 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Quantum Computing for Large-scale Linear Control
Nov 03, 2024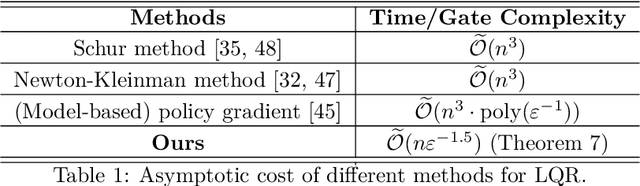
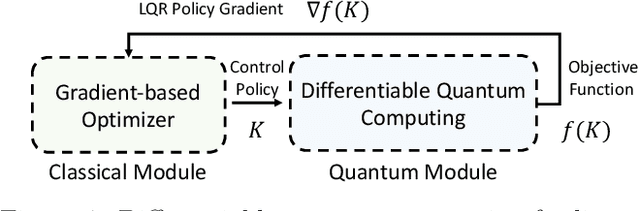
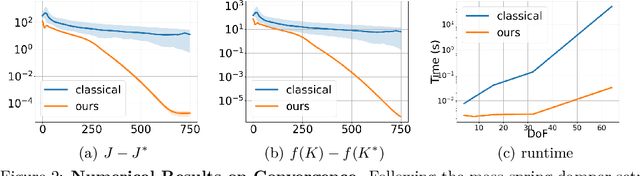
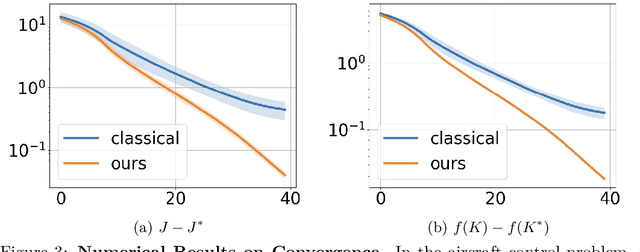
As industrial models and designs grow increasingly complex, the demand for optimal control of large-scale dynamical systems has significantly increased. However, traditional methods for optimal control incur significant overhead as problem dimensions grow. In this paper, we introduce an end-to-end quantum algorithm for linear-quadratic control with provable speedups. Our algorithm, based on a policy gradient method, incorporates a novel quantum subroutine for solving the matrix Lyapunov equation. Specifically, we build a quantum-assisted differentiable simulator for efficient gradient estimation that is more accurate and robust than classical methods relying on stochastic approximation. Compared to the classical approaches, our method achieves a super-quadratic speedup. To the best of our knowledge, this is the first end-to-end quantum application to linear control problems with provable quantum advantage.
A quantum-classical performance separation in nonconvex optimization
Nov 01, 2023



In this paper, we identify a family of nonconvex continuous optimization instances, each $d$-dimensional instance with $2^d$ local minima, to demonstrate a quantum-classical performance separation. Specifically, we prove that the recently proposed Quantum Hamiltonian Descent (QHD) algorithm [Leng et al., arXiv:2303.01471] is able to solve any $d$-dimensional instance from this family using $\widetilde{\mathcal{O}}(d^3)$ quantum queries to the function value and $\widetilde{\mathcal{O}}(d^4)$ additional 1-qubit and 2-qubit elementary quantum gates. On the other side, a comprehensive empirical study suggests that representative state-of-the-art classical optimization algorithms/solvers (including Gurobi) would require a super-polynomial time to solve such optimization instances.
Analyzing Convergence in Quantum Neural Networks: Deviations from Neural Tangent Kernels
Mar 26, 2023



A quantum neural network (QNN) is a parameterized mapping efficiently implementable on near-term Noisy Intermediate-Scale Quantum (NISQ) computers. It can be used for supervised learning when combined with classical gradient-based optimizers. Despite the existing empirical and theoretical investigations, the convergence of QNN training is not fully understood. Inspired by the success of the neural tangent kernels (NTKs) in probing into the dynamics of classical neural networks, a recent line of works proposes to study over-parameterized QNNs by examining a quantum version of tangent kernels. In this work, we study the dynamics of QNNs and show that contrary to popular belief it is qualitatively different from that of any kernel regression: due to the unitarity of quantum operations, there is a non-negligible deviation from the tangent kernel regression derived at the random initialization. As a result of the deviation, we prove the at-most sublinear convergence for QNNs with Pauli measurements, which is beyond the explanatory power of any kernel regression dynamics. We then present the actual dynamics of QNNs in the limit of over-parameterization. The new dynamics capture the change of convergence rate during training and implies that the range of measurements is crucial to the fast QNN convergence.
