioning receives less attention. In this work, we collect real datasets of social posts with images, texts, and hashtags from Instagram and propose a novel Multi-modal Representation Learning Framework (MRLF) capable of fusing different modalities of social posts for location inference. MRLF integrates a multi-head attention mechanism to enhance location-salient information extraction while significantly improving location inference compared with single domain-based methods. To overcome the noisy user-generated textual content, we introduce a novel attention-based character-aware module that considers the relative dependencies between characters of social post texts and hashtags for flexible multi-model information fusion. The experimental results show that MRLF can make accurate location predictions and open a new door to understanding the multi-modal data of social posts for online inference tasks.
CNNTOP: a CNN-based Trajectory Owner Prediction Method
Jan 05, 2020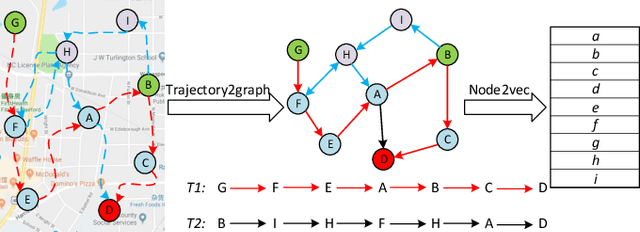
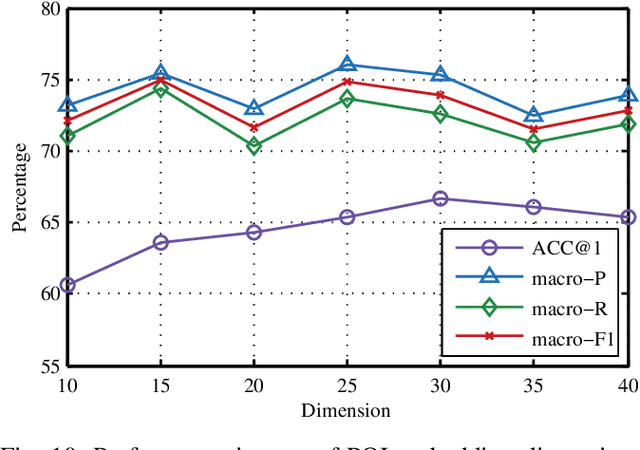
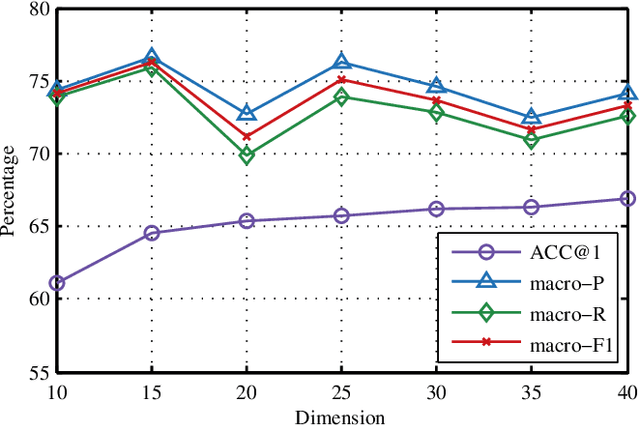
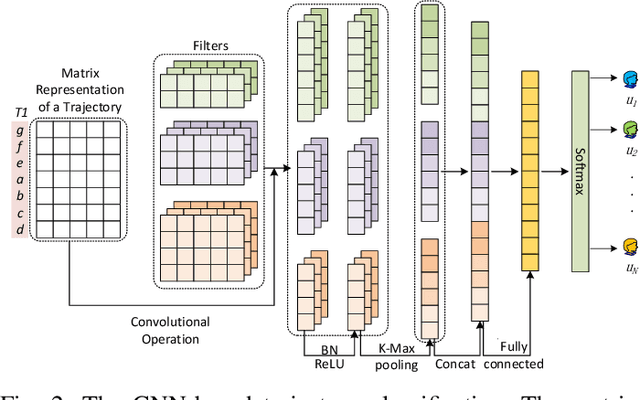
Trajectory owner prediction is the basis for many applications such as personalized recommendation, urban planning. Although much effort has been put on this topic, the results archived are still not good enough. Existing methods mainly employ RNNs to model trajectories semantically due to the inherent sequential attribute of trajectories. However, these approaches are weak at Point of Interest (POI) representation learning and trajectory feature detection. Thus, the performance of existing solutions is far from the requirements of practical applications. In this paper, we propose a novel CNN-based Trajectory Owner Prediction (CNNTOP) method. Firstly, we connect all POI according to trajectories from all users. The result is a connected graph that can be used to generate more informative POI sequences than other approaches. Secondly, we employ the Node2Vec algorithm to encode each POI into a low-dimensional real value vector. Then, we transform each trajectory into a fixed-dimensional matrix, which is similar to an image. Finally, a CNN is designed to detect features and predict the owner of a given trajectory. The CNN can extract informative features from the matrix representations of trajectories by convolutional operations, Batch normalization, and $K$-max pooling operations. Extensive experiments on real datasets demonstrate that CNNTOP substantially outperforms existing solutions in terms of macro-Precision, macro-Recall, macro-F1, and accuracy.