 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVOREFUSE: Evolutionary Prompt Optimization for Evaluation and Mitigation of LLM Over-Refusal to Pseudo-Malicious Instructions
May 29, 2025



Large language models (LLMs) frequently refuse to respond to pseudo-malicious instructions: semantically harmless input queries triggering unnecessary LLM refusals due to conservative safety alignment, significantly impairing user experience. Collecting such instructions is crucial for evaluating and mitigating over-refusals, but existing instruction curation methods, like manual creation or instruction rewriting, either lack scalability or fail to produce sufficiently diverse and effective refusal-inducing prompts. To address these limitations, we introduce EVOREFUSE, a prompt optimization approach that generates diverse pseudo-malicious instructions consistently eliciting confident refusals across LLMs. EVOREFUSE employs an evolutionary algorithm exploring the instruction space in more diverse directions than existing methods via mutation strategies and recombination, and iteratively evolves seed instructions to maximize evidence lower bound on LLM refusal probability. Using EVOREFUSE, we create two novel datasets: EVOREFUSE-TEST, a benchmark of 582 pseudo-malicious instructions that outperforms the next-best benchmark with 140.41% higher average refusal triggering rate across 9 LLMs, 34.86% greater lexical diversity, and 40.03% improved LLM response confidence scores; and EVOREFUSE-ALIGN, which provides 3,000 pseudo-malicious instructions with responses for supervised and preference-based alignment training. LLAMA3.1-8B-INSTRUCT supervisedly fine-tuned on EVOREFUSE-ALIGN achieves up to 14.31% fewer over-refusals than models trained on the second-best alignment dataset, without compromising safety. Our analysis with EVOREFUSE-TEST reveals models trigger over-refusals by overly focusing on sensitive keywords while ignoring broader context.
NeRF-VINS: A Real-time Neural Radiance Field Map-based Visual-Inertial Navigation System
Sep 17, 2023



Achieving accurate, efficient, and consistent localization within an a priori environment map remains a fundamental challenge in robotics and computer vision. Conventional map-based keyframe localization often suffers from sub-optimal viewpoints due to limited field of view (FOV), thus degrading its performance. To address this issue, in this paper, we design a real-time tightly-coupled Neural Radiance Fields (NeRF)-aided visual-inertial navigation system (VINS), termed NeRF-VINS. By effectively leveraging NeRF's potential to synthesize novel views, essential for addressing limited viewpoints, the proposed NeRF-VINS optimally fuses IMU and monocular image measurements along with synthetically rendered images within an efficient filter-based framework. This tightly coupled integration enables 3D motion tracking with bounded error. We extensively compare the proposed NeRF-VINS against the state-of-the-art methods that use prior map information, which is shown to achieve superior performance. We also demonstrate the proposed method is able to perform real-time estimation at 15 Hz, on a resource-constrained Jetson AGX Orin embedded platform with impressive accuracy.
Differentiable Analog Quantum Computing for Optimization and Control
Oct 28, 2022
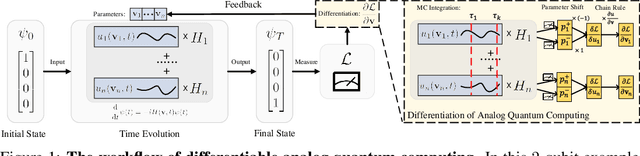
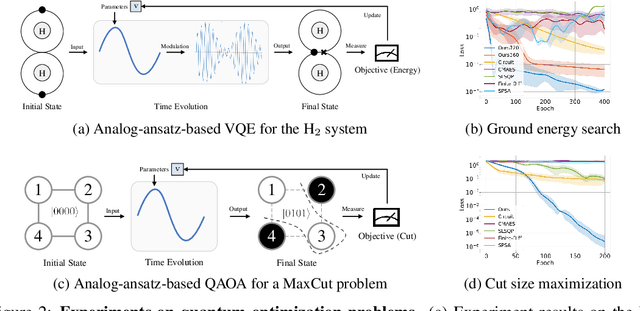
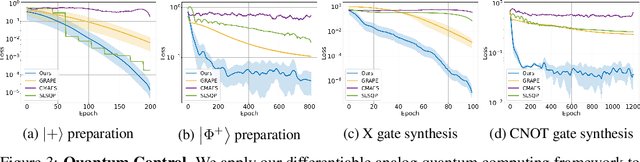
We formulate the first differentiable analog quantum computing framework with a specific parameterization design at the analog signal (pulse) level to better exploit near-term quantum devices via variational methods. We further propose a scalable approach to estimate the gradients of quantum dynamics using a forward pass with Monte Carlo sampling, which leads to a quantum stochastic gradient descent algorithm for scalable gradient-based training in our framework. Applying our framework to quantum optimization and control, we observe a significant advantage of differentiable analog quantum computing against SOTAs based on parameterized digital quantum circuits by orders of magnitude.