Quantum Hamiltonian Descent
Mar 02, 2023



Gradient descent is a fundamental algorithm in both theory and practice for continuous optimization. Identifying its quantum counterpart would be appealing to both theoretical and practical quantum applications. A conventional approach to quantum speedups in optimization relies on the quantum acceleration of intermediate steps of classical algorithms, while keeping the overall algorithmic trajectory and solution quality unchanged. We propose Quantum Hamiltonian Descent (QHD), which is derived from the path integral of dynamical systems referring to the continuous-time limit of classical gradient descent algorithms, as a truly quantum counterpart of classical gradient methods where the contribution from classically-prohibited trajectories can significantly boost QHD's performance for non-convex optimization. Moreover, QHD is described as a Hamiltonian evolution efficiently simulatable on both digital and analog quantum computers. By embedding the dynamics of QHD into the evolution of the so-called Quantum Ising Machine (including D-Wave and others), we empirically observe that the D-Wave-implemented QHD outperforms a selection of state-of-the-art gradient-based classical solvers and the standard quantum adiabatic algorithm, based on the time-to-solution metric, on non-convex constrained quadratic programming instances up to 75 dimensions. Finally, we propose a "three-phase picture" to explain the behavior of QHD, especially its difference from the quantum adiabatic algorithm.
Differentiable Quantum Programming with Unbounded Loops
Nov 08, 2022The emergence of variational quantum applications has led to the development of automatic differentiation techniques in quantum computing. Recently, Zhu et al. (PLDI 2020) have formulated differentiable quantum programming with bounded loops, providing a framework for scalable gradient calculation by quantum means for training quantum variational applications. However, promising parameterized quantum applications, e.g., quantum walk and unitary implementation, cannot be trained in the existing framework due to the natural involvement of unbounded loops. To fill in the gap, we provide the first differentiable quantum programming framework with unbounded loops, including a newly designed differentiation rule, code transformation, and their correctness proof. Technically, we introduce a randomized estimator for derivatives to deal with the infinite sum in the differentiation of unbounded loops, whose applicability in classical and probabilistic programming is also discussed. We implement our framework with Python and Q#, and demonstrate a reasonable sample efficiency. Through extensive case studies, we showcase an exciting application of our framework in automatically identifying close-to-optimal parameters for several parameterized quantum applications.
Differentiable Analog Quantum Computing for Optimization and Control
Oct 28, 2022
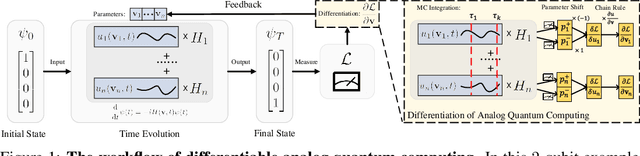
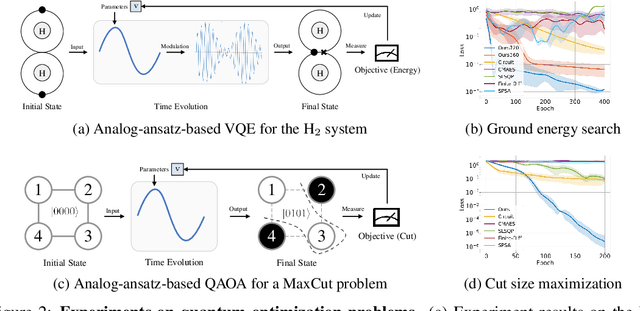
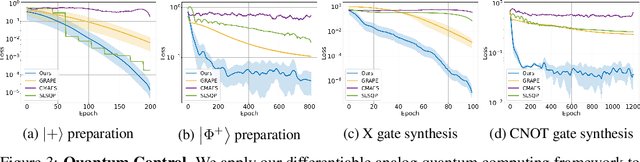
We formulate the first differentiable analog quantum computing framework with a specific parameterization design at the analog signal (pulse) level to better exploit near-term quantum devices via variational methods. We further propose a scalable approach to estimate the gradients of quantum dynamics using a forward pass with Monte Carlo sampling, which leads to a quantum stochastic gradient descent algorithm for scalable gradient-based training in our framework. Applying our framework to quantum optimization and control, we observe a significant advantage of differentiable analog quantum computing against SOTAs based on parameterized digital quantum circuits by orders of magnitude.
