 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Convergence in Quantum Neural Networks: Deviations from Neural Tangent Kernels
Mar 26, 2023



A quantum neural network (QNN) is a parameterized mapping efficiently implementable on near-term Noisy Intermediate-Scale Quantum (NISQ) computers. It can be used for supervised learning when combined with classical gradient-based optimizers. Despite the existing empirical and theoretical investigations, the convergence of QNN training is not fully understood. Inspired by the success of the neural tangent kernels (NTKs) in probing into the dynamics of classical neural networks, a recent line of works proposes to study over-parameterized QNNs by examining a quantum version of tangent kernels. In this work, we study the dynamics of QNNs and show that contrary to popular belief it is qualitatively different from that of any kernel regression: due to the unitarity of quantum operations, there is a non-negligible deviation from the tangent kernel regression derived at the random initialization. As a result of the deviation, we prove the at-most sublinear convergence for QNNs with Pauli measurements, which is beyond the explanatory power of any kernel regression dynamics. We then present the actual dynamics of QNNs in the limit of over-parameterization. The new dynamics capture the change of convergence rate during training and implies that the range of measurements is crucial to the fast QNN convergence.
A Convergence Theory for Over-parameterized Variational Quantum Eigensolvers
May 25, 2022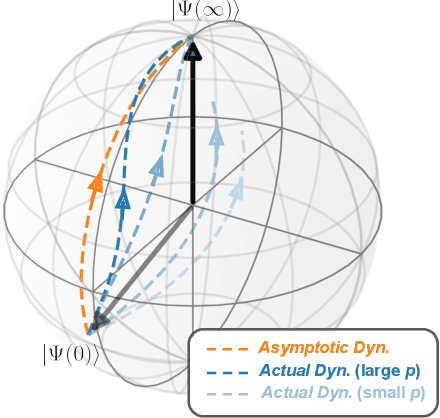

The Variational Quantum Eigensolver (VQE) is a promising candidate for quantum applications on near-term Noisy Intermediate-Scale Quantum (NISQ) computers. Despite a lot of empirical studies and recent progress in theoretical understanding of VQE's optimization landscape, the convergence for optimizing VQE is far less understood. We provide the first rigorous analysis of the convergence of VQEs in the over-parameterization regime. By connecting the training dynamics with the Riemannian Gradient Flow on the unit-sphere, we establish a threshold on the sufficient number of parameters for efficient convergence, which depends polynomially on the system dimension and the spectral ratio, a property of the problem Hamiltonian, and could be resilient to gradient noise to some extent. We further illustrate that this overparameterization threshold could be vastly reduced for specific VQE instances by establishing an ansatz-dependent threshold paralleling our main result. We showcase that our ansatz-dependent threshold could serve as a proxy of the trainability of different VQE ansatzes without performing empirical experiments, which hence leads to a principled way of evaluating ansatz design. Finally, we conclude with a comprehensive empirical study that supports our theoretical findings.
Exponentially Many Local Minima in Quantum Neural Networks
Oct 06, 2021



Quantum Neural Networks (QNNs), or the so-called variational quantum circuits, are important quantum applications both because of their similar promises as classical neural networks and because of the feasibility of their implementation on near-term intermediate-size noisy quantum machines (NISQ). However, the training task of QNNs is challenging and much less understood. We conduct a quantitative investigation on the landscape of loss functions of QNNs and identify a class of simple yet extremely hard QNN instances for training. Specifically, we show for typical under-parameterized QNNs, there exists a dataset that induces a loss function with the number of spurious local minima depending exponentially on the number of parameters. Moreover, we show the optimality of our construction by providing an almost matching upper bound on such dependence. While local minima in classical neural networks are due to non-linear activations, in quantum neural networks local minima appear as a result of the quantum interference phenomenon. Finally, we empirically confirm that our constructions can indeed be hard instances in practice with typical gradient-based optimizers, which demonstrates the practical value of our findings.
* 27 pages, 10 figures
Quantum exploration algorithms for multi-armed bandits
Jul 14, 2020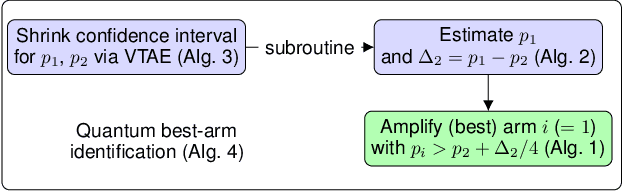
Identifying the best arm of a multi-armed bandit is a central problem in bandit optimization. We study a quantum computational version of this problem with coherent oracle access to states encoding the reward probabilities of each arm as quantum amplitudes. Specifically, we show that we can find the best arm with fixed confidence using $\tilde{O}\bigl(\sqrt{\sum_{i=2}^n\Delta^{\smash{-2}}_i}\bigr)$ quantum queries, where $\Delta_{i}$ represents the difference between the mean reward of the best arm and the $i^\text{th}$-best arm. This algorithm, based on variable-time amplitude amplification and estimation, gives a quadratic speedup compared to the best possible classical result. We also prove a matching quantum lower bound (up to poly-logarithmic factors).
Second-Order Group Influence Functions for Black-Box Predictions
Nov 01, 2019
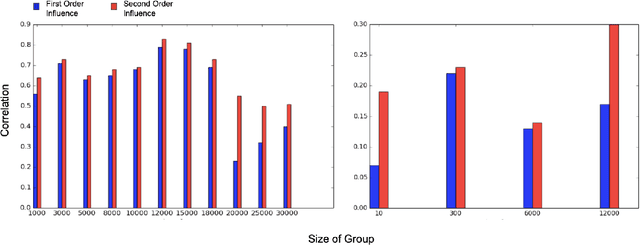

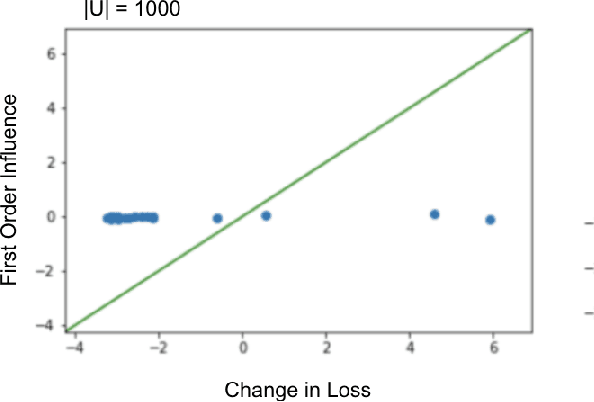
With the rapid adoption of machine learning systems in sensitive applications, there is an increasing need to make black-box models explainable. Often we want to identify an influential group of training samples in a particular test prediction. Existing influence functions tackle this problem by using first-order approximations of the effect of removing a sample from the training set on model parameters. To compute the influence of a group of training samples (rather than an individual point) in model predictions, the change in optimal model parameters after removing that group from the training set can be large. Thus, in such cases, the first-order approximation can be loose. In this paper, we address this issue and propose second-order influence functions for identifying influential groups in test-time predictions. For linear models and across different sizes of groups, we show that using the proposed second-order influence function improves the correlation between the computed influence values and the ground truth ones. For nonlinear models based on neural networks, we empirically show that none of the existing first-order and the proposed second-order influence functions provide proper estimates of the ground-truth influences over all training samples. We empirically study this phenomenon by decomposing the influence values over contributions from different eigenvectors of the Hessian of the trained model.