* Code available at https://github.com/YilingQiao/diffquantum
CNNTOP: a CNN-based Trajectory Owner Prediction Method
Jan 05, 2020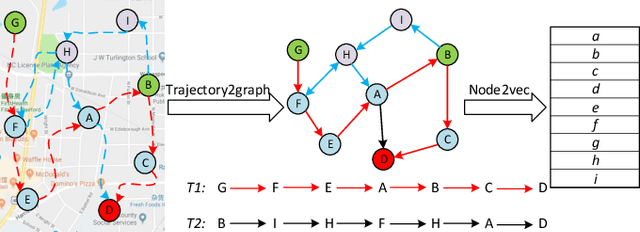
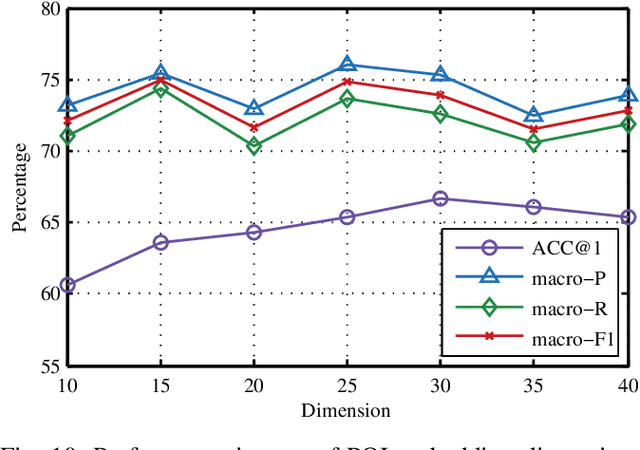
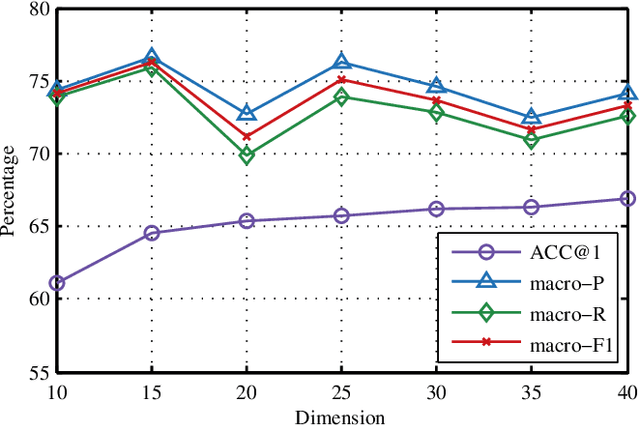
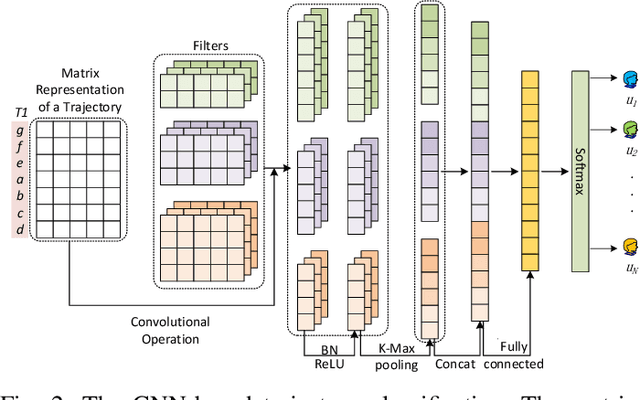
Trajectory owner prediction is the basis for many applications such as personalized recommendation, urban planning. Although much effort has been put on this topic, the results archived are still not good enough. Existing methods mainly employ RNNs to model trajectories semantically due to the inherent sequential attribute of trajectories. However, these approaches are weak at Point of Interest (POI) representation learning and trajectory feature detection. Thus, the performance of existing solutions is far from the requirements of practical applications. In this paper, we propose a novel CNN-based Trajectory Owner Prediction (CNNTOP) method. Firstly, we connect all POI according to trajectories from all users. The result is a connected graph that can be used to generate more informative POI sequences than other approaches. Secondly, we employ the Node2Vec algorithm to encode each POI into a low-dimensional real value vector. Then, we transform each trajectory into a fixed-dimensional matrix, which is similar to an image. Finally, a CNN is designed to detect features and predict the owner of a given trajectory. The CNN can extract informative features from the matrix representations of trajectories by convolutional operations, Batch normalization, and $K$-max pooling operations. Extensive experiments on real datasets demonstrate that CNNTOP substantially outperforms existing solutions in terms of macro-Precision, macro-Recall, macro-F1, and accuracy.