* Code available at https://github.com/YilingQiao/diffquantum
A Convergence Theory for Over-parameterized Variational Quantum Eigensolvers
May 25, 2022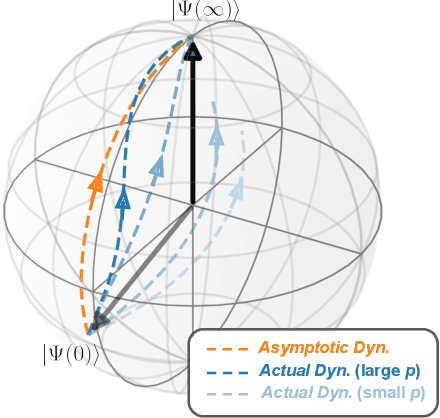
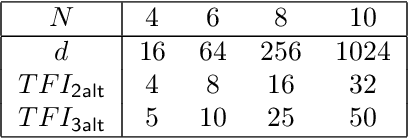

The Variational Quantum Eigensolver (VQE) is a promising candidate for quantum applications on near-term Noisy Intermediate-Scale Quantum (NISQ) computers. Despite a lot of empirical studies and recent progress in theoretical understanding of VQE's optimization landscape, the convergence for optimizing VQE is far less understood. We provide the first rigorous analysis of the convergence of VQEs in the over-parameterization regime. By connecting the training dynamics with the Riemannian Gradient Flow on the unit-sphere, we establish a threshold on the sufficient number of parameters for efficient convergence, which depends polynomially on the system dimension and the spectral ratio, a property of the problem Hamiltonian, and could be resilient to gradient noise to some extent. We further illustrate that this overparameterization threshold could be vastly reduced for specific VQE instances by establishing an ansatz-dependent threshold paralleling our main result. We showcase that our ansatz-dependent threshold could serve as a proxy of the trainability of different VQE ansatzes without performing empirical experiments, which hence leads to a principled way of evaluating ansatz design. Finally, we conclude with a comprehensive empirical study that supports our theoretical findings.
Exponentially Many Local Minima in Quantum Neural Networks
Oct 06, 2021



Quantum Neural Networks (QNNs), or the so-called variational quantum circuits, are important quantum applications both because of their similar promises as classical neural networks and because of the feasibility of their implementation on near-term intermediate-size noisy quantum machines (NISQ). However, the training task of QNNs is challenging and much less understood. We conduct a quantitative investigation on the landscape of loss functions of QNNs and identify a class of simple yet extremely hard QNN instances for training. Specifically, we show for typical under-parameterized QNNs, there exists a dataset that induces a loss function with the number of spurious local minima depending exponentially on the number of parameters. Moreover, we show the optimality of our construction by providing an almost matching upper bound on such dependence. While local minima in classical neural networks are due to non-linear activations, in quantum neural networks local minima appear as a result of the quantum interference phenomenon. Finally, we empirically confirm that our constructions can indeed be hard instances in practice with typical gradient-based optimizers, which demonstrates the practical value of our findings.
* 27 pages, 10 figures
Sublinear classical and quantum algorithms for general matrix games
Dec 11, 2020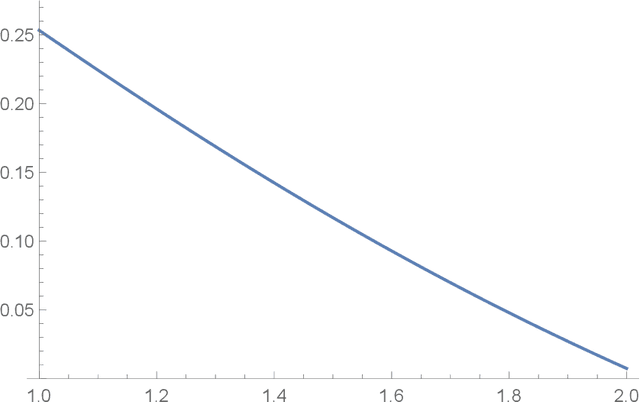
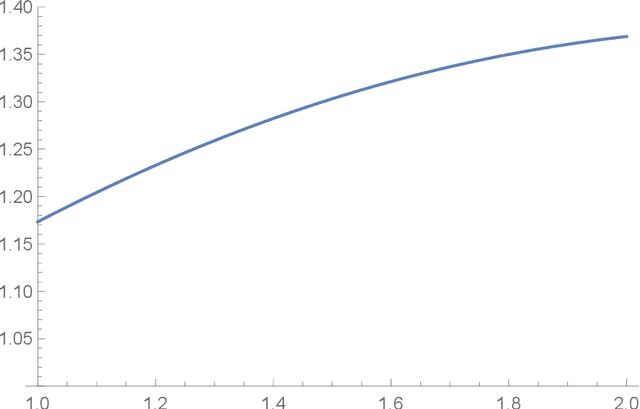
We investigate sublinear classical and quantum algorithms for matrix games, a fundamental problem in optimization and machine learning, with provable guarantees. Given a matrix $A\in\mathbb{R}^{n\times d}$, sublinear algorithms for the matrix game $\min_{x\in\mathcal{X}}\max_{y\in\mathcal{Y}} y^{\top} Ax$ were previously known only for two special cases: (1) $\mathcal{Y}$ being the $\ell_{1}$-norm unit ball, and (2) $\mathcal{X}$ being either the $\ell_{1}$- or the $\ell_{2}$-norm unit ball. We give a sublinear classical algorithm that can interpolate smoothly between these two cases: for any fixed $q\in (1,2]$, we solve the matrix game where $\mathcal{X}$ is a $\ell_{q}$-norm unit ball within additive error $\epsilon$ in time $\tilde{O}((n+d)/{\epsilon^{2}})$. We also provide a corresponding sublinear quantum algorithm that solves the same task in time $\tilde{O}((\sqrt{n}+\sqrt{d})\textrm{poly}(1/\epsilon))$ with a quadratic improvement in both $n$ and $d$. Both our classical and quantum algorithms are optimal in the dimension parameters $n$ and $d$ up to poly-logarithmic factors. Finally, we propose sublinear classical and quantum algorithms for the approximate Carath\'eodory problem and the $\ell_{q}$-margin support vector machines as applications.
On the Principles of Differentiable Quantum Programming Languages
Apr 02, 2020



Variational Quantum Circuits (VQCs), or the so-called quantum neural-networks, are predicted to be one of the most important near-term quantum applications, not only because of their similar promises as classical neural-networks, but also because of their feasibility on near-term noisy intermediate-size quantum (NISQ) machines. The need for gradient information in the training procedure of VQC applications has stimulated the development of auto-differentiation techniques for quantum circuits. We propose the first formalization of this technique, not only in the context of quantum circuits but also for imperative quantum programs (e.g., with controls), inspired by the success of differentiable programming languages in classical machine learning. In particular, we overcome a few unique difficulties caused by exotic quantum features (such as quantum no-cloning) and provide a rigorous formulation of differentiation applied to bounded-loop imperative quantum programs, its code-transformation rules, as well as a sound logic to reason about their correctness. Moreover, we have implemented our code transformation in OCaml and demonstrated the resource-efficiency of our scheme both analytically and empirically. We also conduct a case study of training a VQC instance with controls, which shows the advantage of our scheme over existing auto-differentiation for quantum circuits without controls.