Cascaded Pyramid Network for Multi-Person Pose Estimation
Apr 08, 2018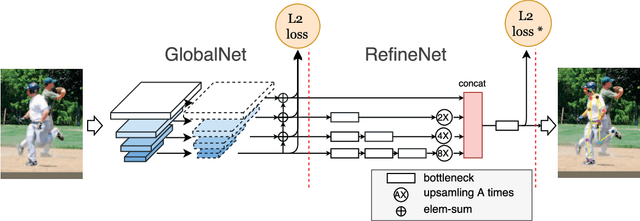
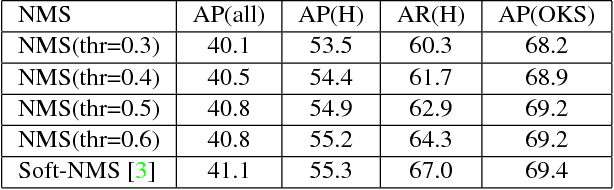
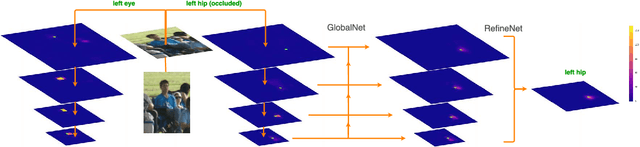
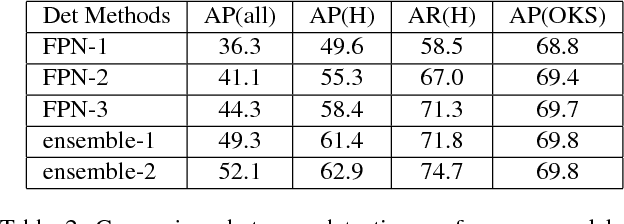
The topic of multi-person pose estimation has been largely improved recently, especially with the development of convolutional neural network. However, there still exist a lot of challenging cases, such as occluded keypoints, invisible keypoints and complex background, which cannot be well addressed. In this paper, we present a novel network structure called Cascaded Pyramid Network (CPN) which targets to relieve the problem from these "hard" keypoints. More specifically, our algorithm includes two stages: GlobalNet and RefineNet. GlobalNet is a feature pyramid network which can successfully localize the "simple" keypoints like eyes and hands but may fail to precisely recognize the occluded or invisible keypoints. Our RefineNet tries explicitly handling the "hard" keypoints by integrating all levels of feature representations from the GlobalNet together with an online hard keypoint mining loss. In general, to address the multi-person pose estimation problem, a top-down pipeline is adopted to first generate a set of human bounding boxes based on a detector, followed by our CPN for keypoint localization in each human bounding box. Based on the proposed algorithm, we achieve state-of-art results on the COCO keypoint benchmark, with average precision at 73.0 on the COCO test-dev dataset and 72.1 on the COCO test-challenge dataset, which is a 19% relative improvement compared with 60.5 from the COCO 2016 keypoint challenge.Code (https://github.com/chenyilun95/tf-cpn.git) and the detection results are publicly available for further research.